Download to read offline










![Centre for
Industrial Mathematics
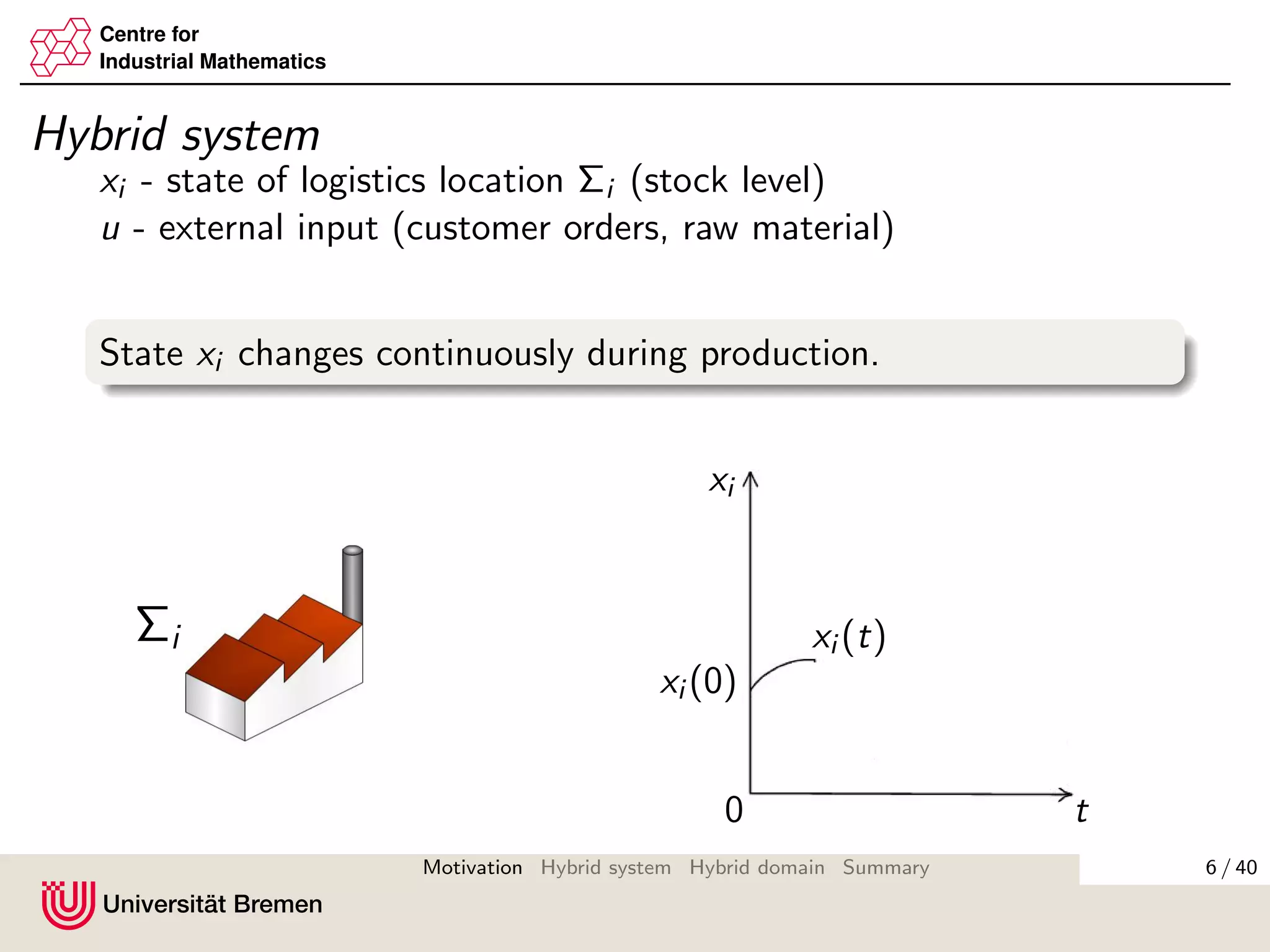
Hybrid system (Teel’s framework)
Σi :
˙xi = fi (x1, . . . , xn, u), (x1, . . . , xn, u)∈Ci
x+
i = gi (x1, . . . , xn, u), (x1, . . . , xn, u)∈Di
xi ∈χi ⊂RNi ,fi :Ci →RNi ,gi :Di →χi ,Ci , Di ⊂χ1×. . .×χn×U1×. . .×Un.
