UNIT-III : CLUSTERING
*4
Clustering- K Means Clustering- Supervised
Learning after Clustering- Density Based Clustering
Methods- Hierarchical Based clustering methods-
Partitioning methods - Grid based methods.
Dimensionality Reduction : Linear Discriminant
Analysis - Principal Component Analysis.
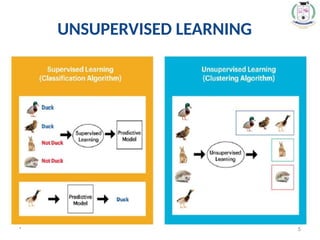
Clustering
• Clustering orcluster analysis is a machine learning technique,
which groups the unlabelled dataset.
• It can be defined as "A way of grouping the data points into
different clusters, consisting of similar data points. The
objects with the possible similarities remain in a group that
has less or no similarities with another group.“
• Finding some similar patterns in the unlabelled dataset such
as shape, size, color, behavior, etc., and divides them as per
the presence and absence of those similar patterns.
* 6
7.
• It isan unsupervised learning method, hence no supervision is
provided to the algorithm, and it deals with the unlabeled
dataset.
• After applying this clustering technique, each cluster or group
is provided with a cluster-ID. ML system can use this id to
simplify the processing of large and complex datasets.
• The clustering technique is commonly used for statistical data
analysis.
Note: Clustering is somewhere similar to the classification algorithm, but the
difference is the type of dataset that we are using. In classification, we
work with the labeled data set, whereas in clustering, we work with the
unlabelled dataset.
* 7
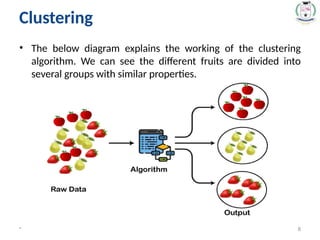
Clustering
8.
• The belowdiagram explains the working of the clustering
algorithm. We can see the different fruits are divided into
several groups with similar properties.
* 8
Clustering
9.
• A goodclustering method will produce high quality clusters
– high intra-class similarity: cohesive within clusters
– low inter-class similarity: distinctive between clusters
• The quality of a clustering method depends on
– the similarity measure used by the method
– its implementation, and
– its ability to discover some or all of the hidden patterns.
• Clustering is a form of learning by observation rather than
learning by examples.
* 9
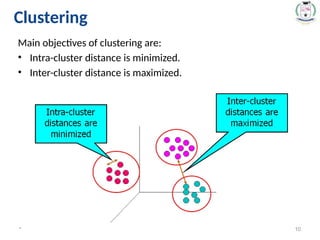
Clustering
10.
Main objectives ofclustering are:
• Intra-cluster distance is minimized.
• Inter-cluster distance is maximized.
* 10
Clustering
11.
Applications of Clustering
•In Identification of Cancer Cells: The clustering algorithms are
widely used for the identification of cancerous cells. It divides
the cancerous and non-cancerous data sets into different
groups.
• In Search Engines: Search engines also work on the clustering
technique. The search result appears based on the closest
object to the search query. It does it by grouping similar data
objects in one group that is far from the other dissimilar
objects. The accurate result of a query depends on the quality
of the clustering algorithm used.
* 11
12.
Applications of Clustering
•Customer Segmentation: It is used in market research to
segment the customers based on their choice and
preferences.
• In Biology: It is used in the biology stream to classify different
species of plants and animals using the image recognition
technique.
• In Land Use: The clustering technique is used in identifying
the area of similar lands use in the GIS database. This can be
very useful to find that for what purpose the particular land
should be used, that means for which purpose it is more
suitable.
* 12
13.
Applications of Clustering
•Theclustering technique can be widely used in various tasks.
Some most common uses of this technique are:
– Market Segmentation
– Statistical data analysis
– Social network analysis
– Image segmentation
– Anomaly detection, etc.
•Apart from these general usages, it is used by the Amazon in its
recommendation system to provide the recommendations as per
the past search of products.
•Netflix also uses this technique to recommend the movies and
web-series to its users as per the watch history.
* 13
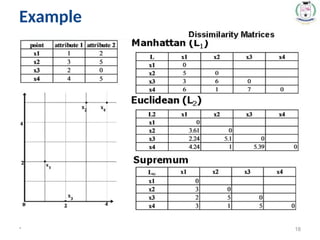
Similarity and Dissimilarity
•Distances are normally used to measure the similarity or
dissimilarity between to data objects.
