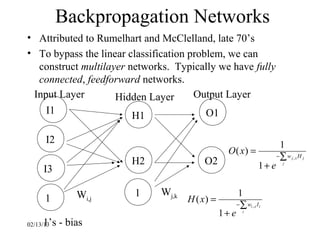
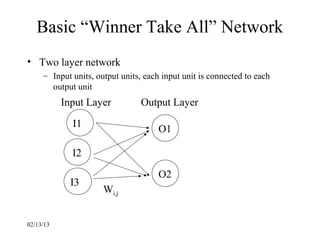
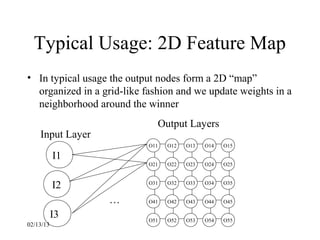
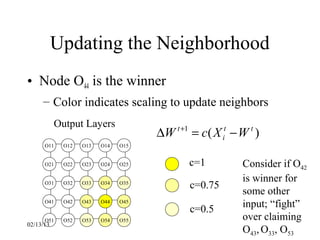
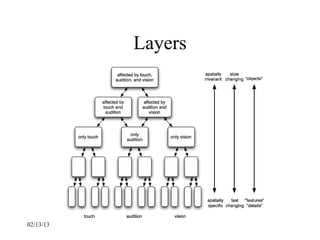
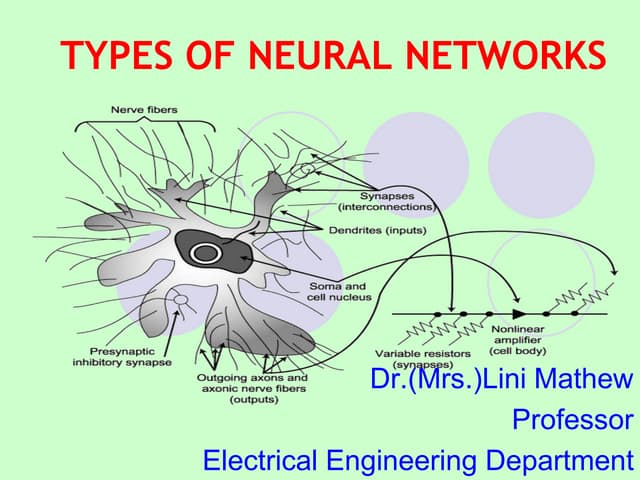
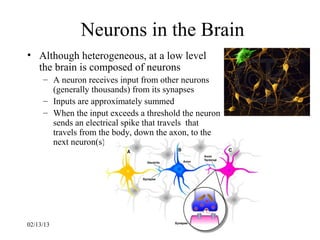
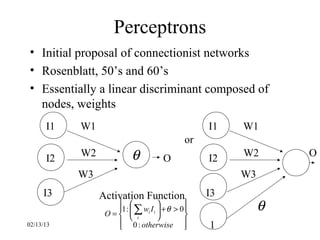
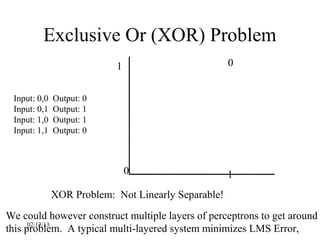
This document provides an introduction to neural networks. It discusses what connectionist neural networks are, including their key components of nodes, connections between nodes, distributed information storage, and learning through gradual changes in connection strength. The document then covers the history of neural networks, biological inspiration from the brain, different types of neural networks like perceptrons and backpropagation networks, and learning algorithms like LMS and unsupervised learning techniques like Hopfield networks and self-organizing maps.










![LMS Learning
LMS = Least Mean Square learning Systems, more general than the
previous perceptron learning rule. The concept is to minimize the total
error, as measured over all training examples, P. O is the raw output,
as calculated by ∑ wi I i + θ
i
1
Dis tan ce( LMS ) = ∑ ( TP − OP )
2
2 P
E.g. if we have two patterns and
T1=1, O1=0.8, T2=0, O2=0.5 then D=(0.5)[(1-0.8) 2+(0-0.5)2]=.145
We want to minimize the LMS:
C-learning rate
E W(old)
W(new)
02/13/13
W](https://image.slidesharecdn.com/nnppt-130212234446-phpapp02/85/Nn-ppt-14-320.jpg)