アジェンダ
半教師あり深層学習の最先端の手法を紹介します
DeepGenerative Models
– Semi-supervised learning with deep generative models (Kingma et al., 2014)
– Improving Semi-Supervised Learning with Auxiliary Deep Generative Models
(Maaloe et al., 2015)
Virtual Adversarial Training
– Distributional smoothing with virtual adversarial training (Miyato et al., 2015)
Ladder Networks (これをメインに)
– Semi-supervised learning with Ladder network (Rasmus et al., 2015)
– Deconstructing the ladder network architecture (Mohammad et al., 2016)
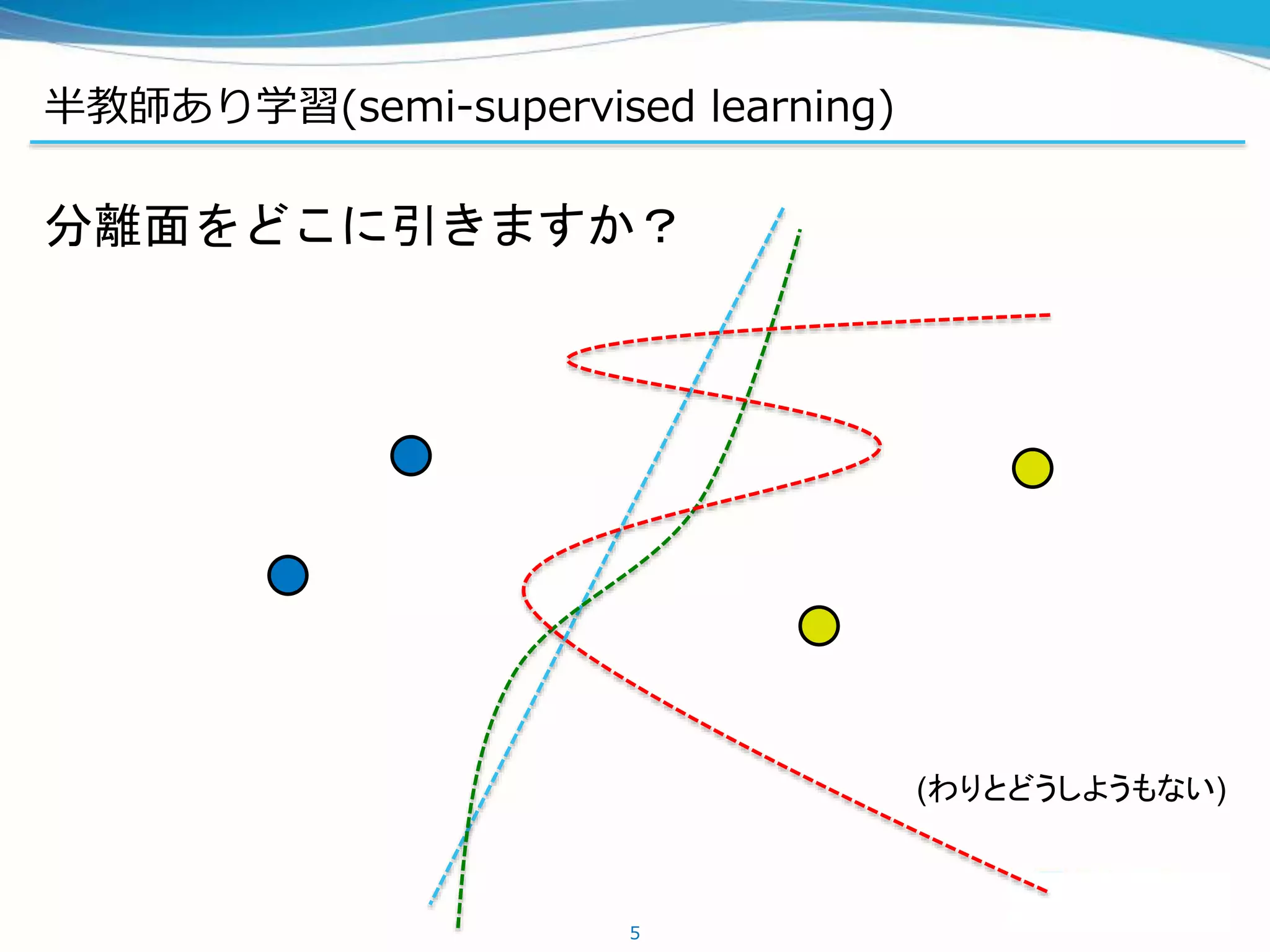
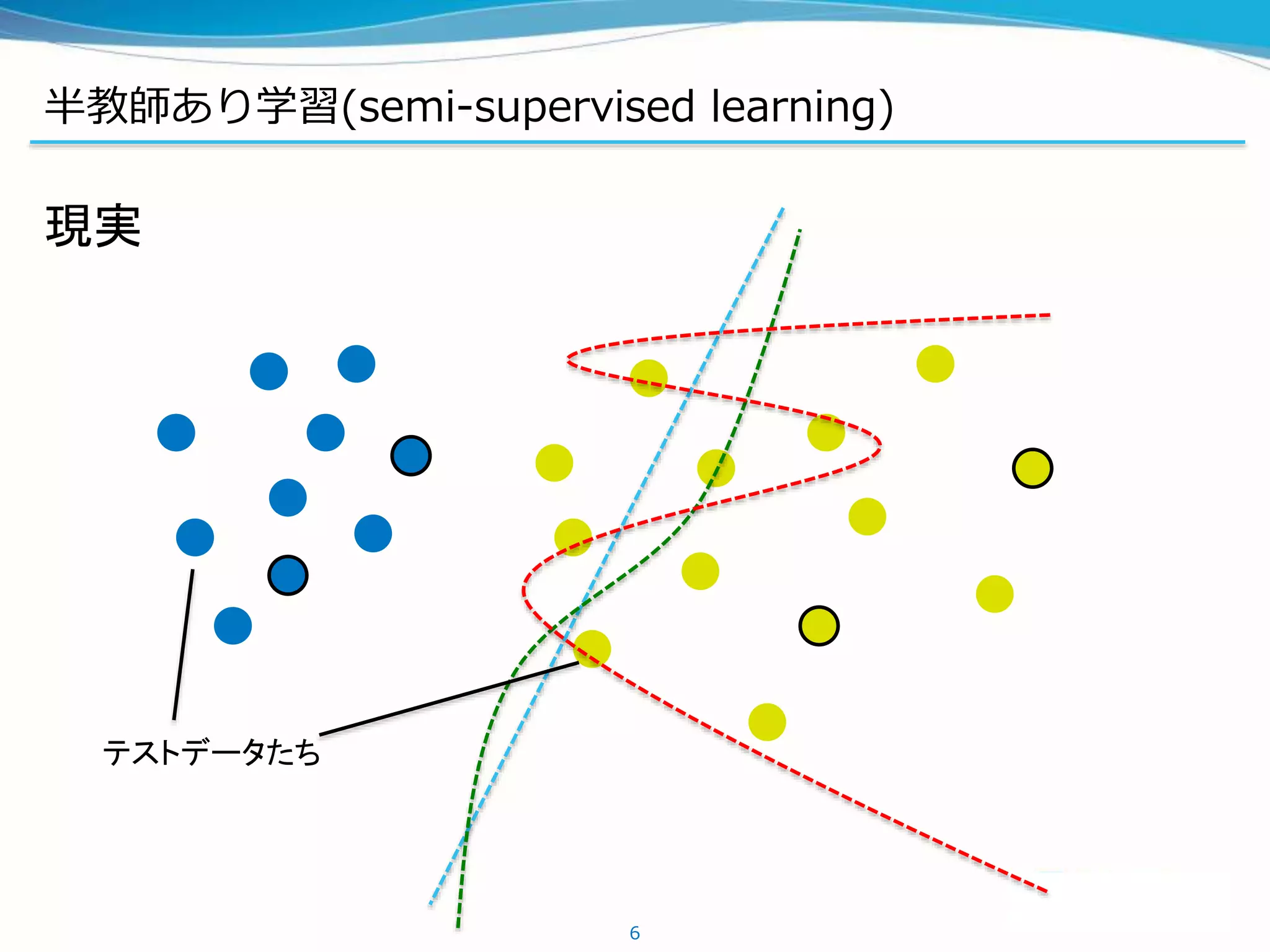
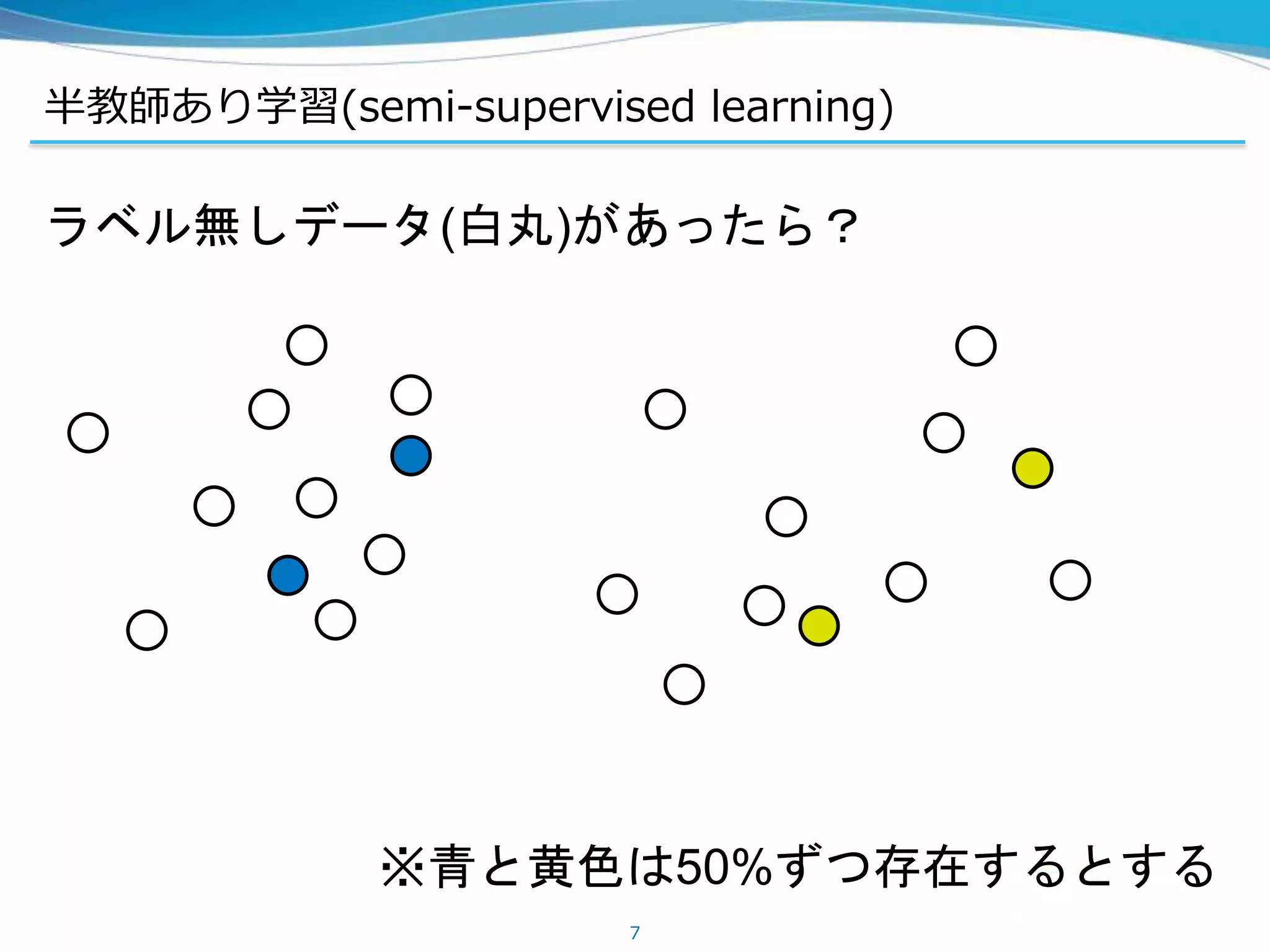
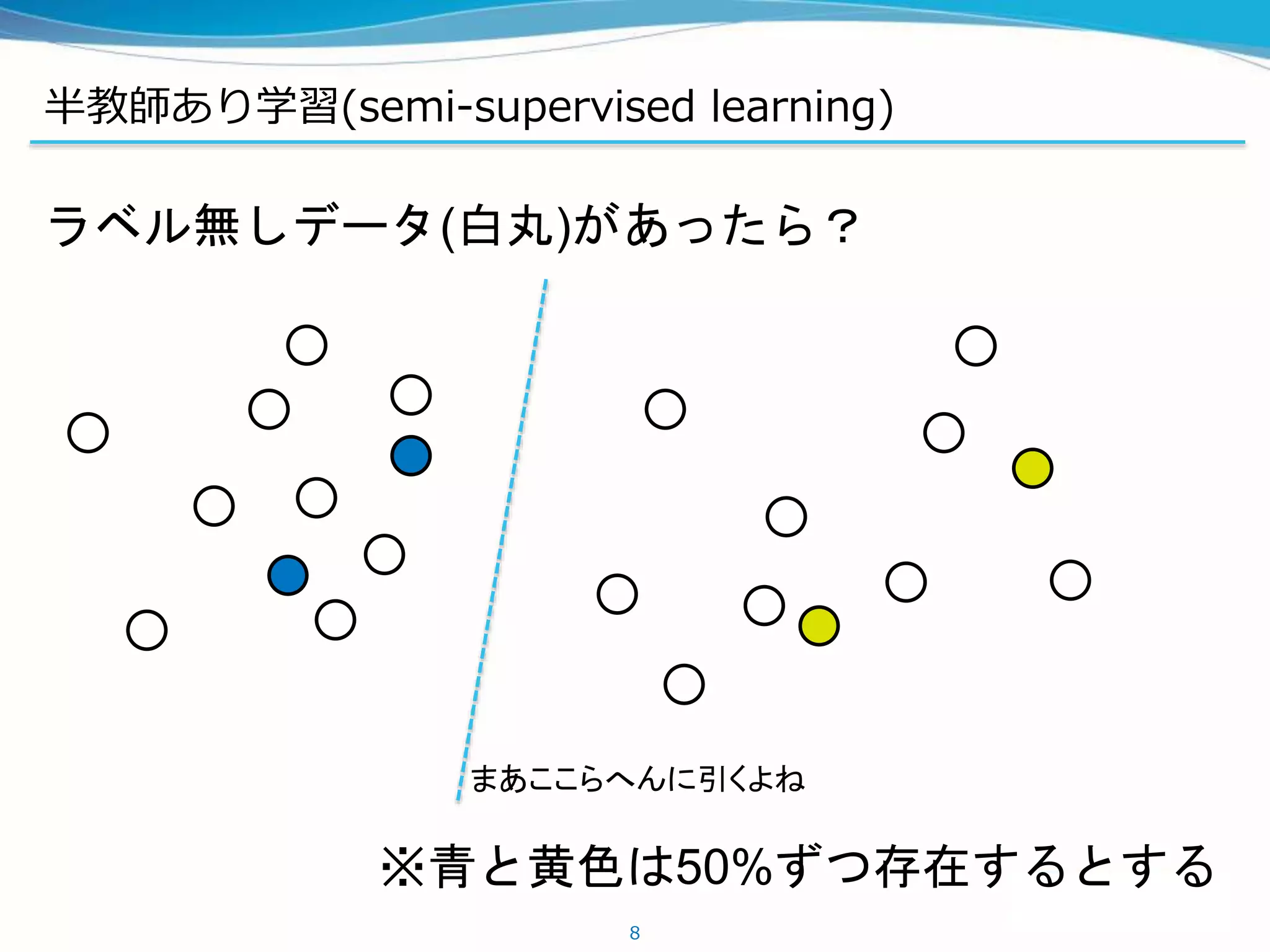
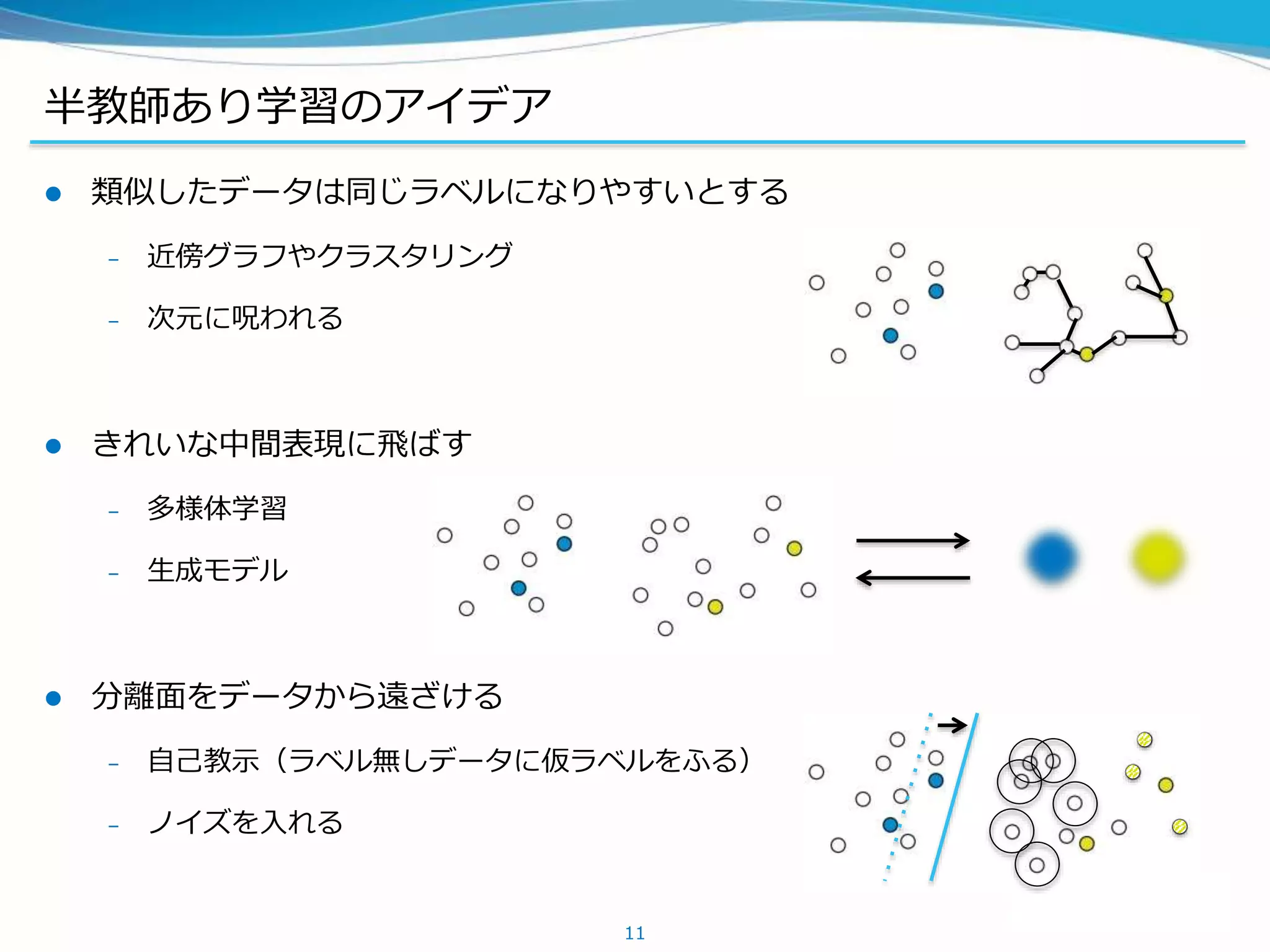
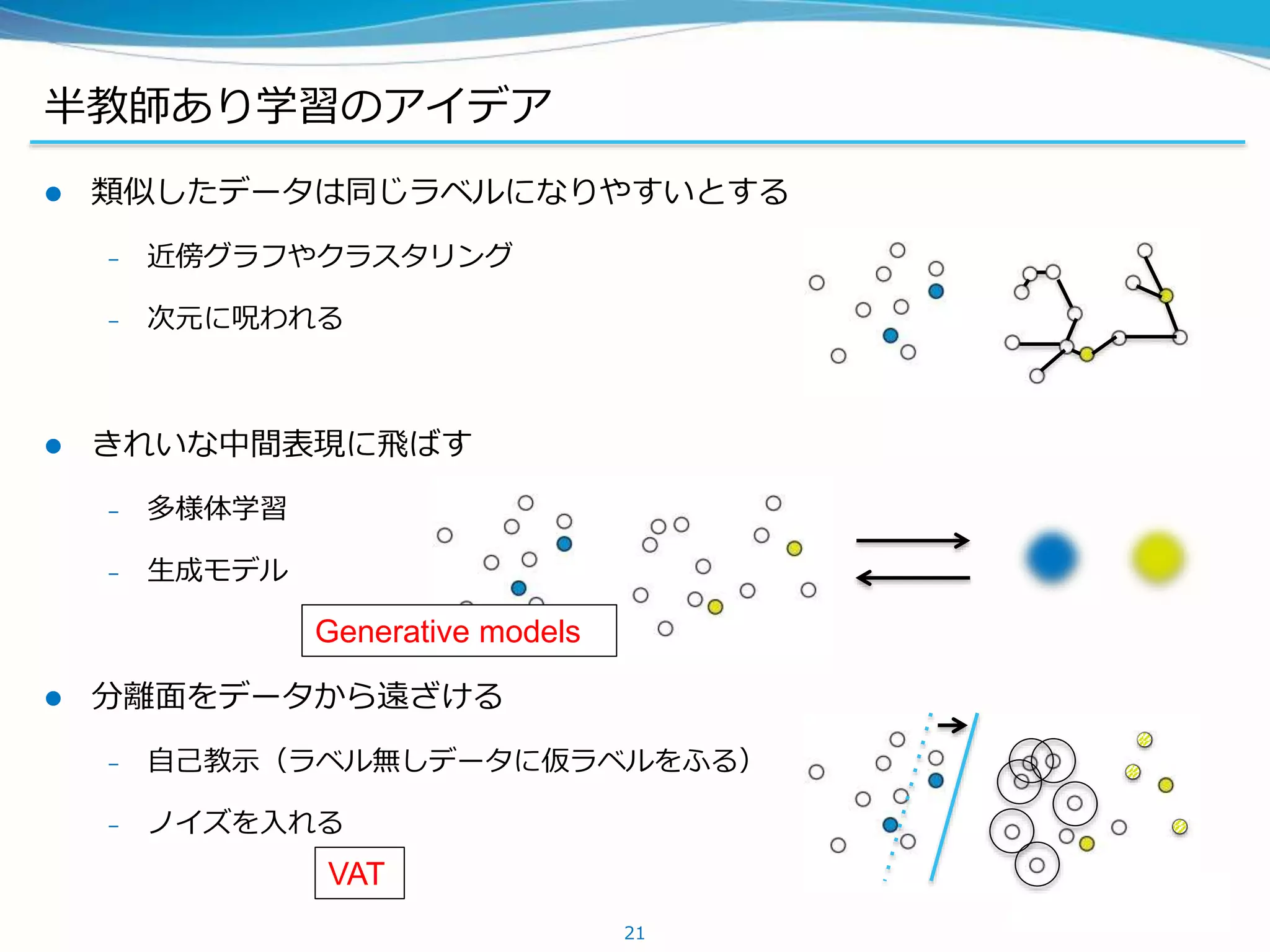
半教師あり学習の手法
Permutation-invariant MNISTのstate-of-the-art
12
100labels 60000 (all)
Feed-forward NN 25.8% 1.18%
Deep generative model (M1+M2)
(Kingma et al., 2014)
3.33% 0.96%
Virtual adversarial training