• Some popular distances are based on Minkowski distance
(Lp or Lh norm)
* 15
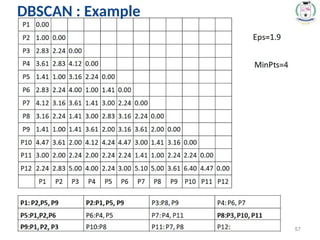
• Given twoobjects represented by the tuples (22, 1, 42, 10)
and (20, 0, 36, 8):
1. Compute the Euclidean distance between the two
objects.
2. Compute the Manhattan distance between the two
objects.
3. Compute the Minkowski distance between the two
objects using q=3.
* 19
Problem 1
20.
1. Compute theEuclidean distance between the two objects.
* 20
(22, 1, 42, 10) and (20, 0, 36, 8)
Problem 1
21.
2. Compute theManhattan distance between the two objects.
= 2+1+6+2
= 11
3. Compute the Minkowski distance between the two objects
using q=3.
* 21
Problem 1
22.
Given 5-dimensional numericsamples A=(1,0,2,5,3) and
B=(2,1,0,3,-1).
1. Compute the Euclidean distance between the two
objects.
2. Compute the Manhattan distance between the two
objects.
3. Compute the Supremum distance.
* 22
Problem 2
23.
Types of ClusteringMethods
• The clustering methods are broadly divided into Hard
clustering (datapoint belongs to only one group) and Soft
Clustering (data points can belong to another group also).
• Below are the main clustering methods used in Machine
learning:
– Partitioning Clustering (Centroids-based Clustering)
– Density-Based Clustering (Model-based methods)
– Distribution Model-Based Clustering (Distribution Model-
Based)
– Hierarchical Clustering (Connectivity-based Clustering)
– Fuzzy Clustering (Soft Clustering)
– Supervised Clustering (Constraint-based Clustering)
* 23
24.
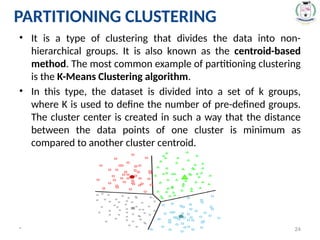
PARTITIONING CLUSTERING
• Itis a type of clustering that divides the data into non-
hierarchical groups. It is also known as the centroid-based
method. The most common example of partitioning clustering
is the K-Means Clustering algorithm.
• In this type, the dataset is divided into a set of k groups,
where K is used to define the number of pre-defined groups.
The cluster center is created in such a way that the distance
between the data points of one cluster is minimum as
compared to another cluster centroid.
* 24
25.
DENSITY-BASED CLUSTERING
• Thedensity-based clustering method connects the highly-
dense areas into clusters, and the arbitrarily shaped
distributions are formed as long as the dense region can be
connected.
• This algorithm does it by identifying different clusters in the
dataset and connects the areas of high densities into clusters.
The dense areas in data space are divided from each other by
sparser areas.
• These algorithms can face difficulty in clustering the data
points if the dataset has varying densities and high
dimensions.
* 25
26.
HIERARCHICAL CLUSTERING
• Hierarchicalclustering can be used as an alternative for the
partitioned clustering as there is no requirement of pre-
specifying the number of clusters to be created.
• In this technique, the dataset is divided into clusters to create
a tree-like structure, which is also called a Dendrogram.
1. Top-down [Divisive Approach]
2. Bottom-up [Agglomerative Approach]
* 26
27.
DISTRIBUTION MODEL-BASED CLUSTERING
•In the distribution model-based clustering method, the data is
divided based on the probability of how a dataset belongs to a
particular distribution. The grouping is done by assuming
some distributions commonly Gaussian Distribution.
• The example of this type is the Expectation-Maximization
Clustering algorithm that uses Gaussian Mixture Models
(GMM).
* 27
28.
FUZZY CLUSTERING
• Fuzzyclustering is a type of soft method in which a data
object may belong to more than one group or cluster.
• Each dataset has a set of membership coefficients, which
depend on the degree of membership to be in a cluster.
• Fuzzy C-means algorithm is the example of this type of
clustering; it is sometimes also known as the Fuzzy k-means
algorithm.
• Fuzzy clustering can be used with datasets where the
variables have a high level of overlap.
• It is a strongly preferred algorithm for Image Segmentation,
especially in bioinformatics.
* 28
29.
* 29
• Incertain business scenarios, we might be required to
partition the data based on certain constraints.
• Here is where a supervised version of clustering machine
learning techniques come into play.
• A constraint is defined as the desired properties of the
clustering results, or a user’s expectation on the clusters.
• This can be in terms of a fixed number of clusters, or, the
cluster size, or, important dimensions (variables) that are
required for the clustering process.
• Usually, tree-based, Classification machine learning
algorithms like Decision Trees, Random Forest, and Gradient
Boosting, etc. are made use of to attain constraint-based
clustering.
