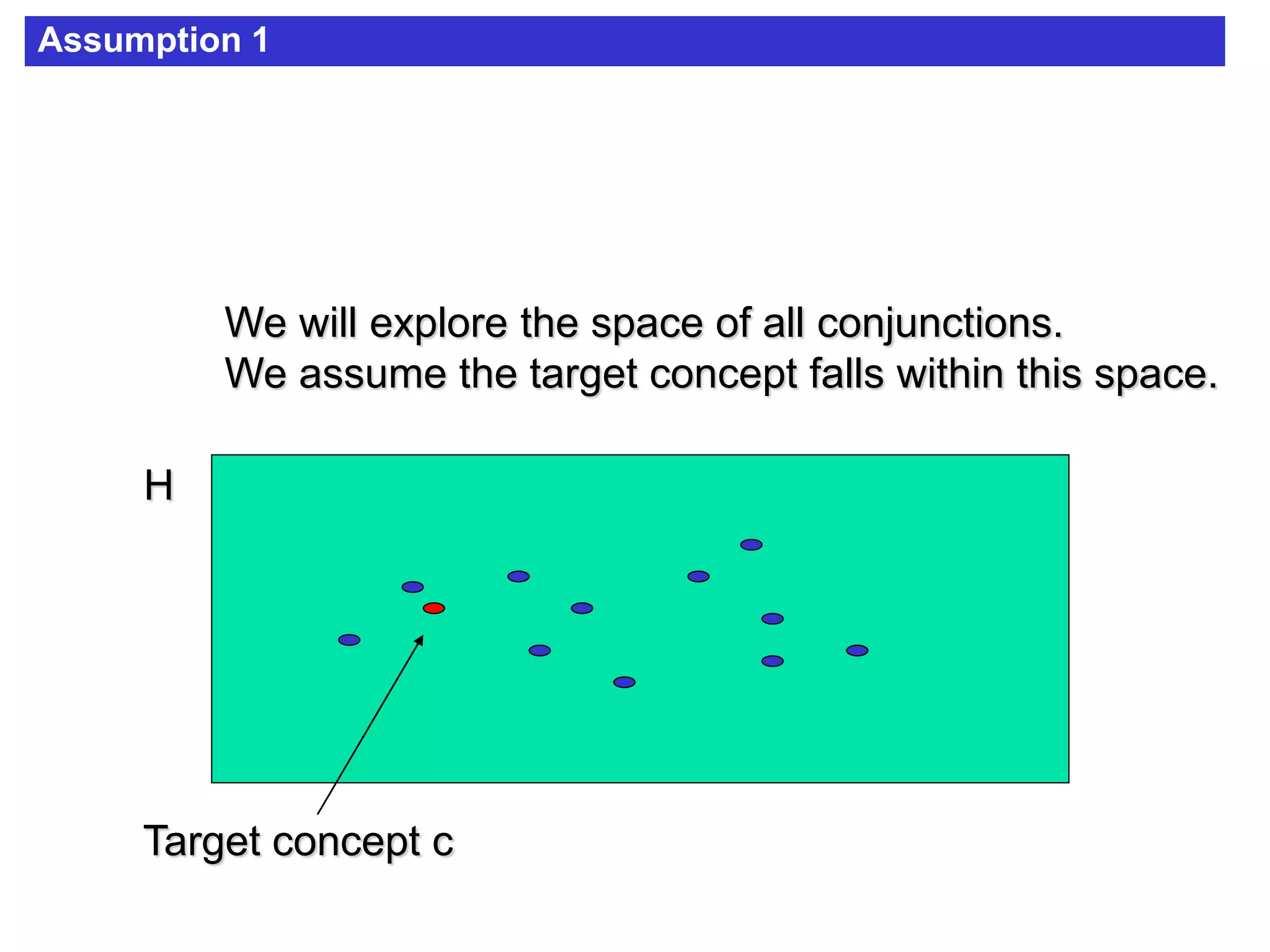
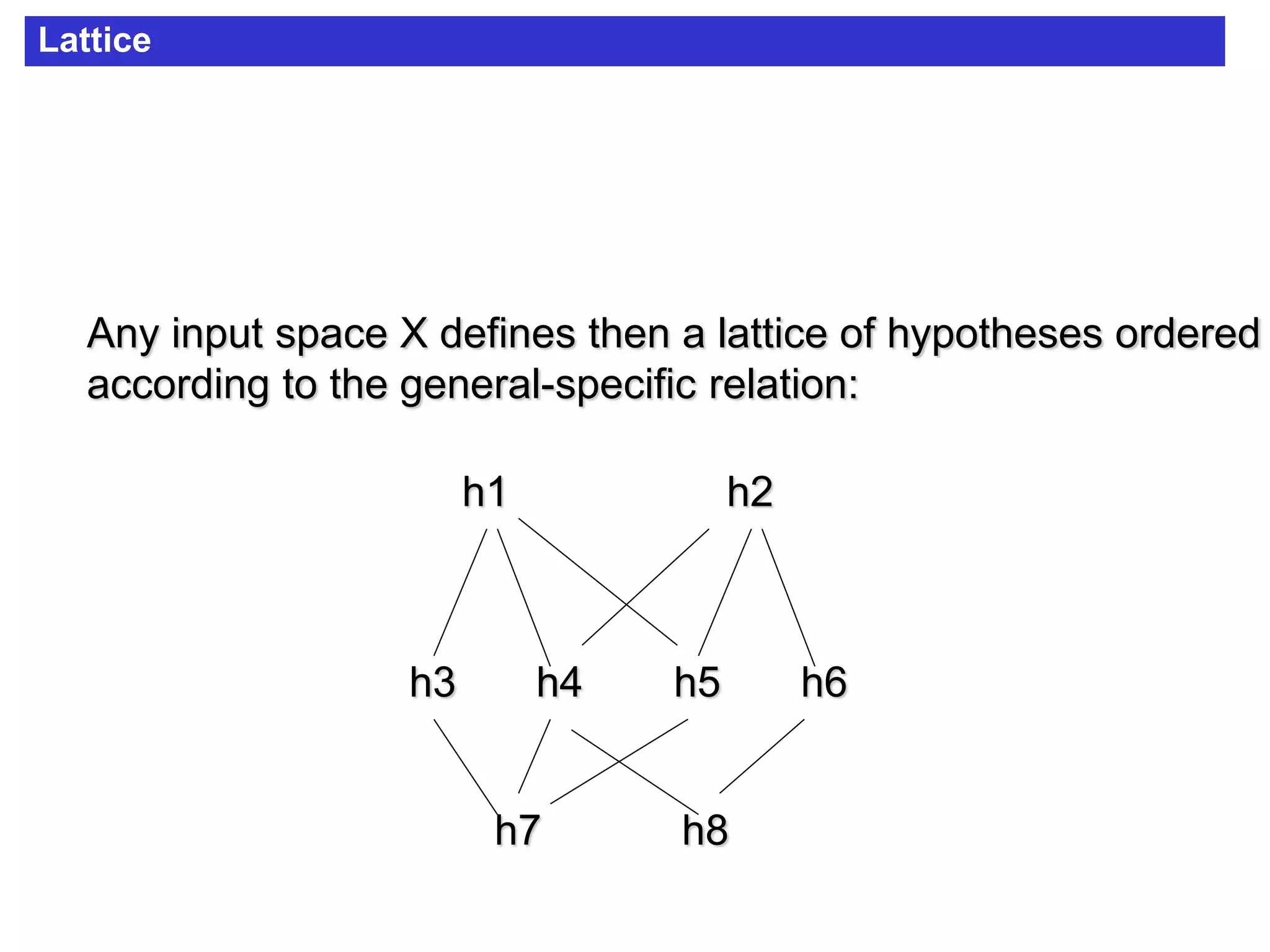
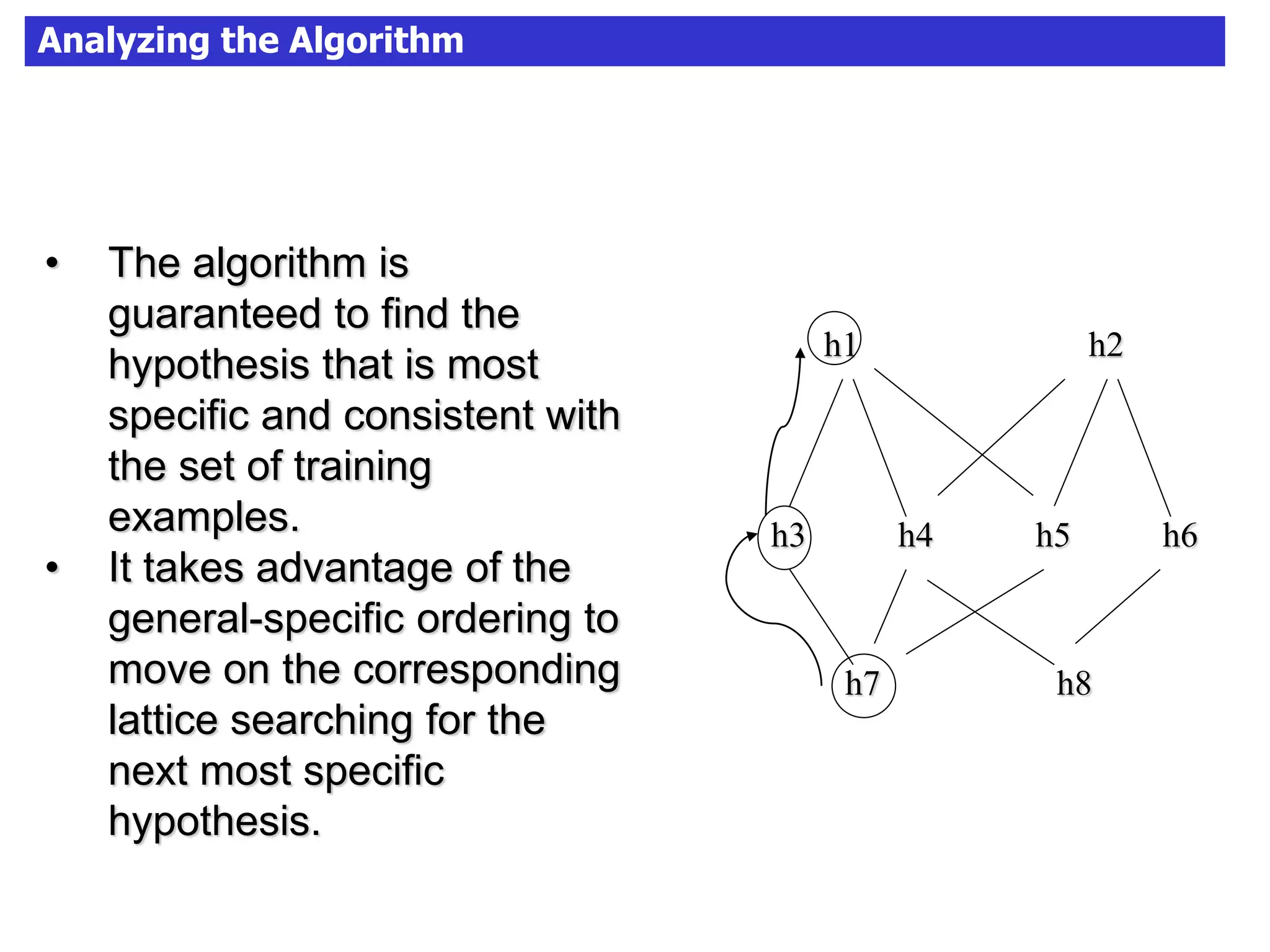
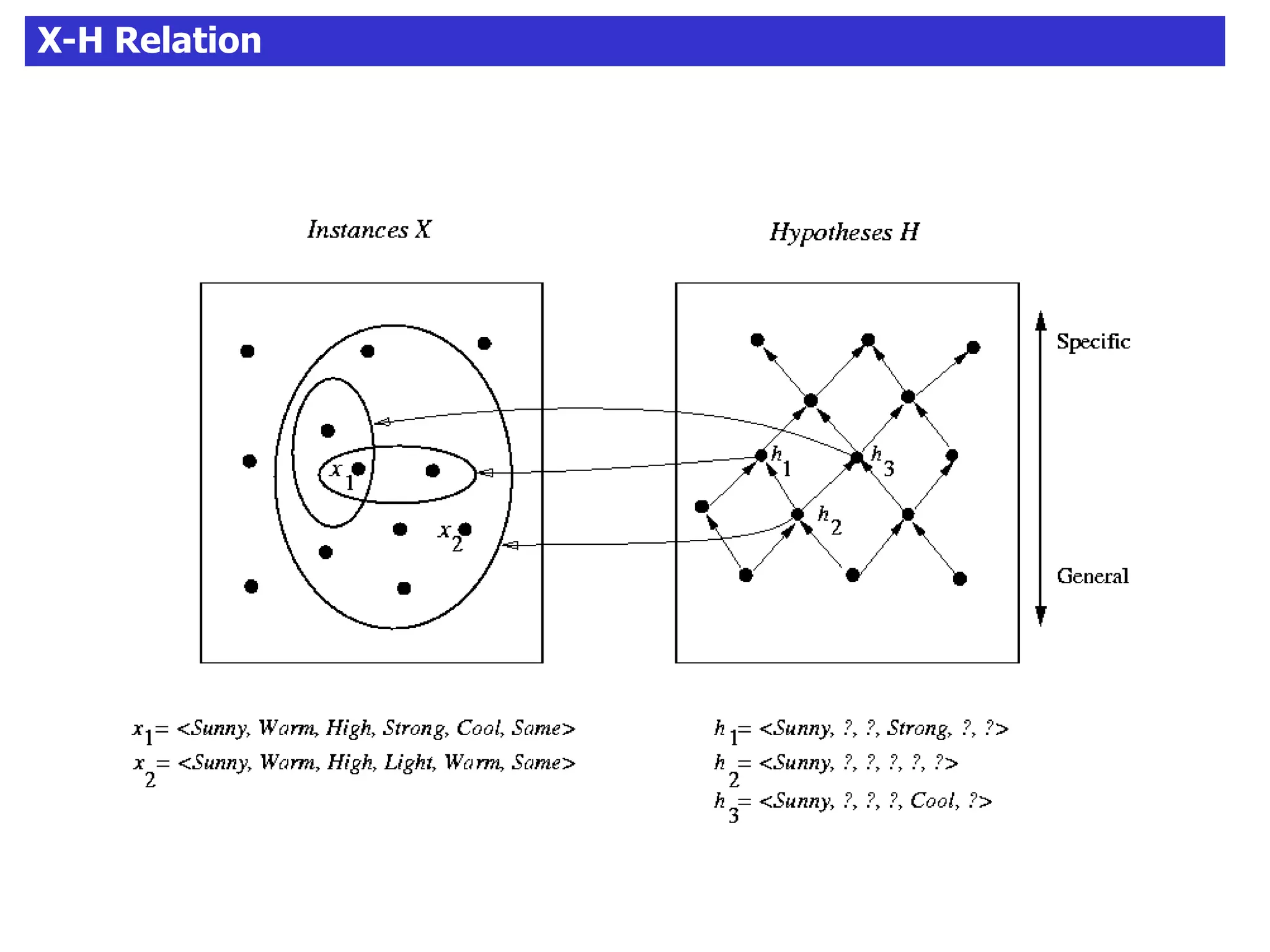
