concept_learning_presentation by tom m michael book.pptx
1.
Concept Learning andthe General-
to-Specific Ordering
You all are Encouraged to to study from the textbook referred or can
go to vtupulse.
Textbook: Tom Mitchell, ―Machine Learning, McGraw Hill, 3rd
Edition, 1997.
2.
Concept Learning andGeneral-to-Specific
Ordering
• Concept Learning Task
• Concept Learning as Search
• Find-S Algorithm
• Version Spaces & Candidate-Elimination
• Remarks on Version Spaces
• Inductive Bias
3.
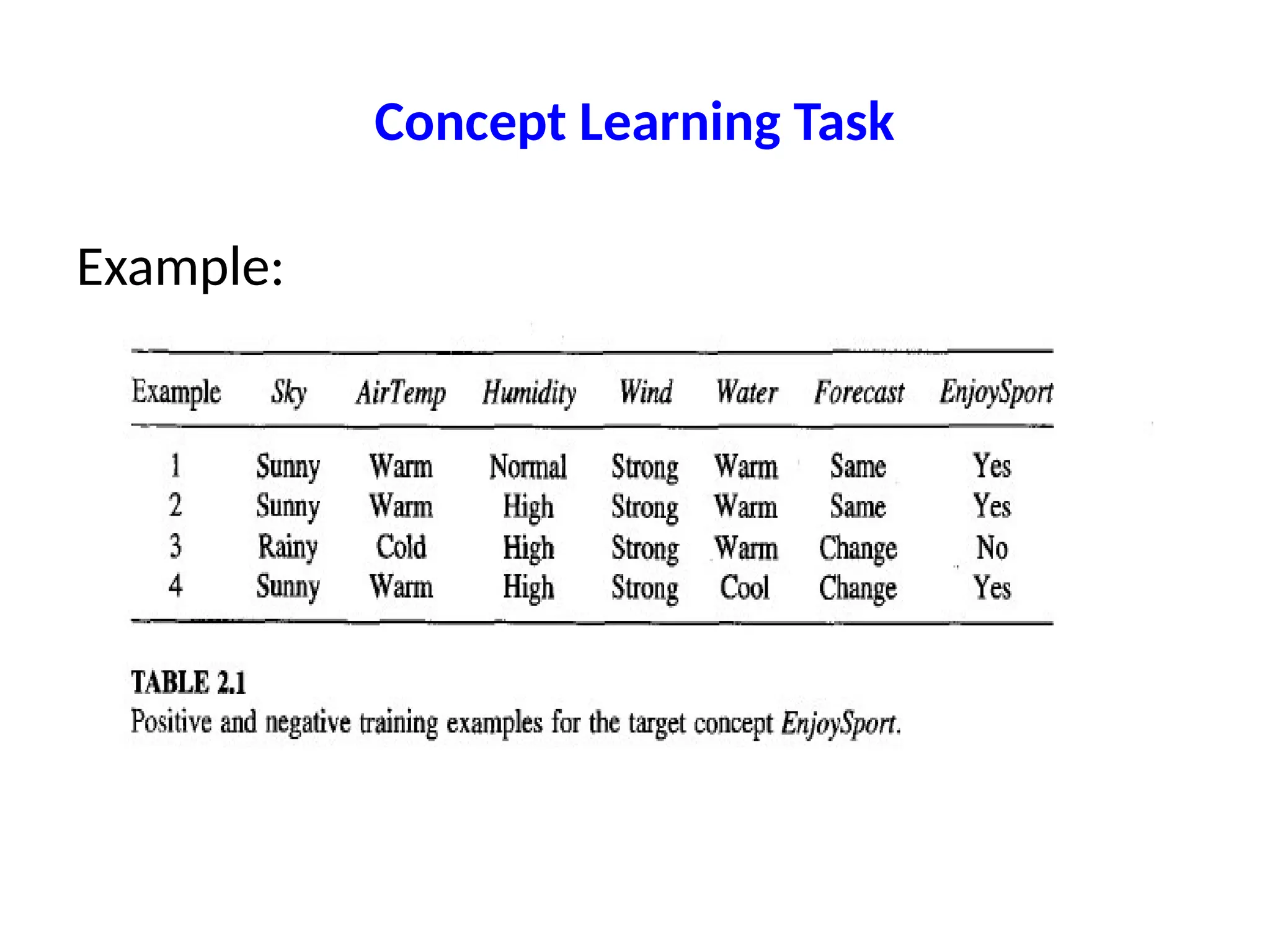
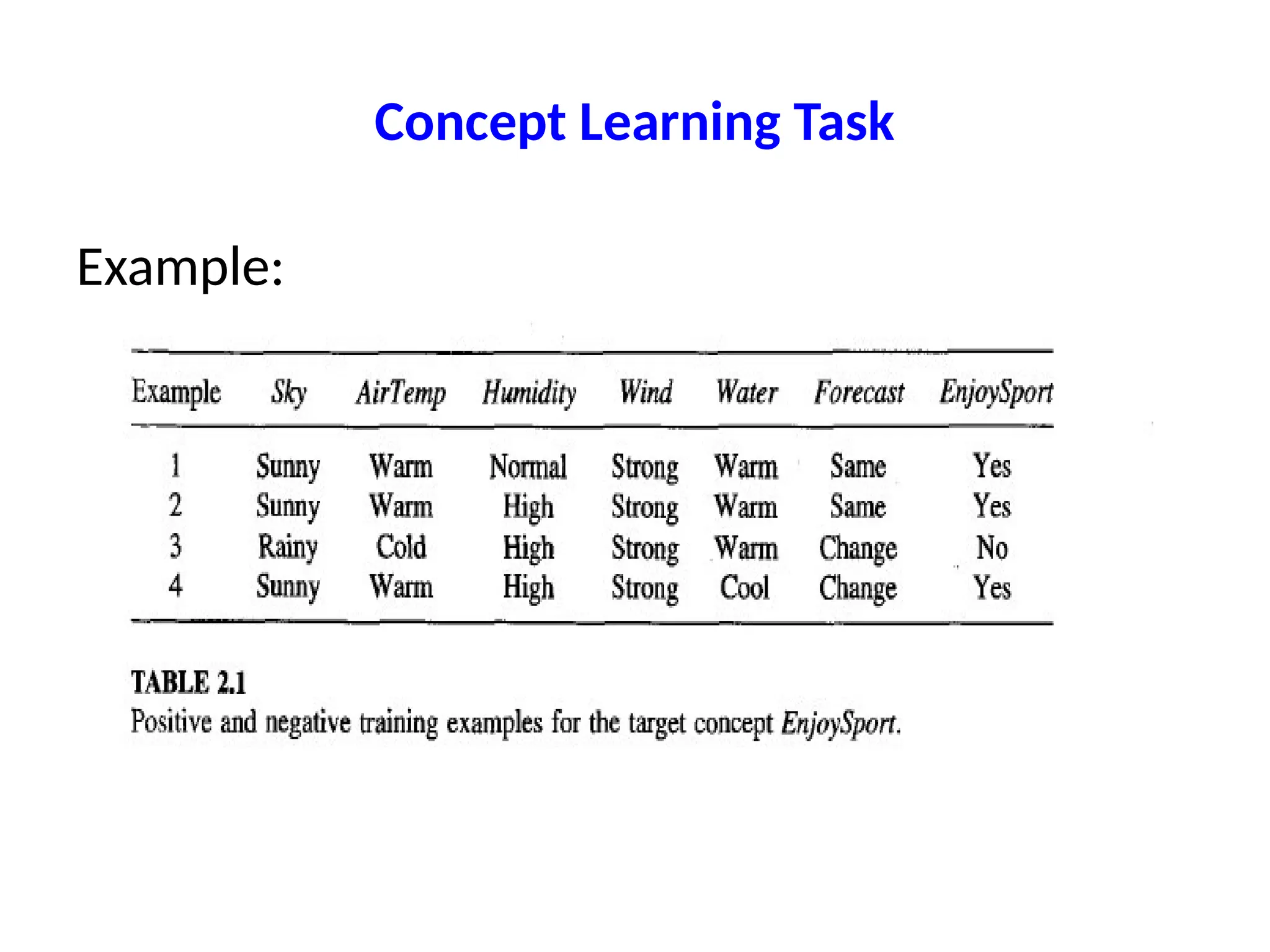
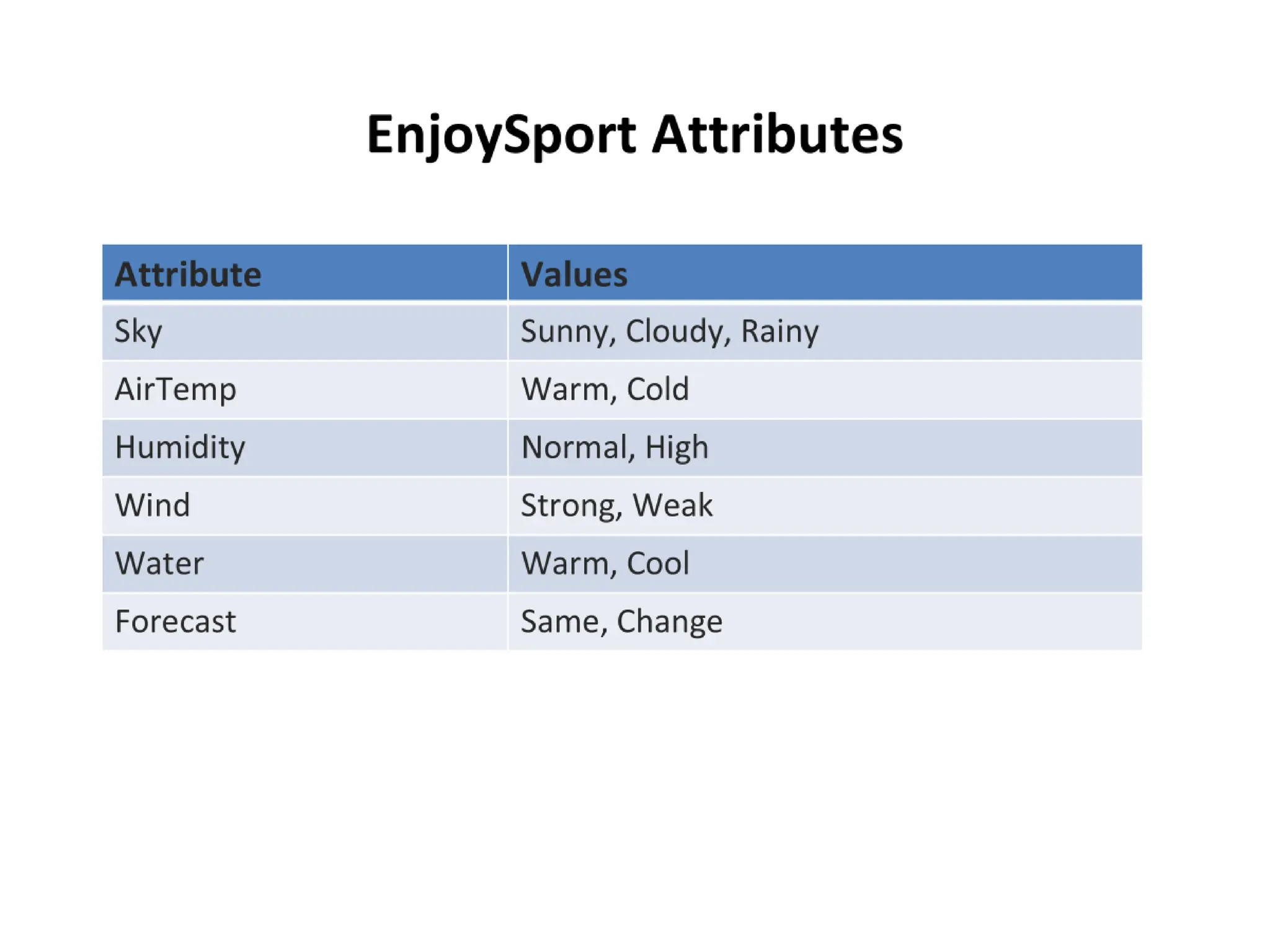
Concept Learning Task
•Goal: Identify the target concept from given