(Miyato et al., 2015)
2.12% 0.64%
Ladder network (Original)
(Rasmus et al., 2015)
1.06% 0.61%
Ladder network (AMLP)
(Mohammad et al., 2016)
1.00% 0.57%
Auxiliary deep generative model
(Maaloe et al., 2015)
0.96% -
①
①
②
③
③
今日話す順番 (半教師手法は全教師でもつよい)
13.
半教師あり学習の手法
Permutation-invariant MNISTのstate-of-the-art
13
100labels 60000 (all)
Feed-forward NN 25.8% 1.18%
Deep generative model (M1+M2)
(Kingma et al., 2014)
3.33% 0.96%
Virtual adversarial training
(Miyato et al., 2015)
2.12% 0.64%
Ladder network (Original)
(Rasmus et al., 2015)
1.06% 0.61%
Ladder network (AMLP)
(Mohammad et al., 2016)
1.00% 0.57%
Auxiliary deep generative model
(Maaloe et al., 2015)
0.96% -
☆
☆
14.
半教師あり学習の手法 – DeepGenerative Models
Deep Generative Modelのアイデア (VAE, AAEなどなど)
データの分布
本当はもっと高次元で複雑
Inference
Generation
狙った形の分布に押し込める
(画像は二次元正規分布)
まだラベルデータは使ってない
http://www.informatik.uni-
bremen.de/~afabisch/files/tsne/tsne_mnist_all.png arXiv:1511.05644
Deep NN
15.
