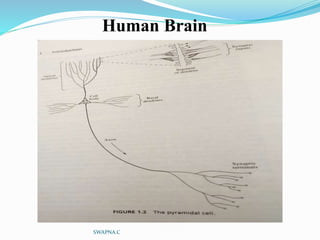
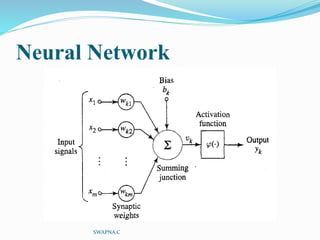
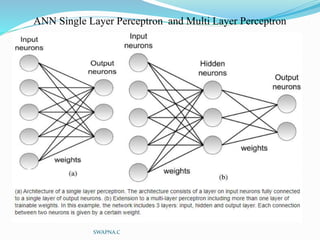
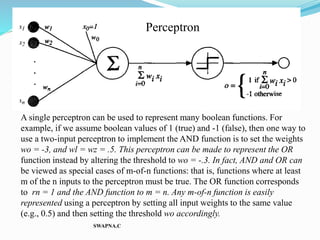
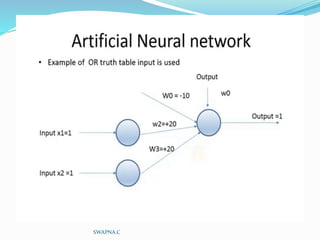
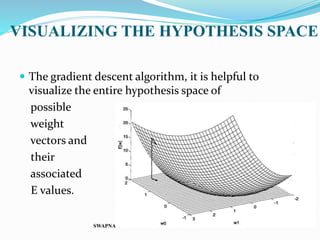
The document discusses artificial neural networks and their biological inspiration from networks of neurons in the human brain. It describes how neural networks are built from interconnected simple units that take input and produce output. The perceptron model of a neural network unit is introduced, which learns by modifying connection weights based on errors. Neural networks can represent various functions and problems like handwriting recognition. The backpropagation algorithm is commonly used for training multilayer neural networks by calculating gradients to minimize error.