examples.
• Instances described by attributes (e.g., Sky,
Temp, etc.).
• Output: Hypothesis h that matches target
concept c.
• Challenge: Only have training examples, not all
instances.
Inductive Learning Hypothesis
•If a hypothesis fits the training data well, it
will likely fit unseen data.
• Core assumption behind inductive learning.
• Cannot be proven universally — it's an
inductive bias.
• We can only guarantee:
• ℎ( )= ( ) for all training examples seen
𝑥 𝑐 𝑥
• For unseen examples, it’s a guess.
6.
Concept Learning asSearch
• Hypothesis space: All hypotheses expressible
in chosen representation.
• Learning = searching for the best hypothesis in
this space.
• Choice of representation defines what can be
learned.
• Example: EnjoySport task — small finite
hypothesis space (973 semantic hypotheses).
General-to-Specific Ordering
• Hypothesescan be arranged by how many
instances they accept.
• Most general: accepts all instances.
Example: <?,?,?,?,?,?>
• Most specific: accepts none.
Example: <Ø, Ø, Ø, Ø, Ø, Ø>
• Learning algorithms can navigate this
structure efficiently.
9.
Example: Consider twohypothesis h1 and h2
For above example, we can say h2 is more
general than or equal to h1.
10.
Find-S Algorithm
• Startswith most specific hypothesis.
• Generalizes to cover positive examples.
• Stops when all positive examples are covered.