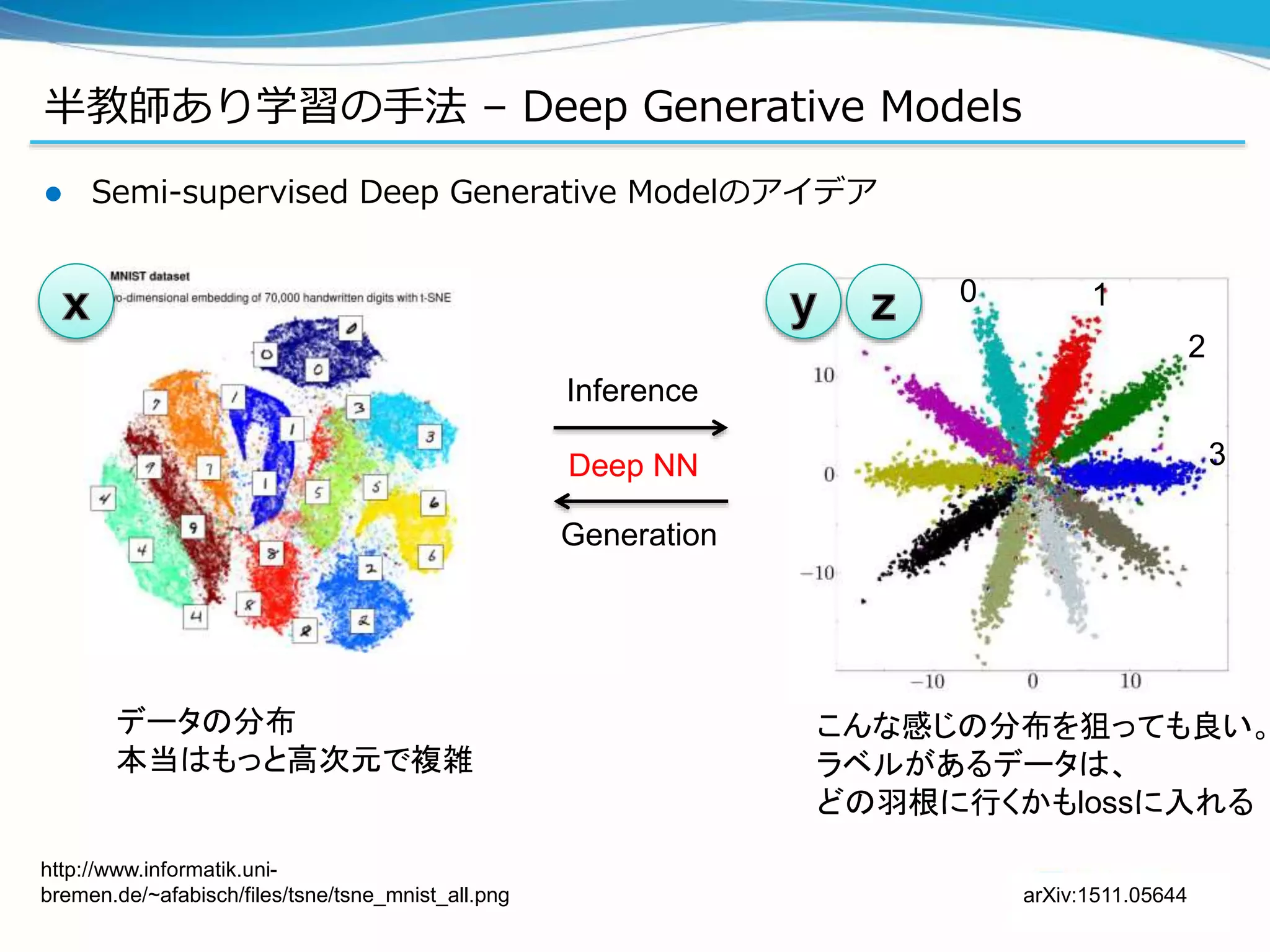
半教師あり学習の手法 – DeepGenerative Models
Semi-supervised Deep Generative Modelのアイデア
データの分布
本当はもっと高次元で複雑
Inference
Generation
こんな感じの分布を狙っても良い。
ラベルがあるデータは、
どの羽根に行くかもlossに入れる
http://www.informatik.uni-
bremen.de/~afabisch/files/tsne/tsne_mnist_all.png arXiv:1511.05644
Deep NN
0 1
2
3
16.
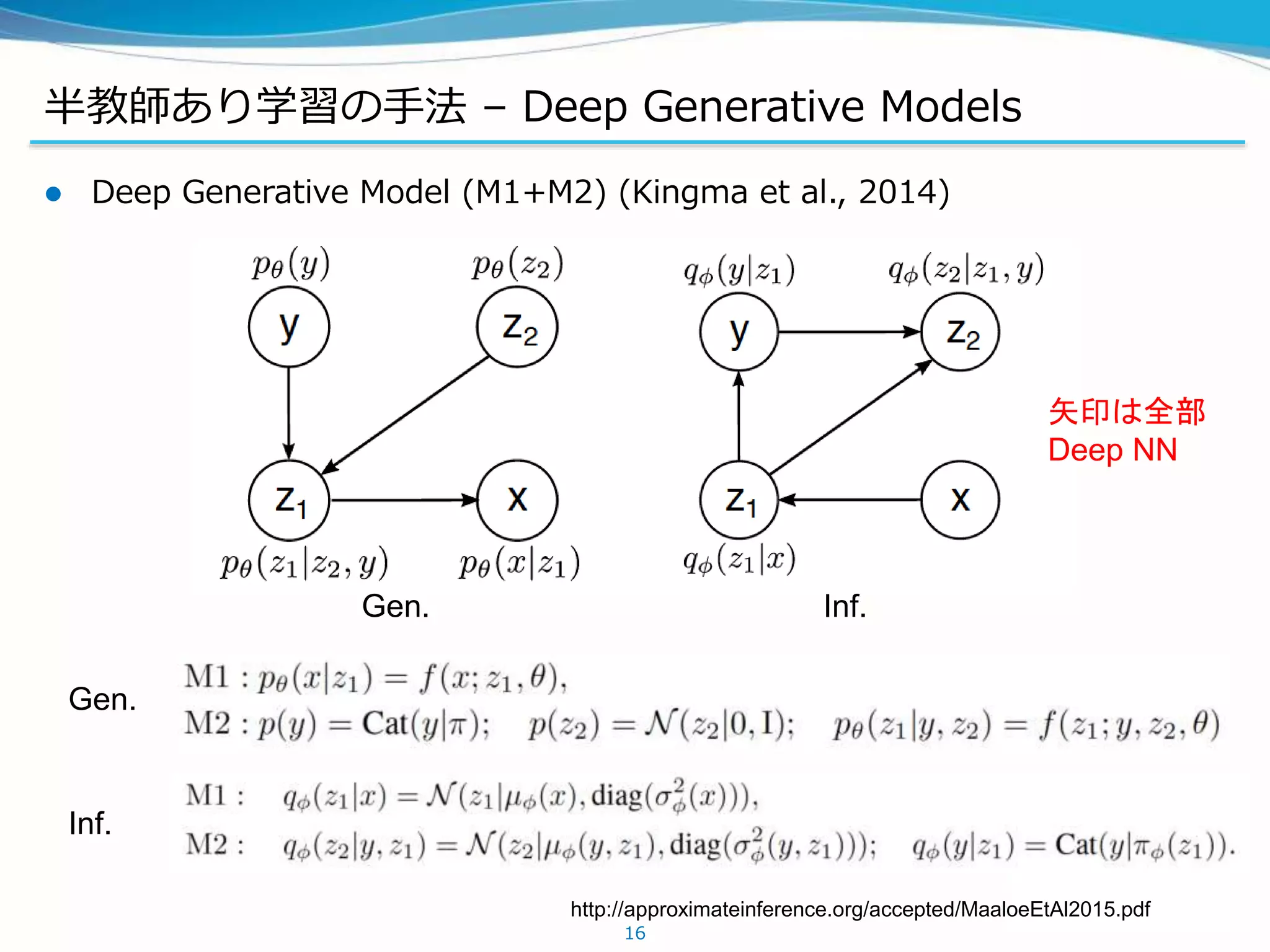
半教師あり学習の手法 – DeepGenerative Models
Deep Generative Model (M1+M2) (Kingma et al., 2014)
16
Gen.