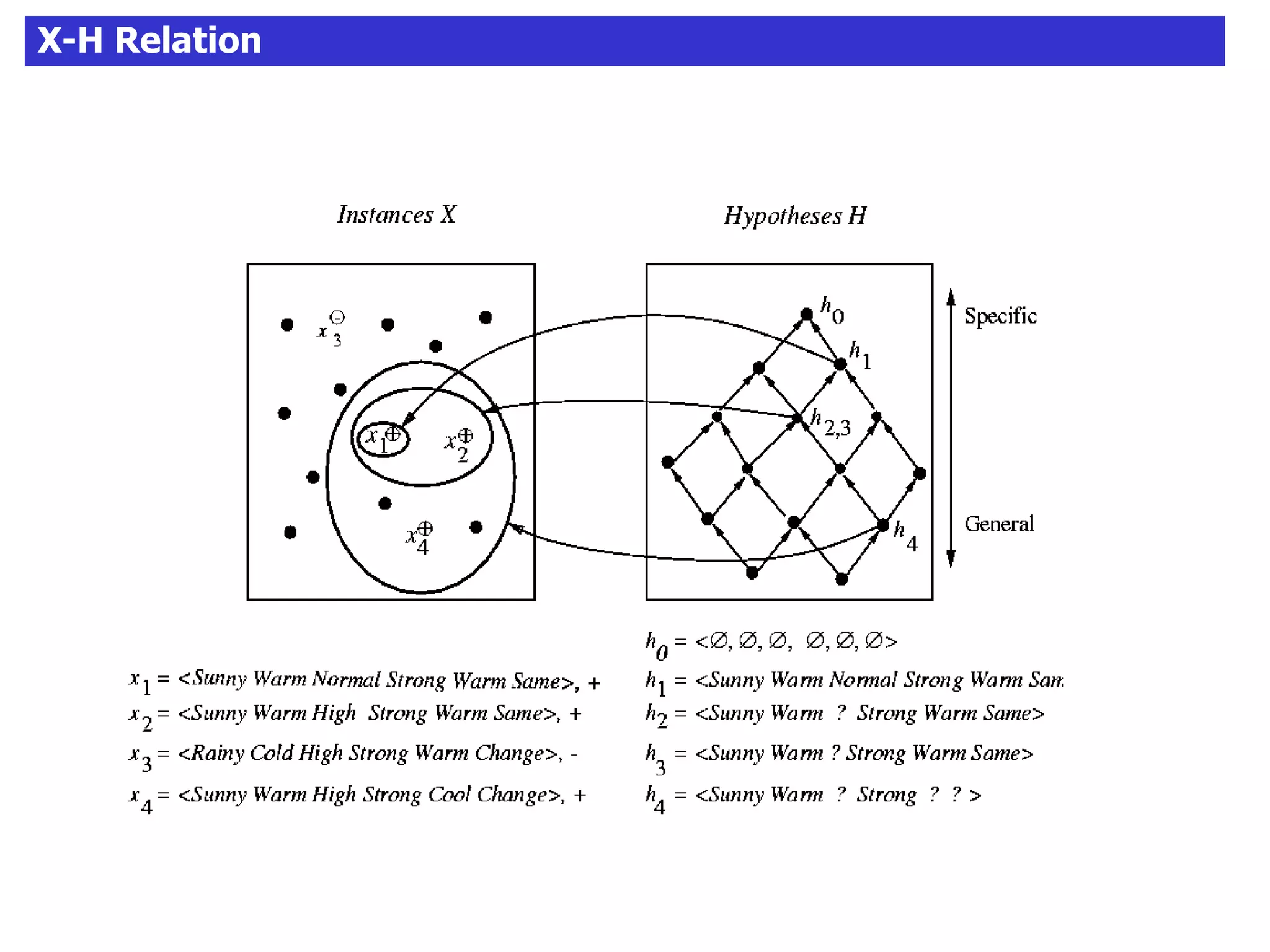
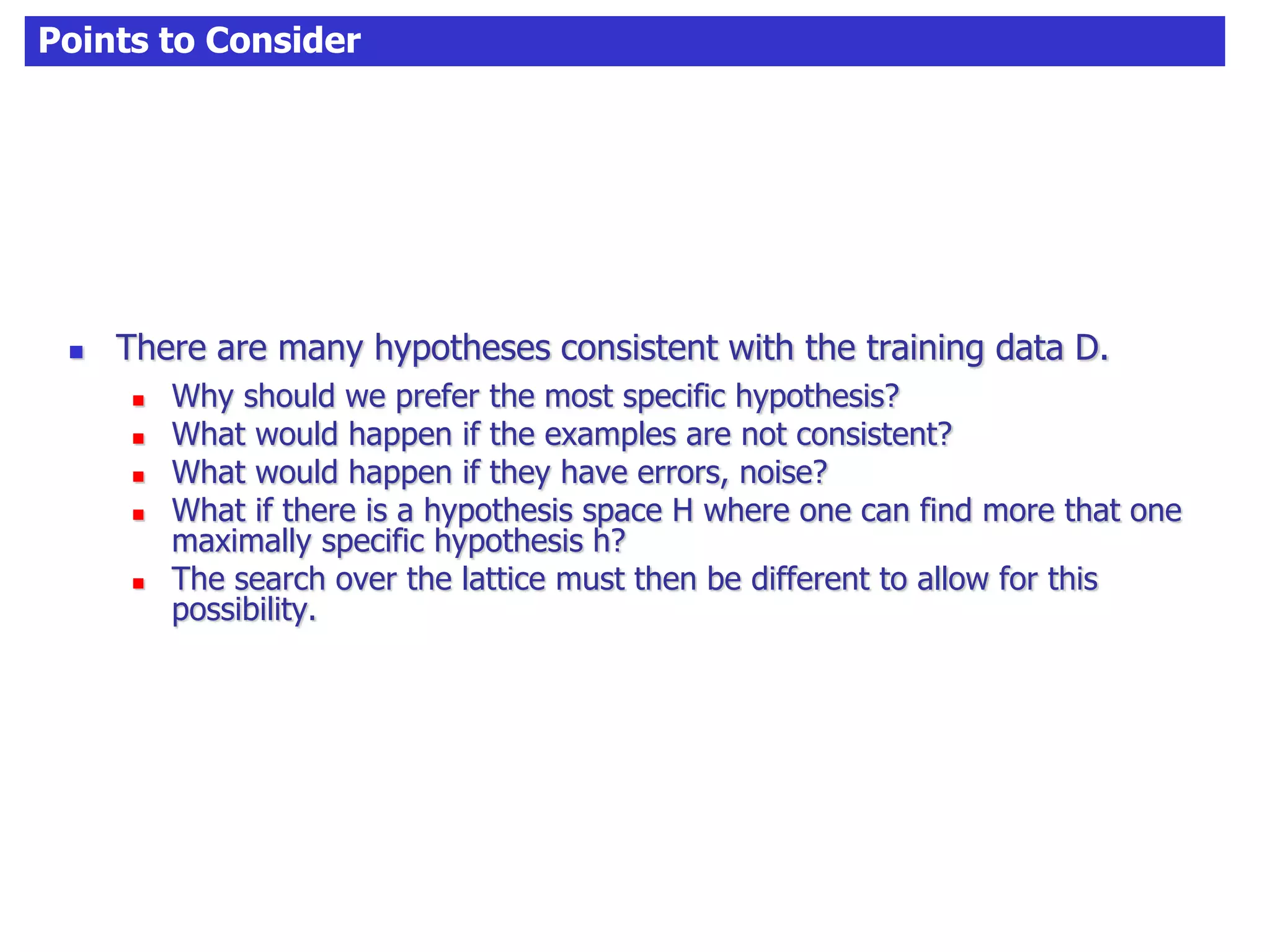
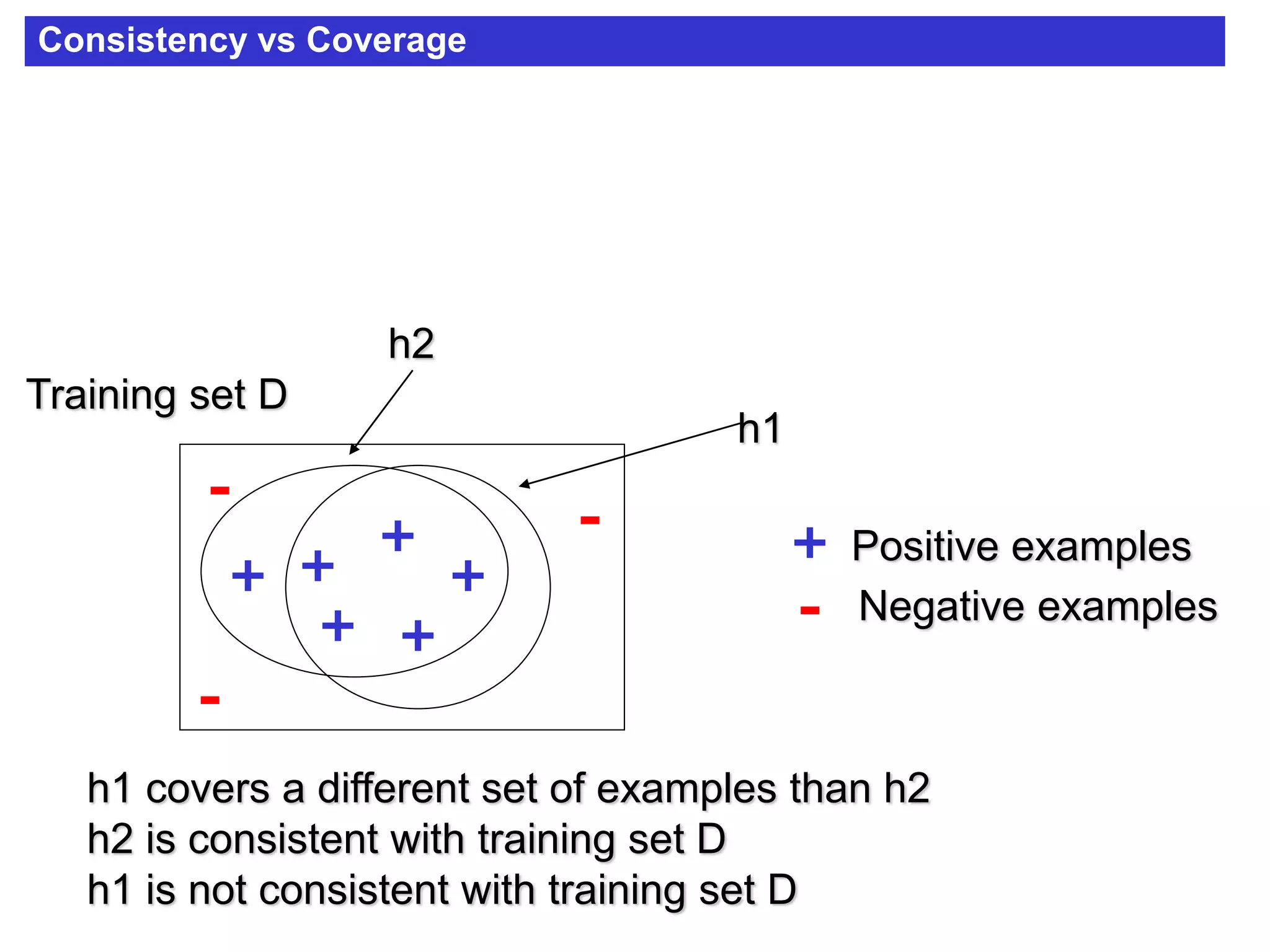
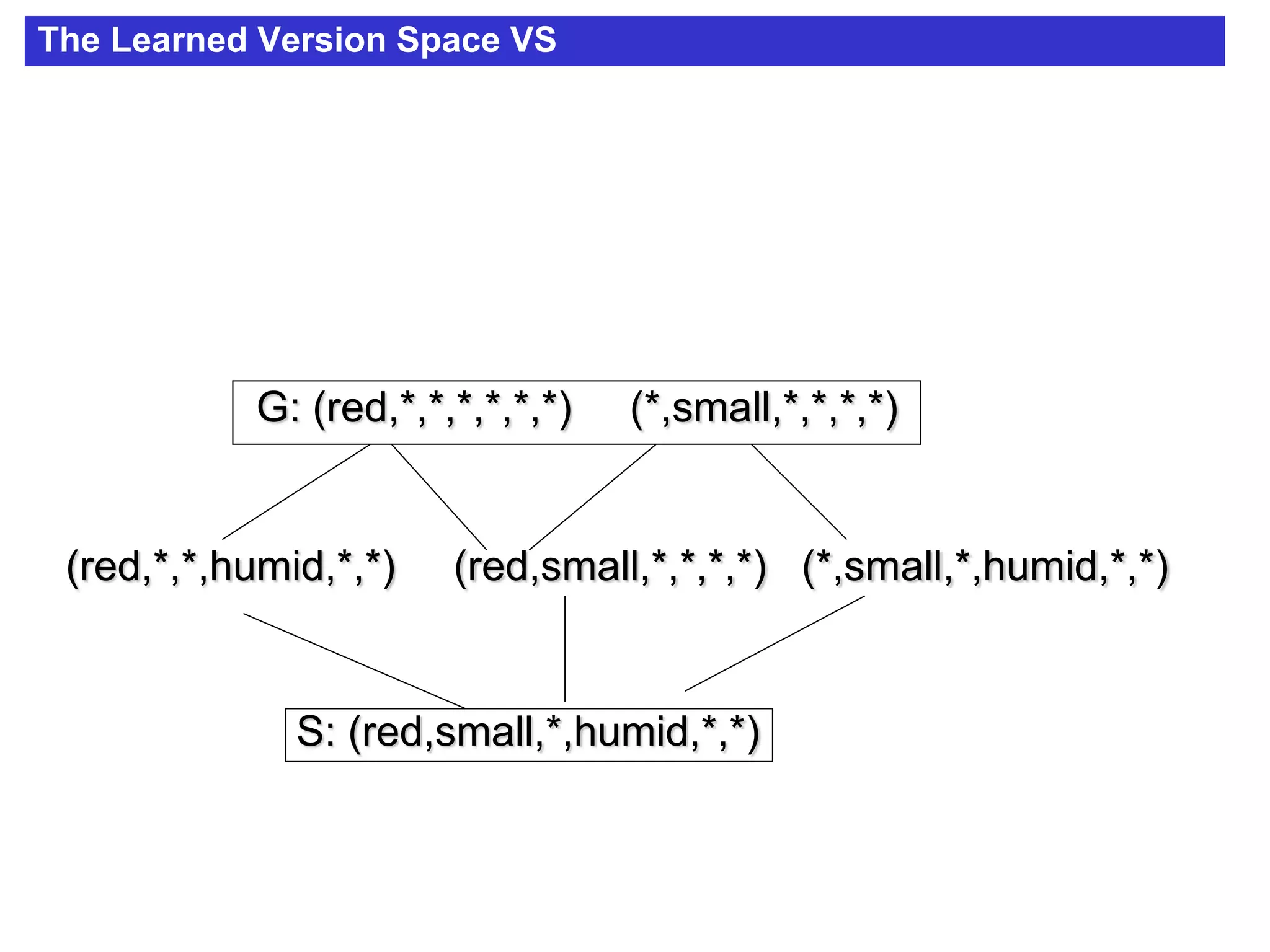
The document discusses concept learning algorithms. It introduces the problem of concept learning as inducing a function to classify examples into categories based on their attributes. The Candidate Elimination Algorithm (CEA) is presented as a method for finding all hypotheses consistent with training examples without enumerating them. CEA works by maintaining the most specific (S) and most general (G) consistent hypotheses. It updates S and G in response to positive and negative examples.





































































![11.[29 35]a unique common fixed point theorem under psi varphi contractive co...](https://cdn.slidesharecdn.com/ss_thumbnails/11-29-35auniquecommonfixedpointtheoremunderpsivarphicontractiveconditioninpartialmetricspacesusingrationalexpressions-120512235650-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)







































