• Limitation: Ignores negative examples.
Limitations of Find-SAlgorithm
• Considers only positive examples, ignores negative ones.
• Sensitive to noise – a single incorrect example can mislead the
hypothesis.
• Cannot handle incomplete or inconsistent data.
• Produces only the most specific hypothesis, does not represent
all possible consistent hypotheses.
• Assumes the target concept exists in the hypothesis space
(may fail if it doesn’t).
19.
When is aHypothesis Consistent?
A hypothesis is said to be consistent with the training examples if
it correctly classifies all the training examples.
That means:
● For every positive example, the hypothesis predicts positive.
● For every negative example, the hypothesis predicts negative.
20.
● The VersionSpace is the set of all hypotheses that are
consistent with the training examples.
● It is bounded by the most specific hypothesis (S) and the
most general hypothesis (G).
● As more training examples are added, the version space
shrinks, narrowing down the set of possible target concepts.
Version Space
21.
Idea: Start withall hypotheses in the hypothesis space, then eliminate those that
are inconsistent with the training examples.
Steps:
● Initialize the version space VS to contain all hypotheses in the hypothesis
space H.
● For each training example (x,c(x)):
○ Remove from VS any hypothesis h such that h(x)≠c(x)
● After processing all examples, the remaining hypotheses in VS are consistent
with the data.
Output:
● The version space containing all consistent hypotheses.
List-Then-Eliminate Algorithm
22.
● The CandidateElimination Algorithm finds the version space efficiently by
maintaining two boundary sets:
1. S (Specific boundary): The set of most specific hypotheses consistent with
the data.
2. G (General boundary): The set of most general hypotheses consistent with
the data.
Candidate Elimination Algorithm – Overview
23.
● Process:
