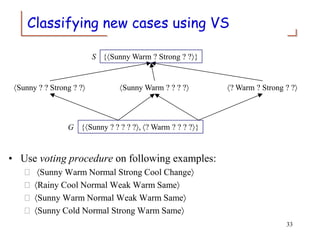
The document discusses concept learning through inductive logic. It introduces the concept learning task of predicting when a person will enjoy a sport based on attributes of the day. It describes representing hypotheses as conjunctions of attribute values and the version space approach of tracking the most specific and most general consistent hypotheses. The document explains the candidate elimination algorithm, which uses positive and negative examples to generalize the specific boundary and specialize the general boundary, respectively, until the version space is fully resolved.











































































































![Attack surfaces and attack tress[inform]](https://cdn.slidesharecdn.com/ss_thumbnails/lecture03-260108015941-a4dee53b-thumbnail.jpg?width=640&height=640&fit=bounds)