Inf.
Gen. Inf.
http://approximateinference.org/accepted/MaaloeEtAl2015.pdf
矢印は全部
Deep NN
17.
半教師あり学習の手法 – DeepGenerative Models
Auxiliary Deep Generative Model (ADGM) (Maaloe et al., 2015)
17
NIPS2015のワークショップ論文
100 label MNISTで0.97%のerror (現在最高記録)を主張している…
(まだあまり検証されていない)
http://approximateinference.org/accepted/MaaloeEtAl2015.pdf
18.
半教師あり学習の手法
Permutation-invariant MNISTのstate-of-the-art
18
100labels 60000 (all)
Feed-forward NN 25.8% 1.18%
Deep generative model (M1+M2)
(Kingma et al., 2014)
3.33% 0.96%
Virtual adversarial training
(Miyato et al., 2015)
2.12% 0.64%
Ladder network (Original)
(Rasmus et al., 2015)
1.06% 0.61%
Ladder network (AMLP)
(Mohammad et al., 2016)
1.00% 0.57%
Auxiliary deep generative model
(Maaloe et al., 2015)
0.96% -
☆














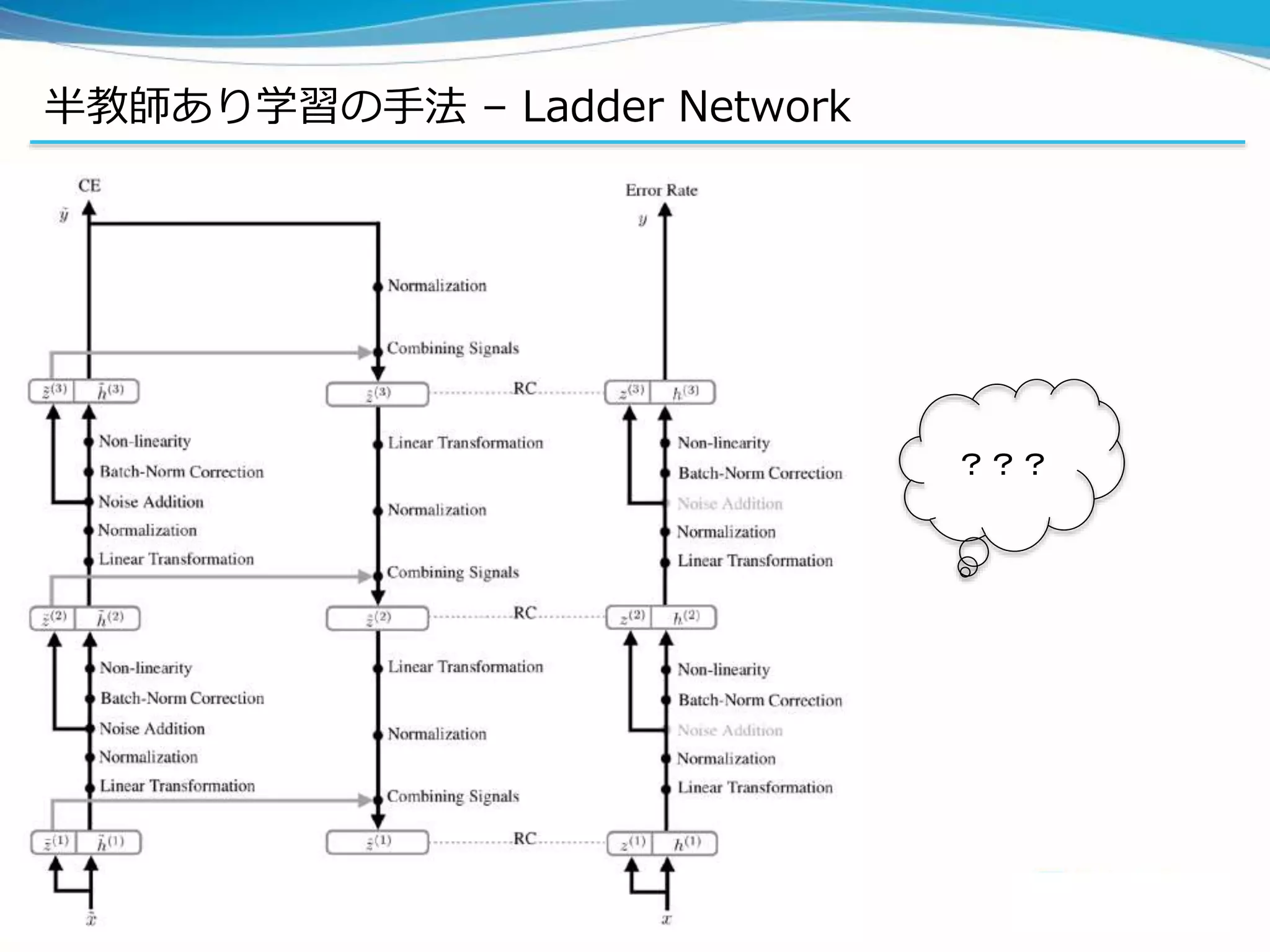



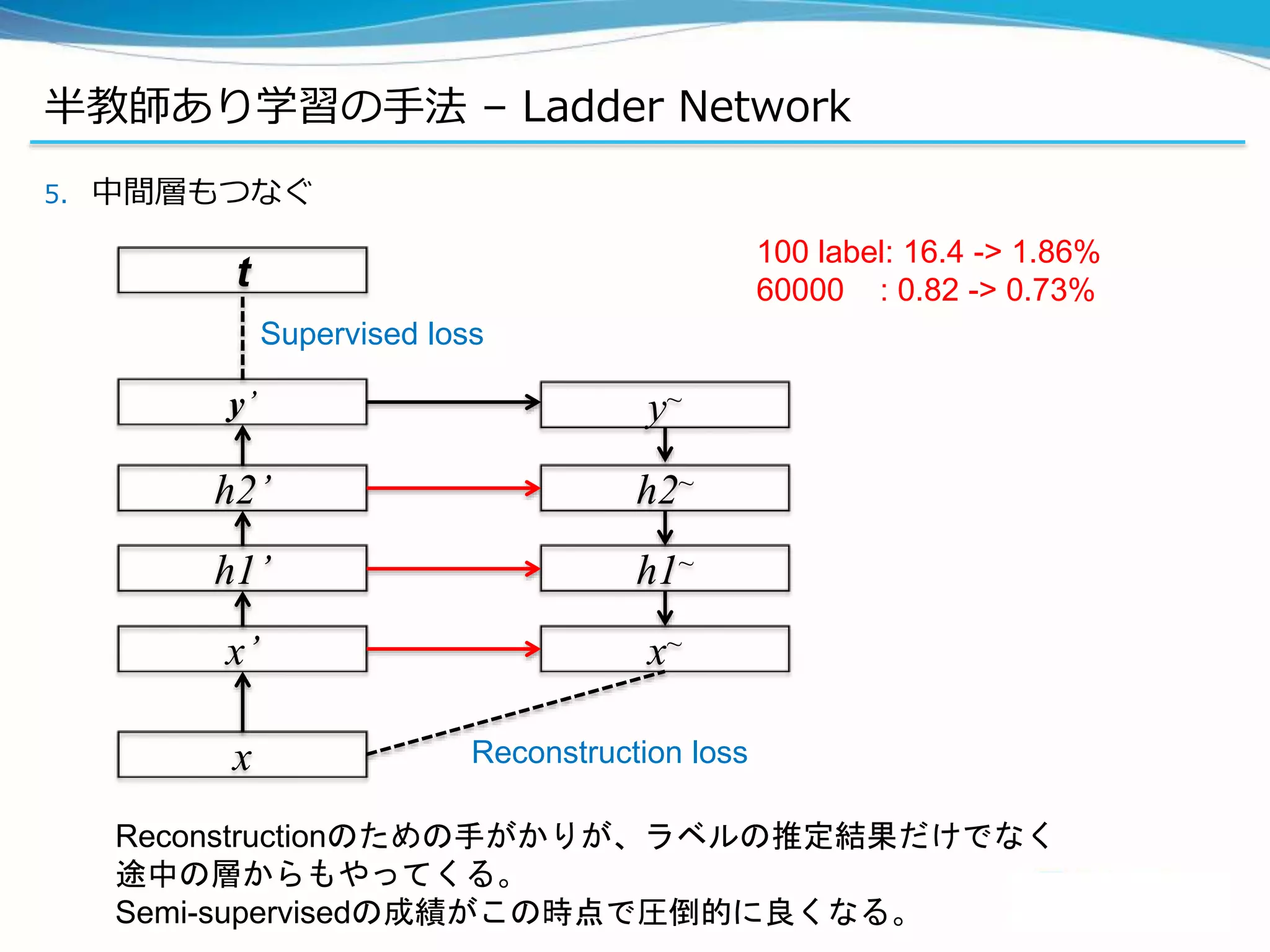
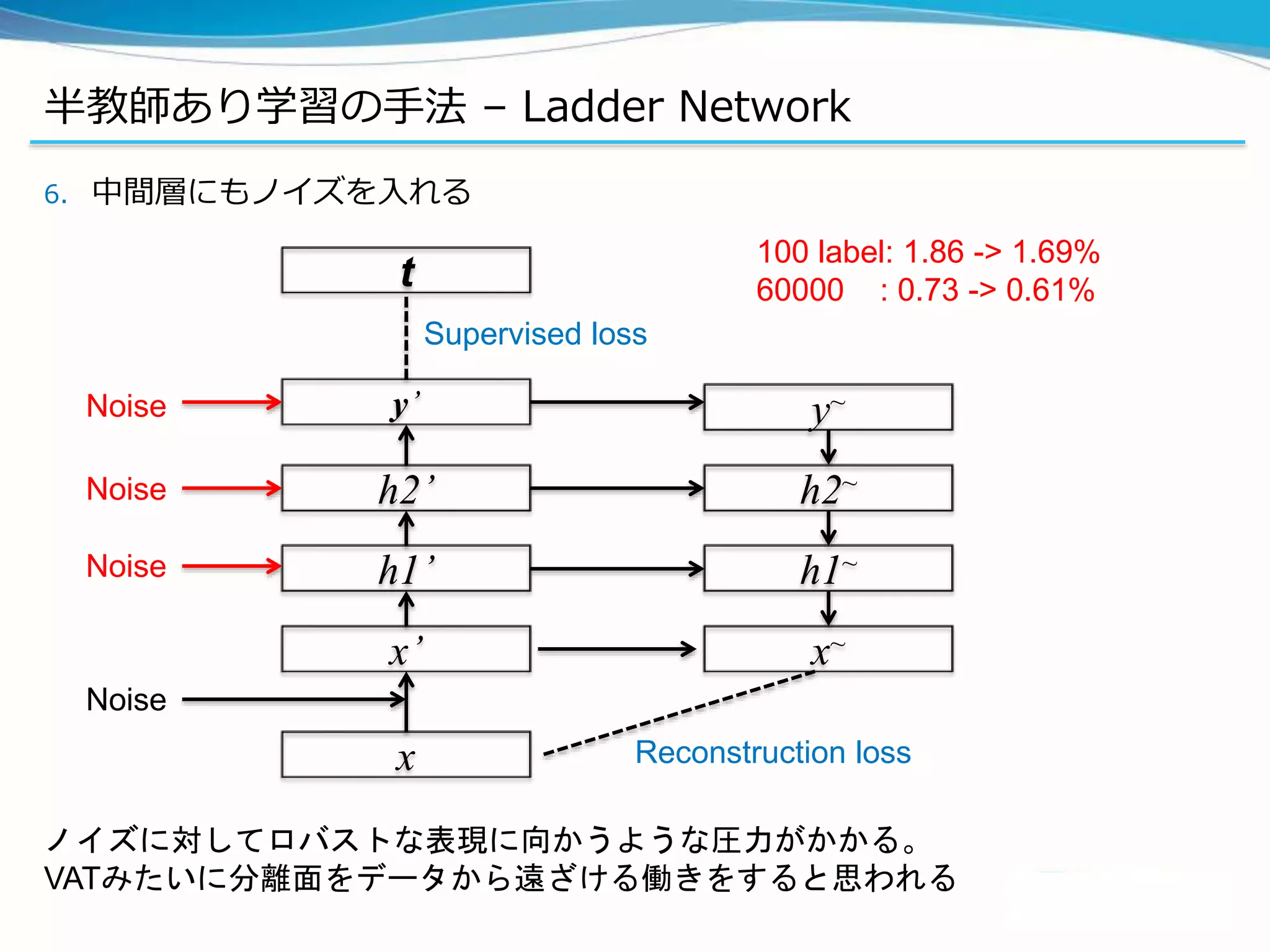
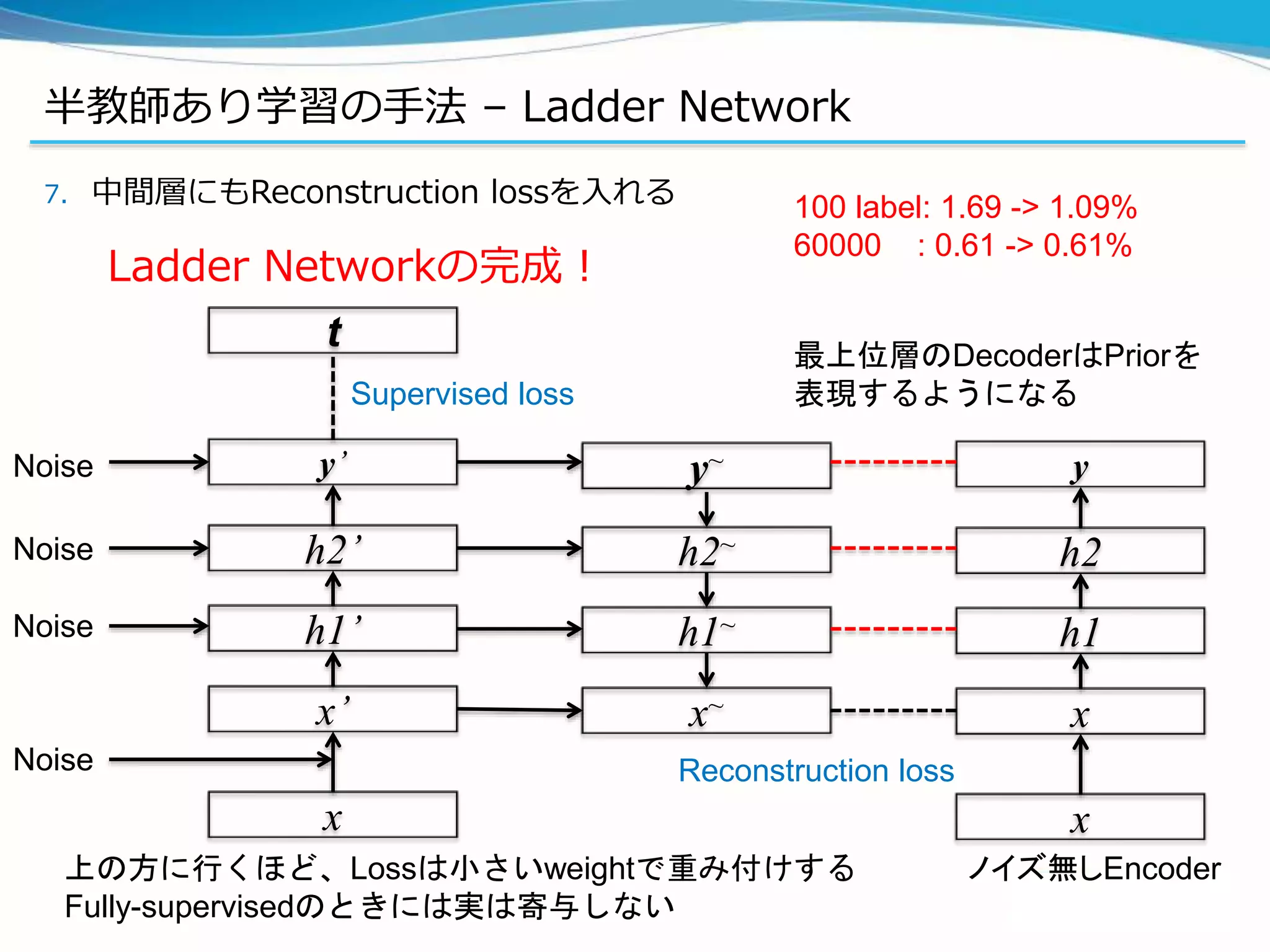