Basic regularity conditions for ∃ of solutions (Goebel & Teel 2006):
fi , gi are continuous;
Ci , Di are closed.
Solution xi (t, k) is defined on hybrid time domain:
dom xi := ∪[tk, tk+1]×{k}
t is time and k is number of the last jump.
8 / 40Motivation Hybrid system Hybrid domain Summary](https://image.slidesharecdn.com/kosmykoverfurt2012-160619172411/75/Interconnections-of-hybrid-systems-14-2048.jpg)








![Centre for
Industrial Mathematics
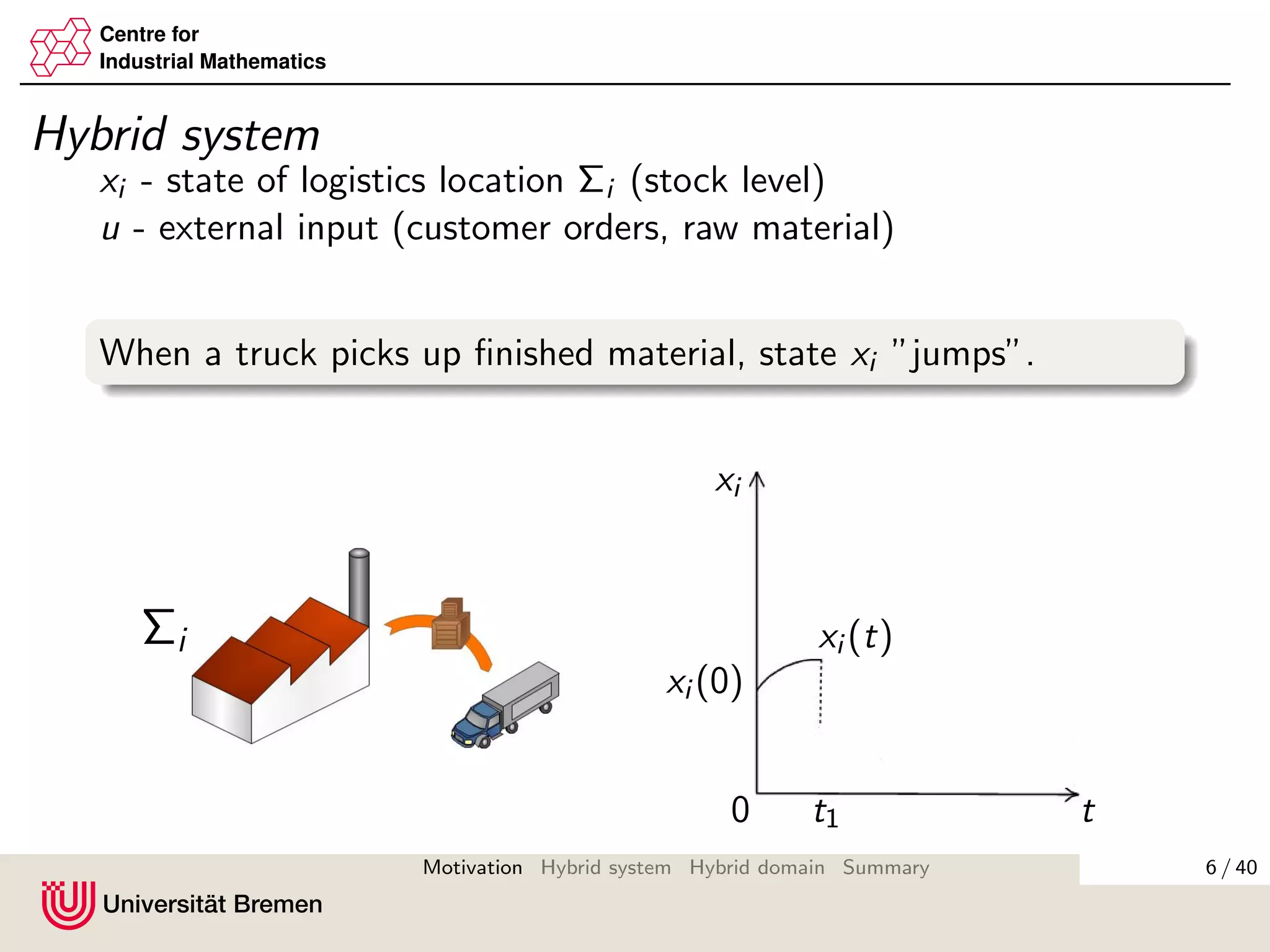
Our approach
We take into account which of the system can jump by:
IC (x, u):={i : (x, u) ∈ Ci }, ID(x, u):={i : (x, u) ∈ Di }.
