Downloaded 39 times
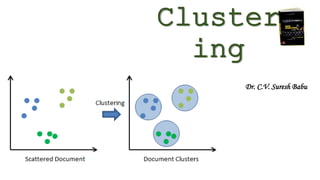
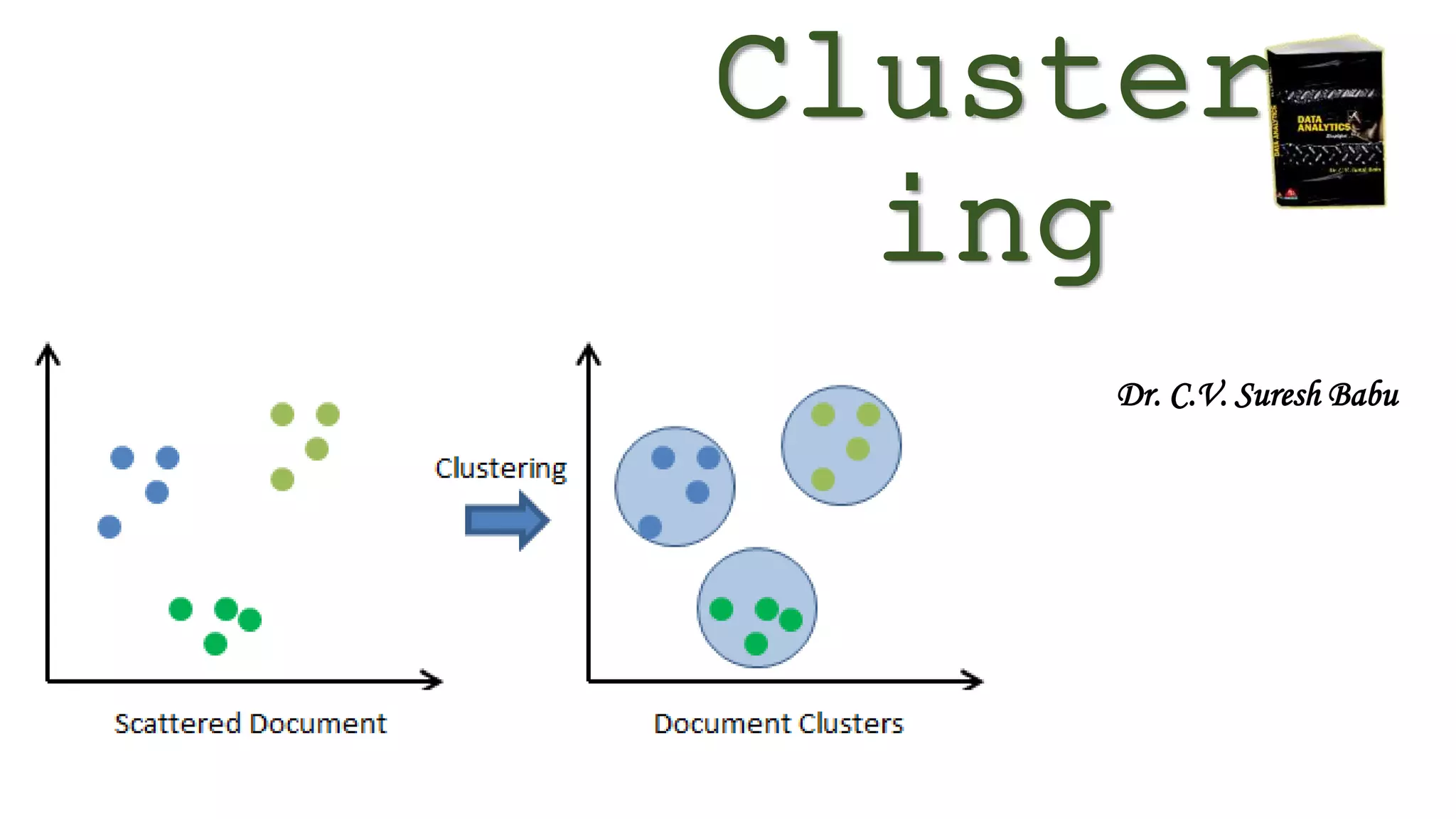

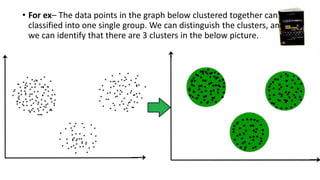










This document discusses clustering, which is the task of grouping data points into clusters so that points within the same cluster are more similar to each other than points in other clusters. It describes different types of clustering methods, including density-based, hierarchical, partitioning, and grid-based methods. It provides examples of specific clustering algorithms like K-means, DBSCAN, and discusses applications of clustering in fields like marketing, biology, libraries, insurance, city planning, and earthquake studies.







































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)