○ InitializeS to the most specific hypothesis and G to the most general hypothesis.
○ For each training example:
■ If the example is positive → generalize S just enough to include it.(Prune G)
■ If the example is negative → specialize G just enough to exclude it.(Prune S)
■ Remove hypotheses from S and G that are inconsistent with the training
data.
○ After all examples, the version space is represented by all hypotheses between S
and G.
● Key Point: Unlike Find-S, it uses both positive and negative examples and
represents all consistent hypotheses, not just one.
Candidate Elimination Algorithm – Overview
25.
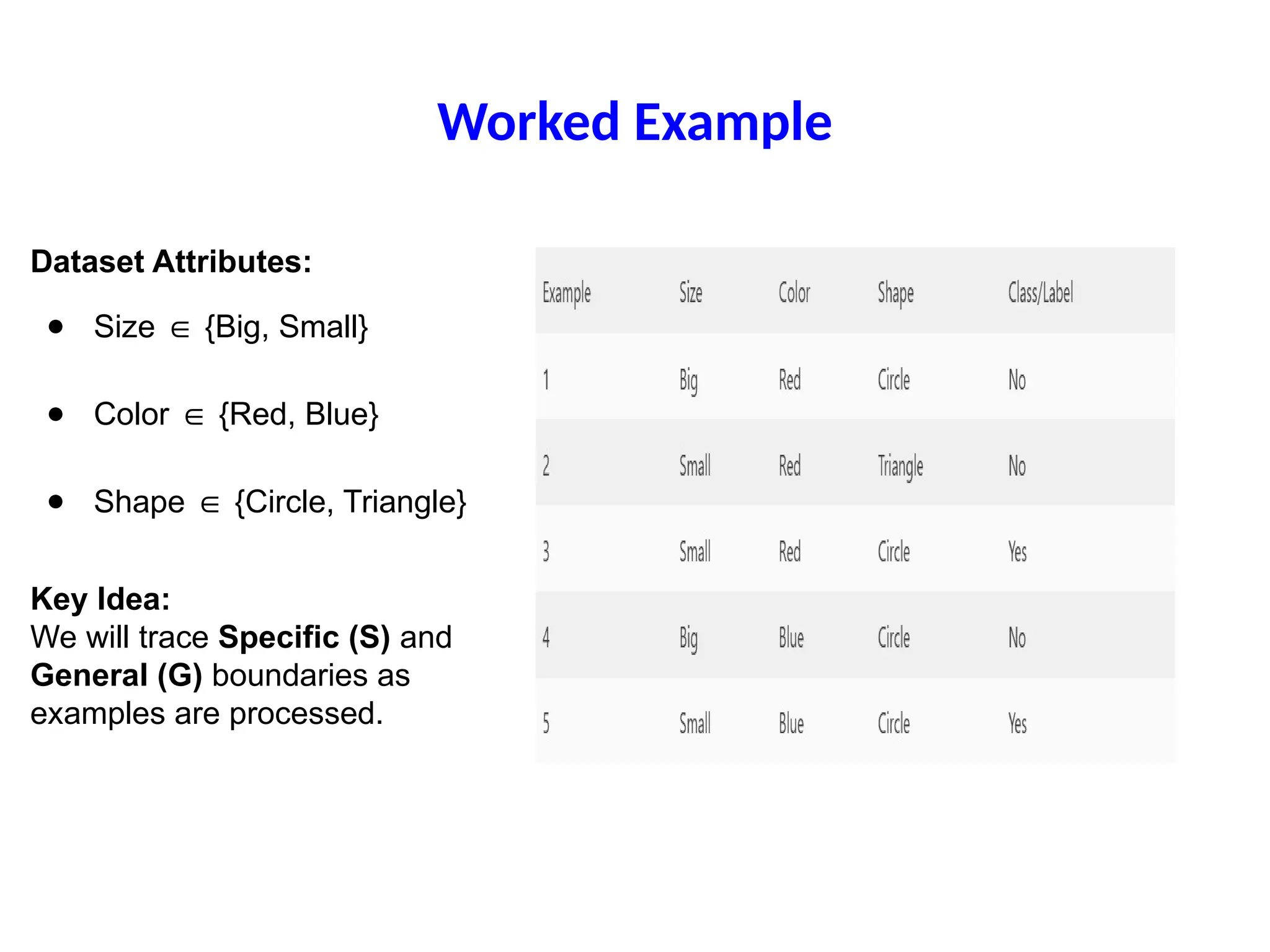
Worked Example
Dataset Attributes:
●Size {Big, Small}
∈
● Color {Red, Blue}
∈
● Shape {Circle, Triangle}
∈
Key Idea:
We will trace Specific (S) and
General (G) boundaries as
examples are processed.
26.
● Initialization:
○ S0
=(ø,ø, ø) (most specific Boundary)
G0
=(?,?,?) (most general Boundary)
● After Example 1 (Negative):
○ S1
=(ø, ø, ø)
○ G1=(Small,?,?),(?,Blue,?),(?,?,Triangle)
● After Example 2 (Negative):
○ S2=(ø, ø, ø)
○ G2 = (Small,Blue,?),(Small,?,Circle),(?,Blue,?),(Big,?,Triangle),(?,Blue,Triangle)
27.
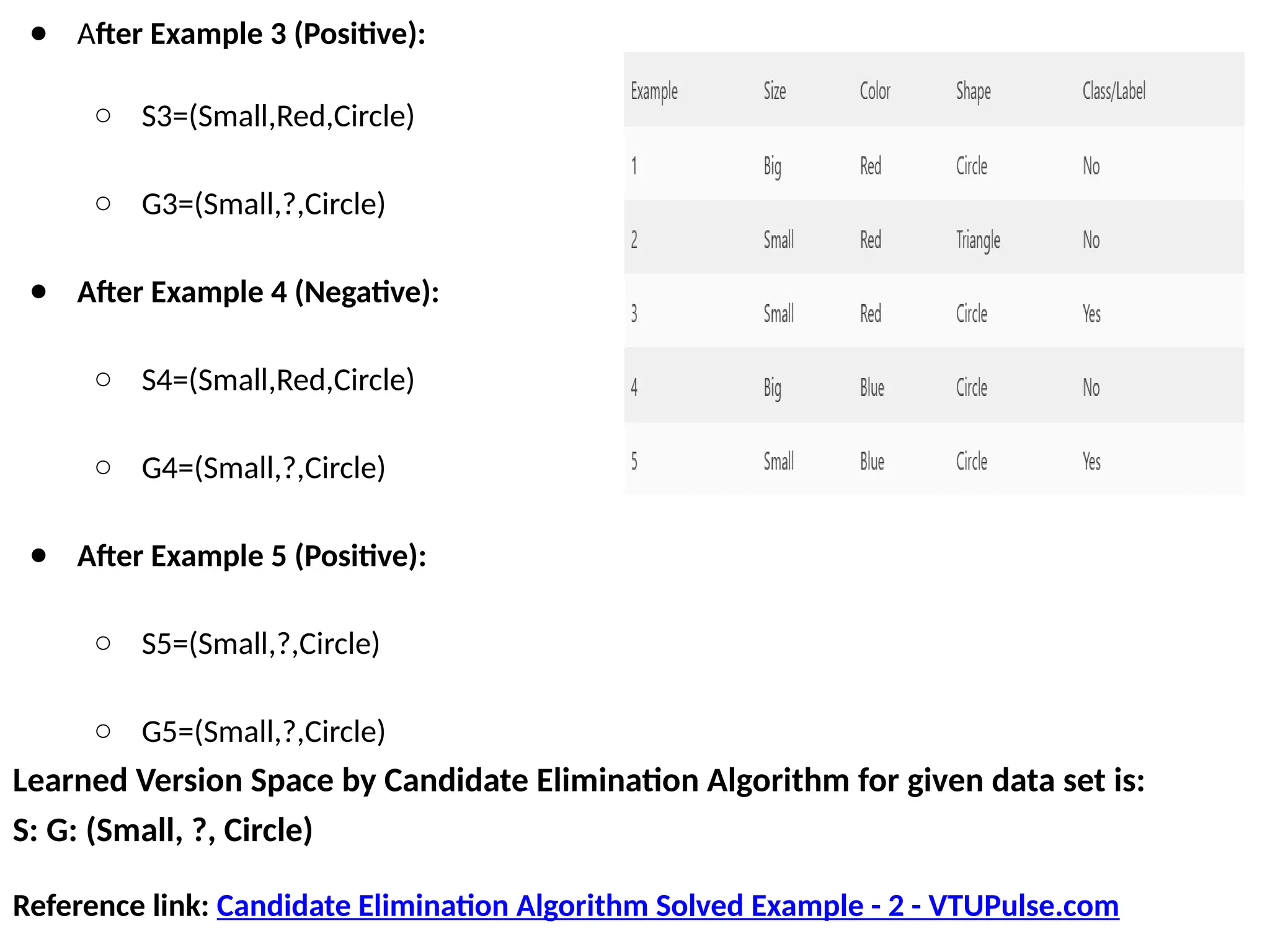
● After Example3 (Positive):
○ S3=(Small,Red,Circle)
○ G3=(Small,?,Circle)
● After Example 4 (Negative):
○ S4=(Small,Red,Circle)
○ G4=(Small,?,Circle)
● After Example 5 (Positive):
○ S5=(Small,?,Circle)
○ G5=(Small,?,Circle)
Learned Version Space by Candidate Elimination Algorithm for given data set is:
S: G: (Small, ?, Circle)
Reference link: Candidate Elimination Algorithm Solved Example - 2 - VTUPulse.com
28.
Try at yourown
You can refer the textbook 1 or can learn from VTU
Pulse website
29.
Remarks on VersionSpaces and Candidate-
Elimination
1.Will Candidate Elimination Converge?
● Candidate Elimination converges to the correct hypothesis if:
○ No errors in training examples.
○ Target concept is representable in hypothesis space H.
