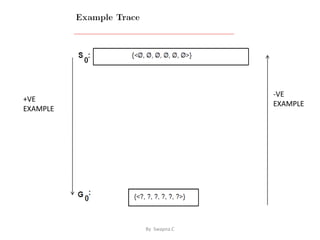
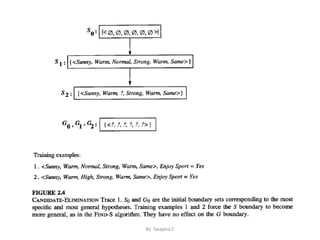
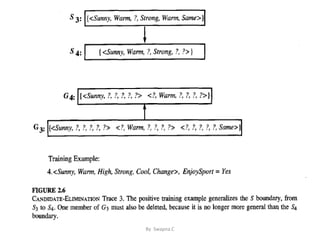
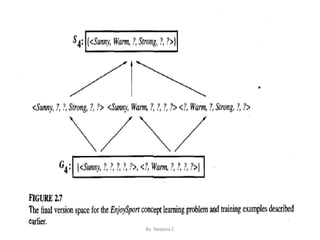
This document discusses concept learning, which involves inferring a Boolean-valued function from training examples of its input and output. It describes a concept learning task where each hypothesis is a vector of six constraints specifying values for six attributes. The most general and most specific hypotheses are provided. It also discusses the FIND-S algorithm for finding a maximally specific hypothesis consistent with positive examples, and its limitations in dealing with noise or multiple consistent hypotheses. Finally, it introduces the candidate-elimination algorithm and version spaces as an improvement over FIND-S that can represent all consistent hypotheses.