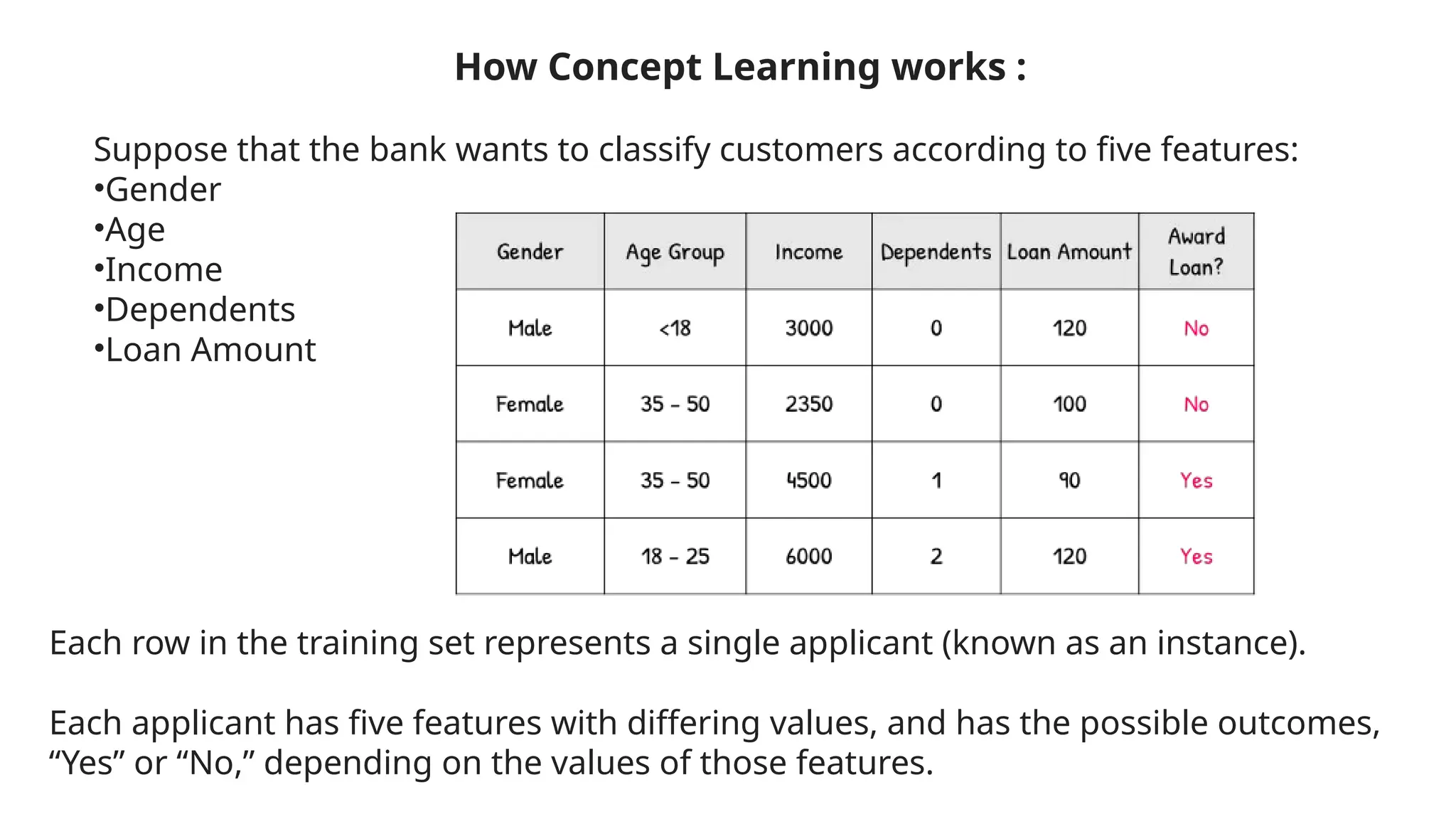
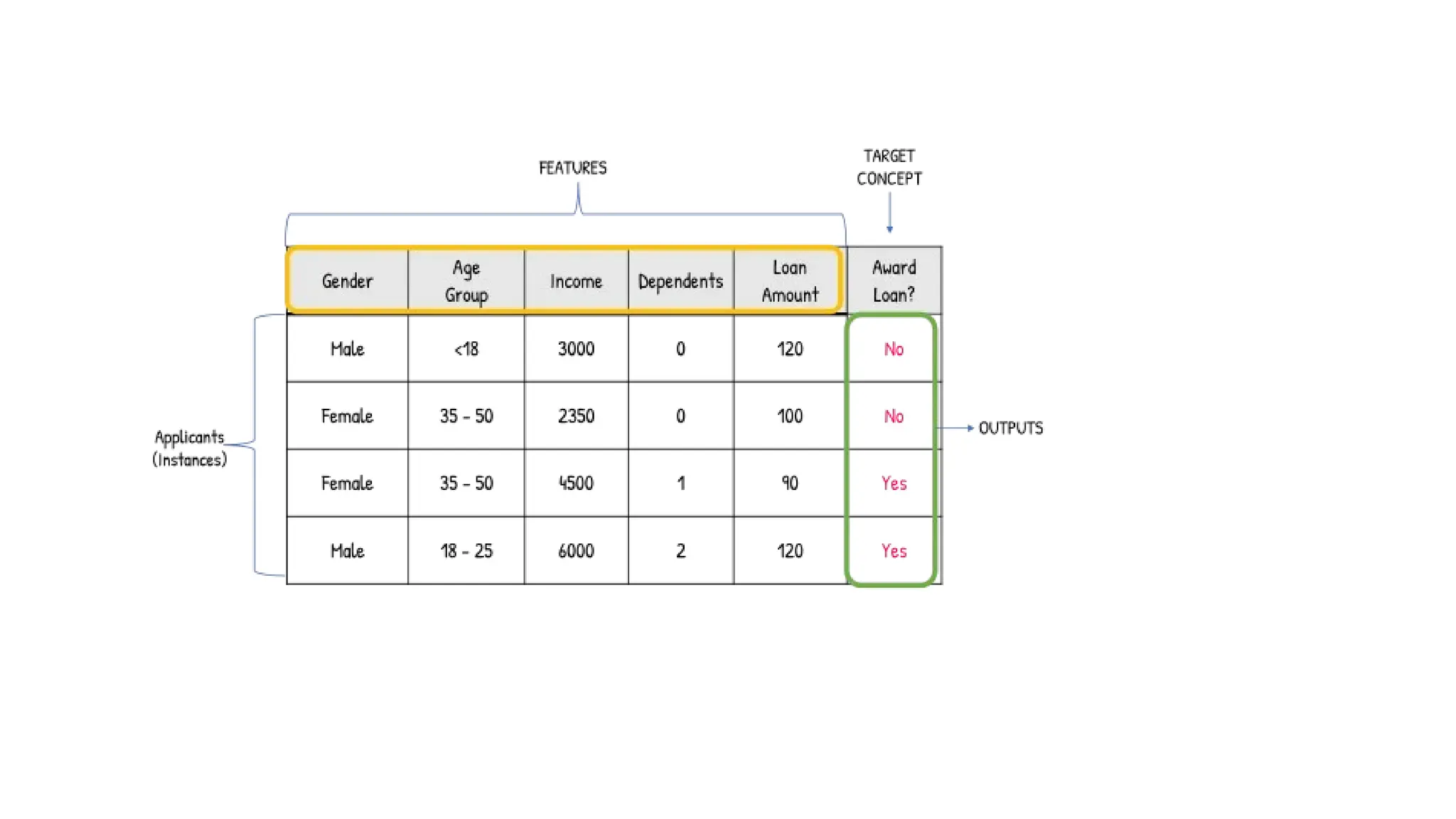
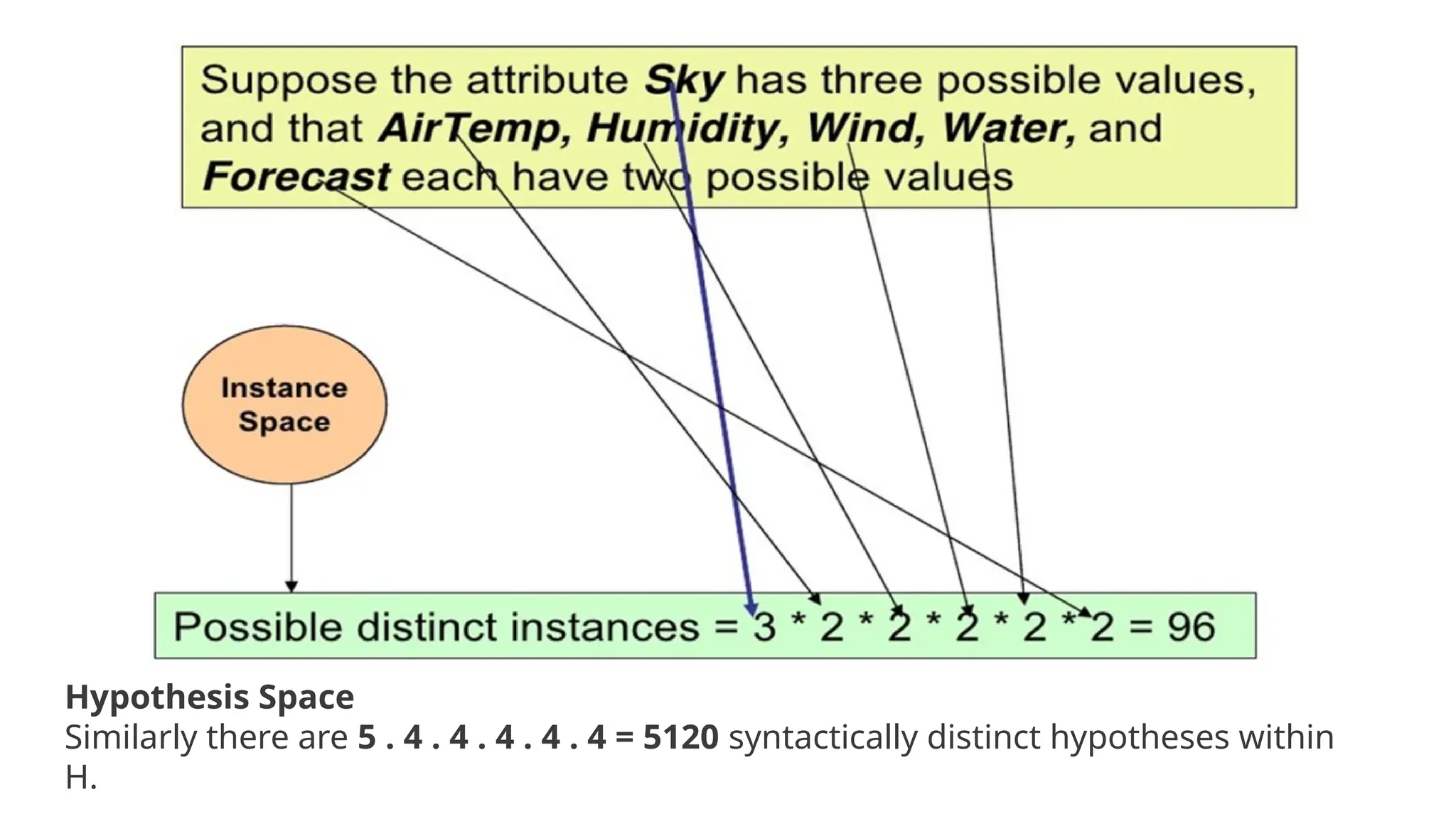
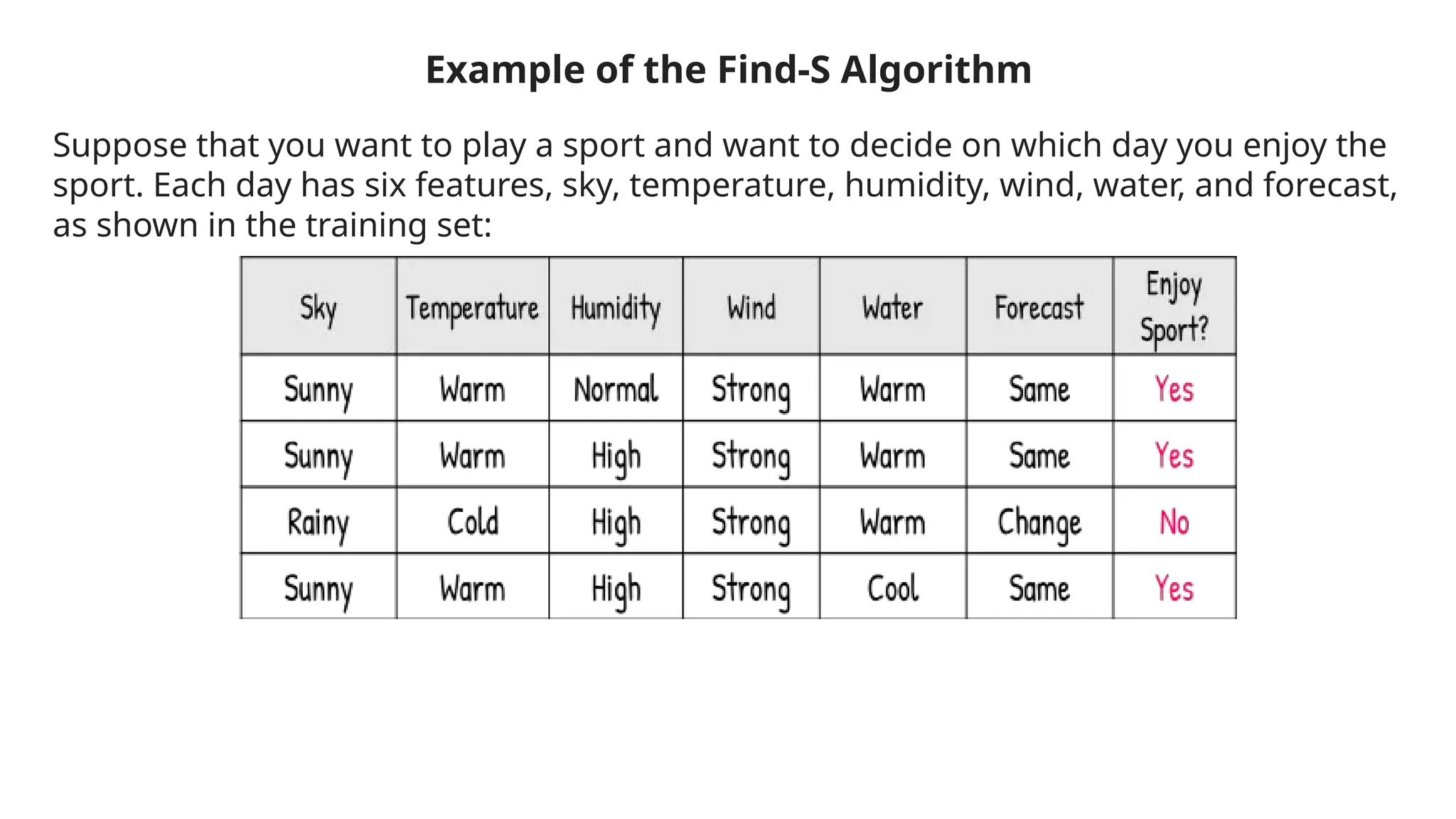
Concept learning is a process for machines to acquire knowledge about categories based on examples, enabling classification of new instances. It involves training data, hypothesis space, generalization to unseen data, and evaluation to avoid overfitting, with applications in areas like spam filtering and medical diagnosis. The process includes methods like the find-s algorithm to identify the best hypothesis that accurately represents the concept being learned.