● As more examples arrive:
○ Version space shrinks, reducing ambiguity.
○ Learning is complete when S and G converge to a single identical hypothesis.
Explanation:
• If the training data has errors, the correct hypothesis may be eliminated.
• This can lead to an empty version space, meaning no consistent hypothesis exists.
• Empty space also happens when true concept isn’t expressible in H (e.g., when H only
supports conjunctions(and) but true concept is disjunctive(or).
30.
2.What Training ExampleShould Be Requested Next?
● If learner can query for new examples, it should pick examples that help discriminate
among competing hypotheses.
● Good query: one that some hypotheses classify as positive and others as negative.
● Example: Instance (Sunny, Warm, Normal, Light, Warm, Same)
○ If labeled Positive → S expands.
○ If labeled Negative → G contracts.
Explanation (Simple):
● Best strategy: choose examples that split the version space roughly in half each time(half of
the hypotheses predict Positive and half predict Negative.).
● The correct target concept can therefore be found with only log2 VS
∣ ∣
● Similar to “20 Questions” game → each query narrows down the possible hypotheses
fastest.
31.
Example: Query Strategyin Version Space
Step 0: Initial Version Space
∣VS =8 {h1,h2,h3,h4,h5,h6,h7,h8}
∣
Step 1: First Query
● Pick an instance where half predict Positive and half Negative.
● Suppose teacher says Positive → we eliminate all hypotheses that said
Negative.
● Remaining: VS =4 {h1,h2,h3,h4}
∣ ∣
Step 2: Second Query
● Again, choose an instance splitting 4 hypotheses into 2 Positive & 2 Negative.
● Teacher says Negative → eliminate the 2 Positive ones.
● Remaining: VS =2 {h3,h4}
∣ ∣
32.
Step 3: ThirdQuery
● Choose an instance that splits the 2 remaining hypotheses.
● Teacher says Positive → only 1 hypothesis remains.
● Remaining: VS =1 {h3}
∣ ∣
● (Target concept found )
Summary
● Started with 8 hypotheses.
