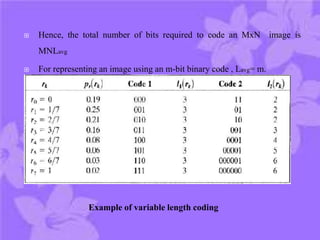
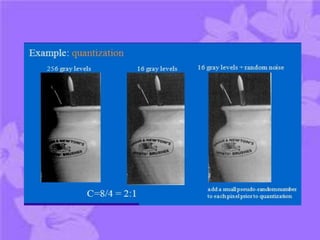
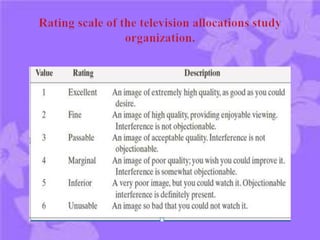
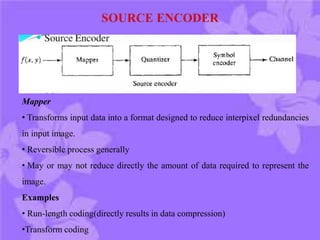
This document discusses digital image compression. It notes that compression is needed due to the huge amounts of digital data. The goals of compression are to reduce data size by removing redundant data and transforming the data prior to storage and transmission. Compression can be lossy or lossless. There are three main types of redundancy in digital images - coding, interpixel, and psychovisual - that compression aims to reduce. Channel encoding can also be used to add controlled redundancy to protect the source encoded data when transmitted over noisy channels. Common compression methods exploit these different types of redundancies.





![ Let a discrete random variable r k in [0,1] represent the gray
levels of an image.
pr(rk ) denotes the probability of occurrence of r
Pr(rk) = nk / n , k=0,1,2,….L-1
If the number of pixels used to represent each value of rk is
l(rk ), then the average number of bits required to represent
each pixel is
L-1
Lavg = £ l(rk)pr(rk)
k=0
CODING REDUNDANCY](https://image.slidesharecdn.com/fundamentalsandimagecompressionmodels-180818131548/85/Fundamentals-and-image-compression-models-5-320.jpg)