Then dynamics is given by
˙xi = fi (x, u), i ∈ IC (x, u),
x+
i = gi (x, u), i ∈ ID(x, u).
Hybrid time domain considers the jumps of the subsystems
separately:
domk1,...,kn := ∪[tk, tk+1] × {k1, . . . , kn} ⊂ R+ × Nn
+,
where k = k1 + · · · + kn and ki ∈ N+ calculates the jumps of
the ith subsystem.
ti
max
18 / 40Motivation Hybrid system Hybrid domain Summary](https://image.slidesharecdn.com/kosmykoverfurt2012-160619172411/75/Interconnections-of-hybrid-systems-24-2048.jpg)













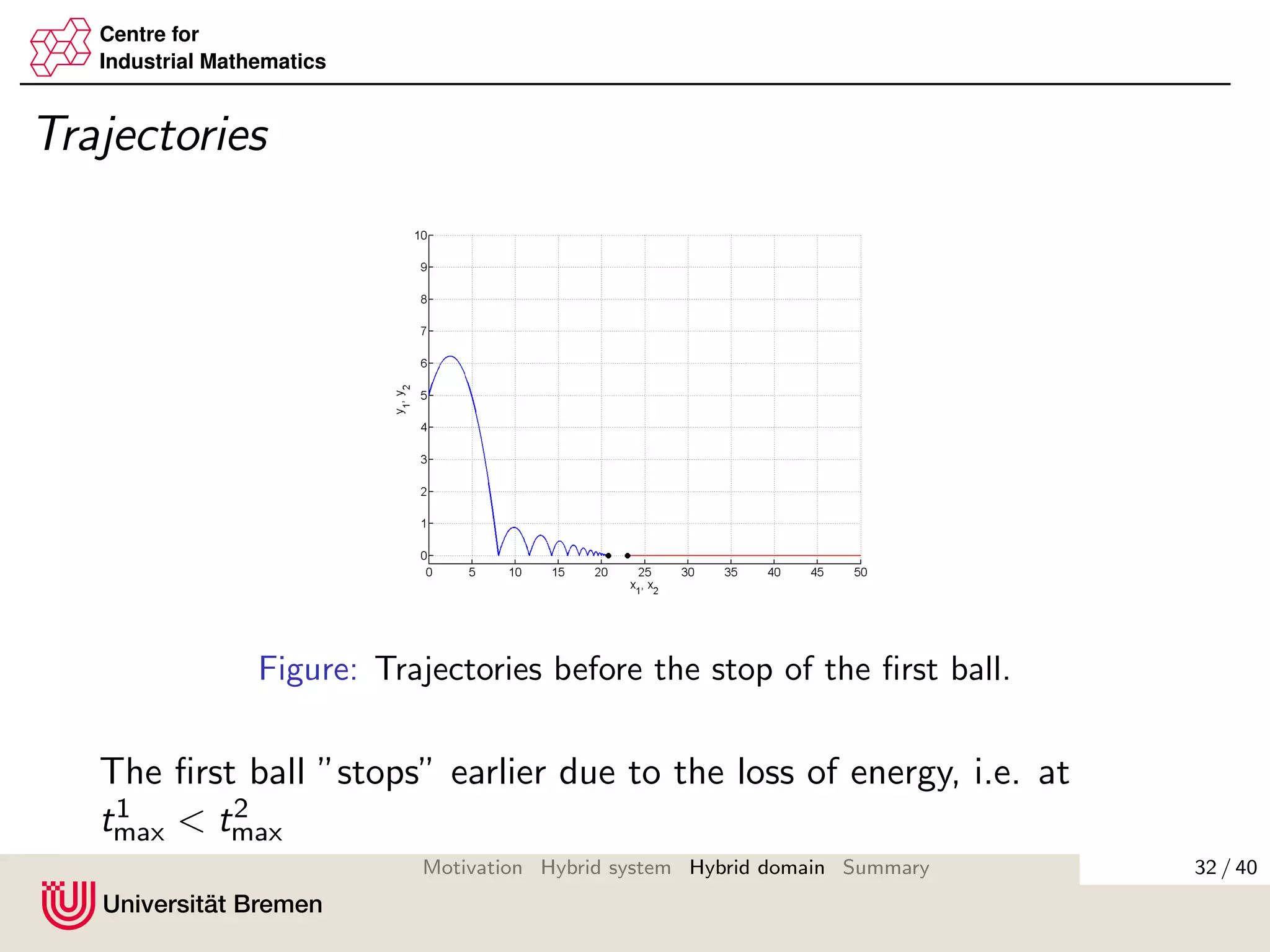


![Centre for
Industrial Mathematics
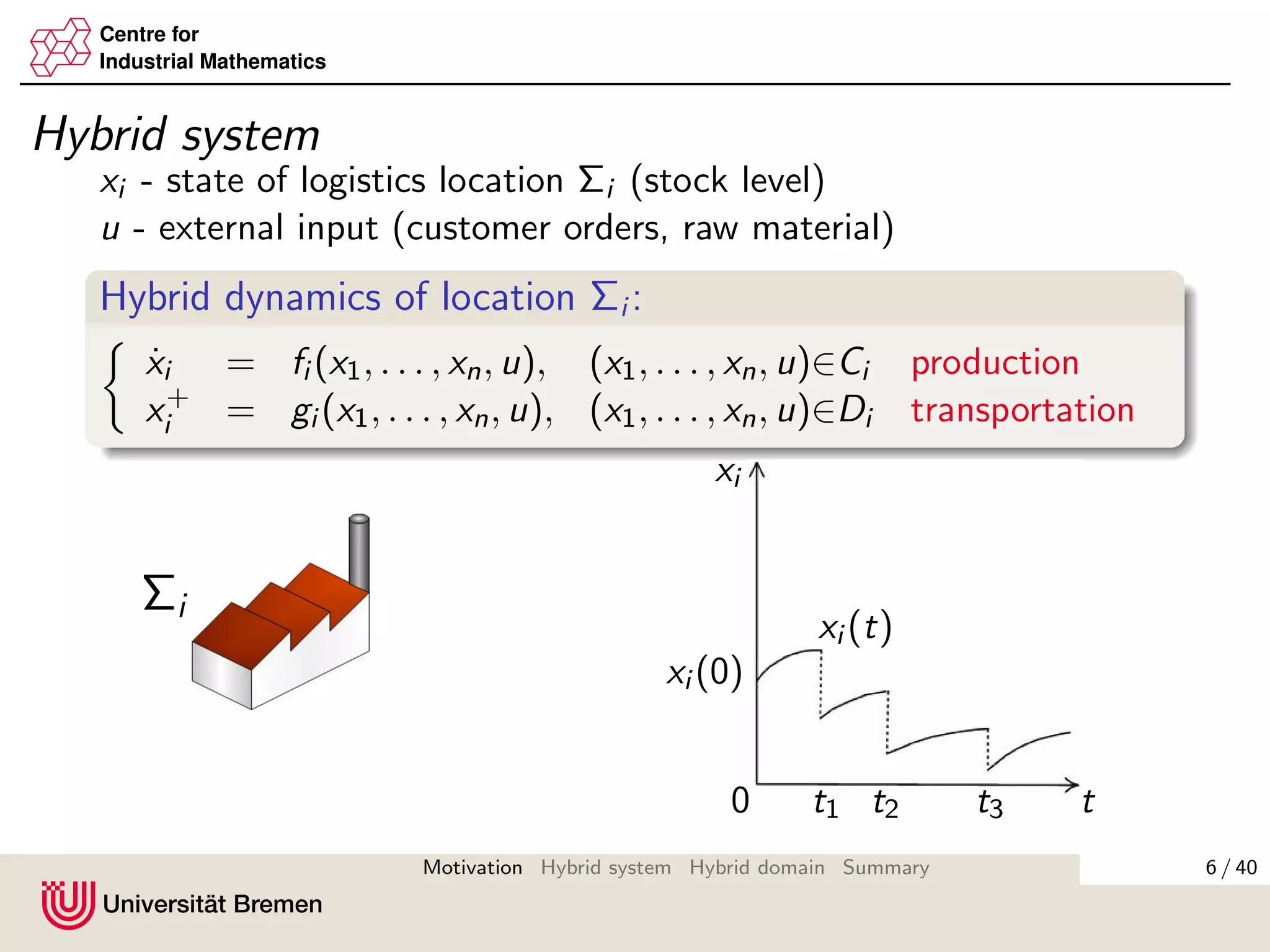
Possible solution
Instead of considering min{t, ti
