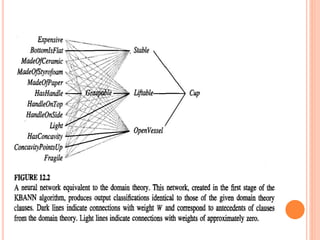
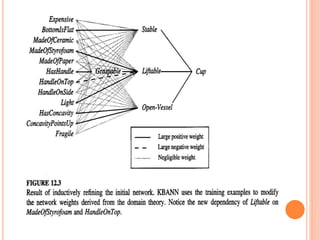
The document discusses combining inductive and analytical learning methods. Inductive methods like decision trees and neural networks seek general hypotheses based solely on training data, while analytical methods like PROLOG-EBG seek hypotheses based on prior knowledge and training data. The document argues that combining these approaches could overcome their individual limitations by using prior knowledge to guide inductive learning methods. It examines using prior knowledge to initialize hypotheses, alter the search objective, and modify the search operators of inductive learners. As an example, it describes the KBANN algorithm, which initializes a neural network to perfectly fit a domain theory before refining it inductively to the training data.