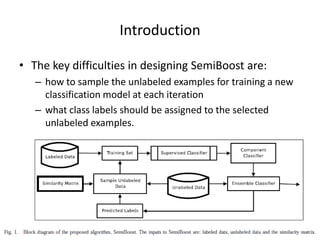
SemiBoost is a boosting algorithm for semi-supervised learning that utilizes both labeled and unlabeled data. It works by iteratively selecting the most confidently labeled unlabeled examples based on pairwise similarities, assigning labels, and training a classifier. The algorithm aims to minimize inconsistencies between labeled examples and unlabeled example labels implied by similarities. It formulates the problem as optimizing an objective function balancing these inconsistencies. Experimental results show SemiBoost improves classification accuracy over other semi-supervised and supervised methods on benchmark datasets.