max}, we consider intervals
[ti,ki
min, ti,ki
max], ki = 0, 1, 2, . . .
where system i is ”active”, and intervals
[ti,ki
max, ti,ki +1
min ],
where system i is ”passive” (in physical sense).
θi (t) :=
t, ti,ki
min < t < ti,ki
max
ti,ki
max, ti,ki
max < t < ti,ki +1
min
identifies, whether at time t the system i is ”active” or ”passive”.
35 / 40Motivation Hybrid system Hybrid domain Summary](https://image.slidesharecdn.com/kosmykoverfurt2012-160619172411/75/Interconnections-of-hybrid-systems-41-2048.jpg)


![Centre for
Industrial Mathematics
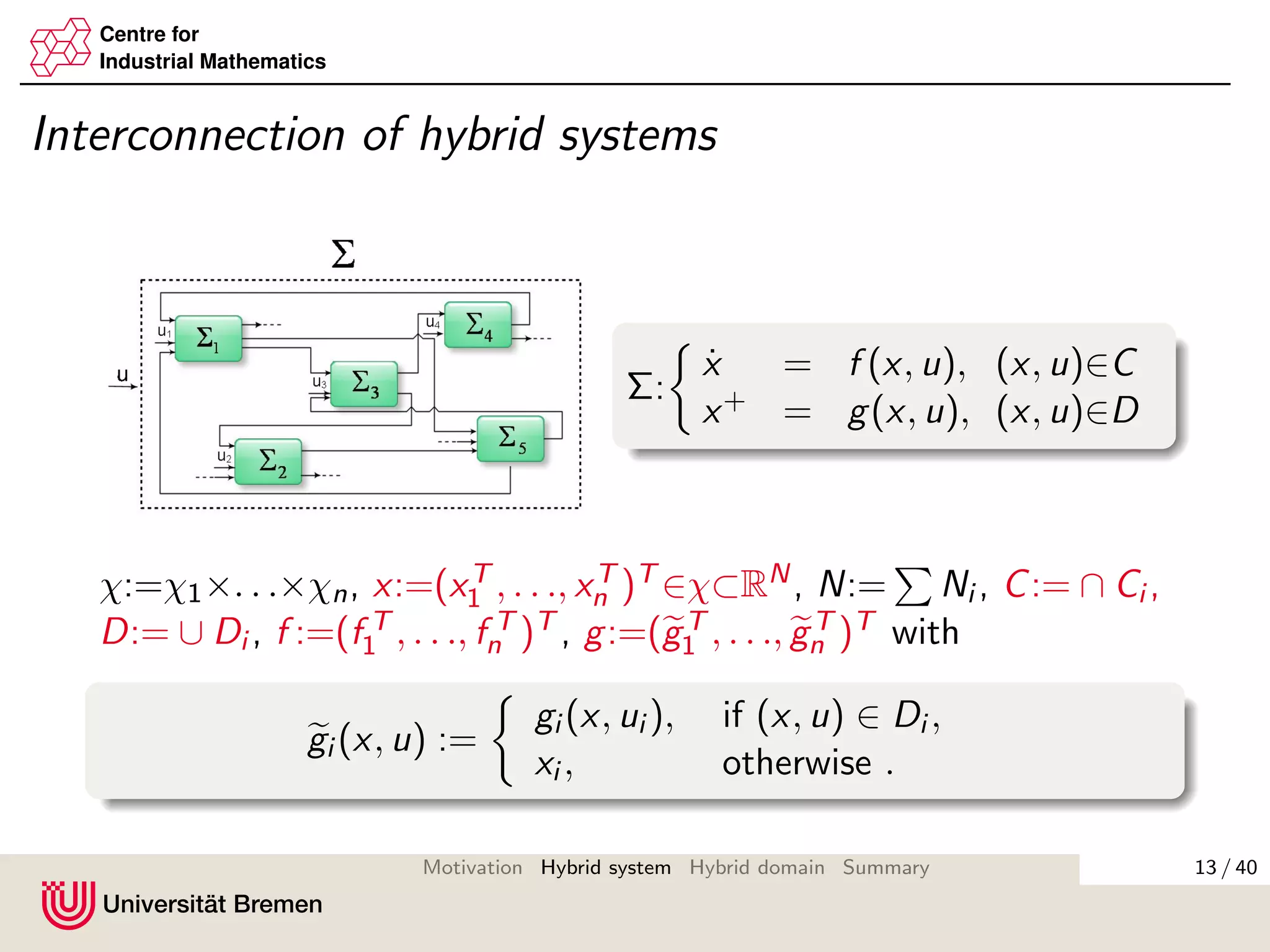
Existence of solutions
Theorem (Existence of solutions, continued)