![半教師あり学習の手法 – Ladder Network
実装上の詳細⑤:さらにこまかいこと
– ラベル付きデータセットは、各クラスのデータが均等に入っているように作る
– Adamで学習。Learning rateはepoch100まで0.002で、150までで0におとす
– 入力データの値域は[0,1]
– ハイパーパラメタたちはひたすらグリッドサーチなどして求めたらしい
– Decoderのtopに入力するのは、softmax後
– LinearにBias項なし
– Clean encoder側にもBackpropする?(たぶんそう)
– Weight decayはいれる?(ないほうがよさそう)](https://image.slidesharecdn.com/nipsladder-160120073101/75/NIPS2015-Ladder-Networks-38-2048.jpg)


![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Deep Learning 第15章 表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning15-180601023904-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]SlowFast Networks for Video Recognition](https://cdn.slidesharecdn.com/ss_thumbnails/20191206slowfastnetworkkuboshizuma-191206010601-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)














![[unofficial] Pyramid Scene Parsing Network (CVPR 2017)](https://cdn.slidesharecdn.com/ss_thumbnails/pyramidsceneparsingnetwork-170815035025-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL Hacks輪読] Semi-Supervised Learning with Ladder Networks (NIPS2015)](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks-paper-reading-160107093848-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Learning to Simulate Complex Physics with Graph Networks](https://cdn.slidesharecdn.com/ss_thumbnails/learningtosimulatecomplexphysicswithgraphnetworks-200508054213-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会] GAN系の研究まとめ (NIPS2016とICLR2016が中心)](https://cdn.slidesharecdn.com/ss_thumbnails/dliwasawagansurvey-161220014753-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]10分で10本の論⽂をざっくりと理解する (ICML2020)](https://cdn.slidesharecdn.com/ss_thumbnails/20200828-ant-200828025358-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]High-Fidelity Image Generation with Fewer Labels](https://cdn.slidesharecdn.com/ss_thumbnails/190315dlseminargan-190315004124-thumbnail.jpg?width=640&height=640&fit=bounds)





