1) The document discusses concept learning, which involves inferring a Boolean function from training examples. It focuses on a concept learning task where hypotheses are represented as vectors of constraints on attribute values.
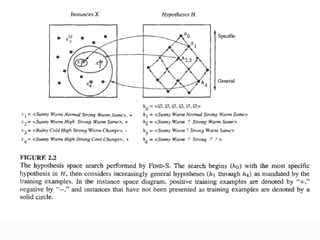
2) It describes the FIND-S algorithm, which finds the most specific hypothesis consistent with positive examples by generalizing constraints. However, FIND-S has limitations like ignoring negative examples.
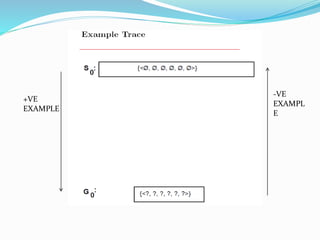
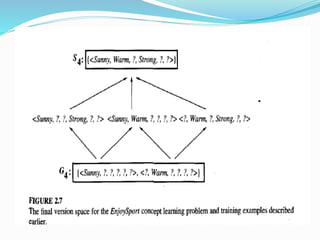
3) The Candidate-Elimination algorithm represents the version space of all hypotheses consistent with examples to address FIND-S limitations. It outputs the version space rather than a single hypothesis.