then there exists a solution pair (x, u) for hybrid system with
(t, ¯k) ∈ domx for some t > 0 or ¯k ≡ (0, . . . , 0)T ∈ Nn
+.
Furthermore, if for all i ∈ {1, . . . , n}, gi (Di ) ∈ Ci ∪ Di , then there
exists a solution with t > 0, ¯k ∈ Nn
+ such that
(x(t, ¯k), u(t, ¯k)) ∈ Ci ∪ Di .
Proof
For each interval [ti,ki
min, ti,ki +1
min ] we consider all the cases separately
and construct solutions for them explicitly. Then we concatenate
the solutions on the intervals.
38 / 40Motivation Hybrid system Hybrid domain Summary](https://image.slidesharecdn.com/kosmykoverfurt2012-160619172411/75/Interconnections-of-hybrid-systems-44-2048.jpg)



The document discusses modeling a logistics network as a hybrid system. Key points: - A logistics network with production sites, distribution centers, suppliers and customers can be modeled as a hybrid system with both continuous and discrete dynamics. - The state of each logistics location (stock level) changes continuously during production but jumps discretely when goods are transported. - The overall network is modeled as an interconnection of the individual location hybrid systems. - Analyzing the stability of such hybrid systems is important to minimize costs and unsatisfied orders in the logistics network.










































































