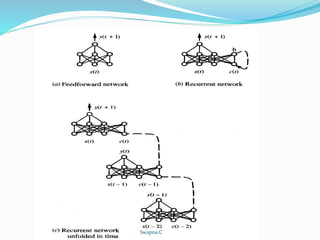
The document discusses various advanced topics in artificial neural networks including alternative error functions, error minimization procedures, recurrent networks, and dynamically modifying network structure. It describes adding penalty terms to the error function to reduce weights and overfitting, using line search and conjugate gradient methods for error minimization, how recurrent networks can capture dependencies over time, and algorithms for growing or pruning network complexity like cascade correlation.