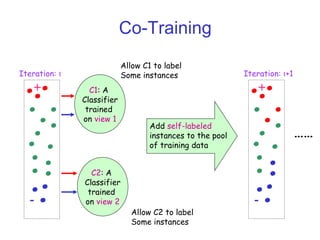
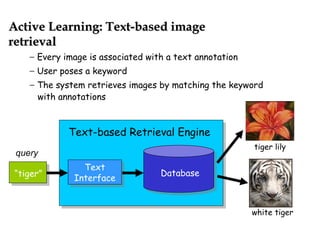
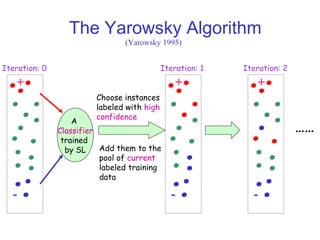
Semi-supervised learning aims to build accurate predictors using both labeled and unlabeled data. There are three main paradigms: transductive learning focuses on unlabeled data that are the test examples, active learning allows selecting unlabeled examples to label, and multi-view learning uses unlabeled data that have different feature sets. A popular multi-view method is co-training, which trains two classifiers simultaneously on different feature views and has them label each other's unlabeled data. Co-training assumes the views are conditionally independent and each is sufficient for prediction. It can be applied to tasks like web page and text classification.



![SSL: Why unlabeled data can be helpful?SSL: Why unlabeled data can be helpful?
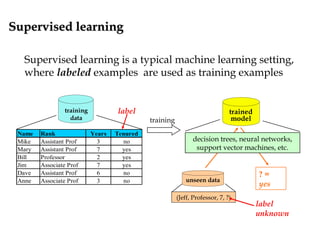
Suppose the data is well-modeled by a mixture density:
Thus, the optimal classification rule for this model is the MAP rule:
where and θ = {θl }( ) ( )
1
L
l l
l
f x f xθ α θ
=
= ∑ 1
1
L
ll
α=
=∑
The class labels are viewed as random quantities and are assumed chosen
conditioned on the selected mixture component mi ∈ {1,2,…,L} and
possibly on the feature value, i.e. according to the probabilities P[ci|xi,mi]
( ) arg max P , Pi i i i ijk
S x c k m j x m j x= = = = ∑
where
( )
( )
1
P
j i j
i i L
l i l
l
f x
m j x
f x
α θ
α θ
=
= =
∑
unlabeled examples can be used
to help estimate this term
[D.J. Miller & H.S. Uyar, NIPS’96]](https://image.slidesharecdn.com/semisupervised-learning3924/85/Semi-supervised-Learning-5-320.jpg)
![Transductive SVMTransductive SVM
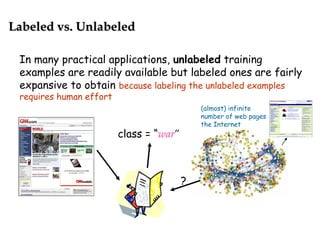
Transductive SVM: Taking into account a particular test
set and trying to minimize misclassifications of just those
particular examples
Figure reprinted from [T. Joachims, ICML99]
Concretely, using
unlabeled examples
to help identify the
maximum margin
hyperplanes](https://image.slidesharecdn.com/semisupervised-learning3924/85/Semi-supervised-Learning-6-320.jpg)

![ Uncertainty sampling
Train a single learner and then query the unlabeled
instances on which the learner is the least confident
[Lewis & Gale, SIGIR’94]
Committee-based sampling
Generate a committee of multiple learners and select the
unlabeled examples on which the committee members
disagree the most [Abe & Mamitsuka, ICML’98; Seung et al.,
COLT’92]
Active Learning: Representative approachesActive Learning: Representative approaches](https://image.slidesharecdn.com/semisupervised-learning3924/85/Semi-supervised-Learning-8-320.jpg)
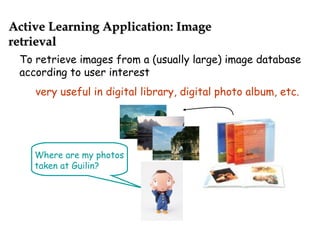

![learner1 learner2
X1 view X2 view
labeled training examples
unlabeled training examples
labeled
unlabeled examples
labeled
unlabeled examples
[A. Blum & T. Mitchell, COLT98]
Co-training (con’t)Co-training (con’t)](https://image.slidesharecdn.com/semisupervised-learning3924/85/Semi-supervised-Learning-12-320.jpg)
![Co-training (con’t)Co-training (con’t)
Theoretical analysis [Blum & Mitchell, COLT’98; Dasgupta,
NIPS’01; Balcan et al., NIPS’04; etc.]
Experimental studies [Nigam & Ghani, CIKM’00]
New algorithms
• Co-training without two views [Goldman & Zhou, ICML’00;
Zhou & Li, TKDE’05]
• Semi-supervised regression [Zhou & Li, IJCAI’05]
Applications
• Statistical parsing [Sarkar, NAACL01; Steedman et al.,
EACL03; R. Hwa et al., ICML03w]
• Noun phrase identification [Pierce & Cardie, EMNLP01]
• Image retrieval [Zhou et al., ECML’04; Zhou et al., TOIS06]](https://image.slidesharecdn.com/semisupervised-learning3924/85/Semi-supervised-Learning-13-320.jpg)





![Co-training
Assumption 1: compatibility
• The instance distribution is compatible with
the target function if for any
with non-zero probability, .
• Definition: compatibility of with :
),( 21 xxx =
D
),( 21 fff =
)()()( 2211 xfxfxf ==
Each set of features is sufficient for classification
0)]()(:),[(Pr1 221121 >≠−= xfxfxxp D
f D](https://image.slidesharecdn.com/semisupervised-learning3924/85/Semi-supervised-Learning-21-320.jpg)