● After 3 queries, found the target concept.
● Matches formula:
log
2 VS
∣ ∣=log
2 (8)=3
33.
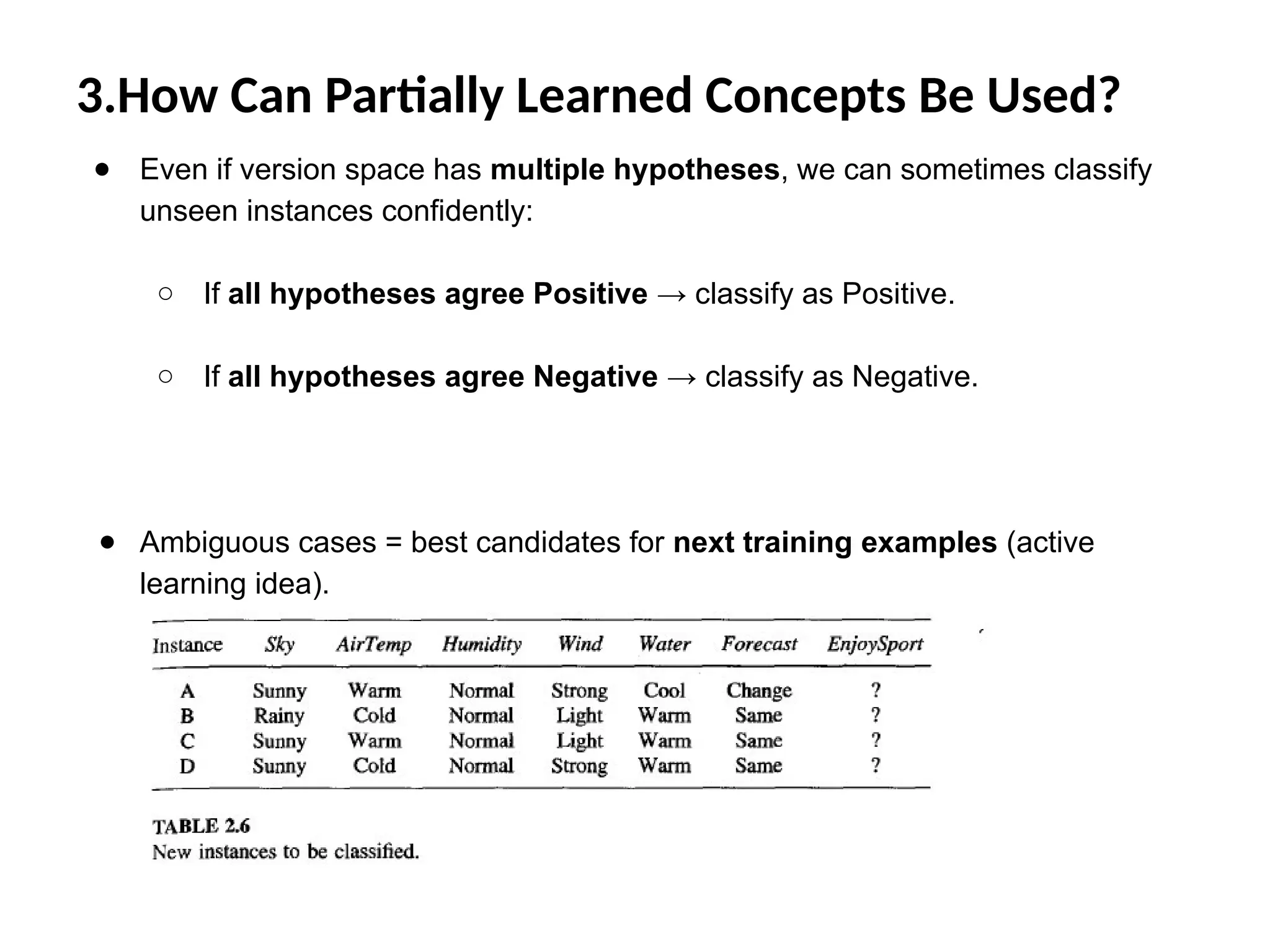
3.How Can PartiallyLearned Concepts Be Used?
● Even if version space has multiple hypotheses, we can sometimes classify
unseen instances confidently:
○ If all hypotheses agree Positive → classify as Positive.
○ If all hypotheses agree Negative → classify as Negative.
● Ambiguous cases = best candidates for next training examples (active
learning idea).
34.
3.How Can PartiallyLearned Concepts Be Used?
Example:
• Instance A: all hypotheses → Positive → safe classification.
• Instance B: all hypotheses → Negative → safe classification.
• Instance C/D: mixed votes → uncertain; may use majority vote
Note: D can be classified as negative using majority of votes but C can’t be explicitly
classified as half of the version space classify this as positive and half as negative
35.
Inductive Bias
1: Whatis Inductive Bias?
● Definition:
Inductive bias = assumptions made by a learner to generalize beyond training data.
● Without bias:
○ Any hypothesis may fit the data.
○ Learner cannot decide how to classify unseen examples.
● Key Question:
Should we make H (hypothesis space) very large (unbiased) or restrict it (biased)?
(Example: “Sky = Sunny OR Cloudy” can’t be represented in conjunctive H → shows
need for expressive H)
36.
2: Biased vs.Unbiased Hypothesis Spaces
● Biased Hypothesis Space
○ Restricts forms of hypotheses (e.g., only conjunctions).
○ May fail if target concept is not representable in H.
● Unbiased Hypothesis Space (Power Set of X):
○ Can represent all possible concepts.
○ But → no generalization beyond training data.
○ S = disjunction of positives, G = negated disjunction of negatives → only training examples
classified.
● Example:
we present three positive examples (x1,x 2, x3) and two negative examples
(x4, x5) to the learner so S boundary will consists of {(x1 v x2 v x3)} and G boundary will
consists of
● Conclusion:
Too restrictive → miss target concept.
Too broad → cannot generalize.
37.
3: The Futilityof Bias-Free Learning
● Key Insight:
A completely unbiased learner has no rational basis for classifying unseen
data.
● Candidate-Elimination works only because of implicit bias:
○ Assumes the target concept is representable as conjunction of
attributes.
● If this assumption is wrong → misclassification is guaranteed.
● Therefore: Every inductive learner must employ some bias.
38.
Deductive Inference
● Generalrule →
Specific case
● If premises are true,
conclusion is
guaranteed
● Example:
○ All humans are
mortal
○ Socrates is a
human
○
⇒ Socrates is
mortal
Inductive Bias
● Extra assumptions
that allow a learner’s
inductive guesses
to be justified as if
they were
deductive proofs
● Minimal set =
smallest
assumptions needed
● Example (Candidate
Elimination):
○ Bias = “Target
concept H”
∈
Inductive Inference
● Specific cases →
General rule
● Conclusion is
probable, not
guaranteed
● Example:
○ Socrates,
Plato, Aristotle
are mortal
○ ⇒ All humans
are mortal ?
4.Deduction vs Induction & Inductive Bias
39.
5: Formal Definitionof Inductive Bias
where the notation y |- z indicates that z follows deductively from y (i.e., that z is
provable from y).
Example with Candidate Elimination:
Bias B = “Target concept c H.”
∈
Training data D = set of labeled examples.
New instance x.
Then classification L(x,D) is provable if and only if all hypotheses in version
space agree.
41.
6: Comparing Strengthof Biases
● Rote-Learner:
○ No bias (only memorizes).
○ Classifies only seen examples.
● Candidate-Elimination:
○ Bias = “c H” (The target concept c is contained in the given hypothesis space H.)
∈
○ Classifies if all hypotheses in version space agree.
● Find-S:
○ Stronger bias:
■ Assumes “c H” (The target concept c is contained in the given hypothesis
∈
space H.)
■ Assumes examples not covered by hypothesis = negative.
● Observation:
○ Stronger bias → more generalization, but riskier if assumptions are wrong.
42.
Thank You
For anyqueries you can reach out to me
Contact no. - 9162884594
Email - amresh@mitkundapura.com
Room no. - AD202(Temporary)
Editor's Notes
#29 can show using page 49
for example,
that the second training example above is incorrectly presented as a negative
example instead of a positive example
Of course, given sufficient additional training
data the learner will eventually detect an inconsistency by noticing that the S and G
boundary sets eventually converge to an empty version space
A similar symptom will appear when the training examples are
correct, but the target concept cannot be described in the hypothesis representation
(e.g., if the target concept is a disjunction of feature attributes and the hypothesis
space supports only conjunctive descriptions).
#39 Minimal set here means:
The smallest collection of assumptions that you need to add to the training data so that the learner’s predictions make logical sense.
If you remove any assumption from this set, you will no longer be able to justify the learner’s predictions.











































































![ANPARA THERMAL POWER STATION[1] sangam.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/anparathermalpowerstation1sangam-251121115219-9261cde4-thumbnail.jpg?width=640&height=640&fit=bounds)