SUPERVISED CLUSTERING
30.
• Given adatabase of n objects or data tuples , a partitioning
method constructs k partitions of the data , where each
partition represents a cluster and k<=n.
• k is the number of groups after the classification of objects.
There are some requirements which need to be satisfied with
this Partitioning Clustering Method :
– Each group must contain at least one object
– Each object must belong to exactly one group.
* 30
PARTITIONING CLUSTERING METHOD
31.
• Technique namedIterative Relocation is employed, which
means the object will be moved from one group to another to
improve the partitioning.
• The general criterion of a good partitioning is that object in
the same clusters are “close” or related to each other ,
whereas objects of different clusters are “far apart” or very
different.
• Example:
– K-MEANS, K--MEDIODS ,CLARANS
* 31
PARTITIONING CLUSTERING METHOD
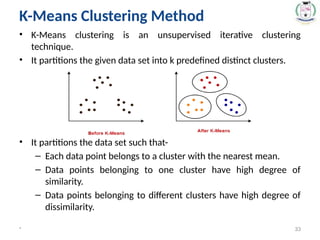
K-Means Clustering Method
•K-Means clustering is an unsupervised iterative clustering
technique.
• It partitions the given data set into k predefined distinct clusters.
• It partitions the data set such that-
– Each data point belongs to a cluster with the nearest mean.
– Data points belonging to one cluster have high degree of
similarity.
– Data points belonging to different clusters have high degree of
dissimilarity.
* 33
34.
• If kis given, the K-means algorithm can be executed in the
following steps:
– Partition of objects into k non-empty subsets
– Identifying the cluster centroids (mean point) of the
current partition.
– Assigning each point to a specific cluster
– Compute the distances from each point and allot points to
the cluster where the distance from the centroid is
minimum.
– After re-allotting the points, find the centroid of the new
cluster formed.
* 34
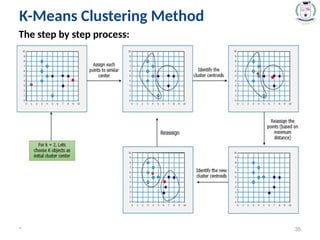
K-Means Clustering Method
35.
The step bystep process:
* 35
K-Means Clustering Method
• The generalobjective is to obtain the partition that ,for a fixed
number of clusters, minimizes the total square error.
• Suppose that the given dataset of N samples in an n-
dimensional space has been partitioned into k-clusters {c1 ,
c2 ,... ck }.
• Each ck has nk samples and each sample has exactly one
cluster, so that
• The mean vector MK of cluster Ck is defined as the centroid of
the cluster
where Xik is the ith
sample belonging to cluster Ck
* 37
K-Means Clustering Method
38.
• The squareerror for cluster Ck is the sum of the squared
Euclidean distance between each sample in Ck and its
centroid. This error is also called the within-cluster variation.
• The square-error for the entire clustering space containing k
clusters is the sum of the within-cluster variations:
* 38
K-Means Clustering Method
39.
EXAMPLE : K-MeansClustering Method
Consider the data points X1={1,0} X2={0,1} X3={2,1} X4={3,3}
Clusters: C1={X1 ,X3} C2={X2 ,X4}
a. Apply one iteration of K-means partitioning clustering
algorithm.
b. Observe the change in Total Square Error?
c. Apply second iteration of K-means partitioning clustering
algorithm.
* 39
EXAMPLE : K-Means Clustering Method
40.
Step 1: Thecentroid for the clusters C1 and C2 are:
* 40
X1={1,0} X2={0,1} X3={2,1} X4={3,3}
Clusters: C1={X1 ,X3} C2={X2 ,X4}
EXAMPLE : K-Means Clustering Method
41.
Step 2: Withincluster variation after initial random distribution
of samples:
* 41
EXAMPLE : K-Means Clustering Method
42.
Step 3: Totalsquare error
Reassign all samples depending on minimum distance from
centroid M1 and M2 ,the new redistribution of samples inside
clusters will be:
1. X1={1,0}
* 42
EXAMPLE : K-Means Clustering Method
• New Clusters:C1={X1 , X2 ,X3} C2={X4}
* 44
EXAMPLE : K-Means Clustering Method
45.
• Total squareerror
• After first iteration, the total square error is significantly
reduced from the value 7.5 to 2.668.
* 45
EXAMPLE : K-Means Clustering Method
46.
• New centroids:
1.X1={1,0}
2. X2={0,1}
* 46
EXAMPLE : K-Means Clustering Method
47.
3. X3={2,1}
4. X4={3,3}
Clusters:C1={X1 , X2 ,X3} C2={X4}
There is no reassignment and therefore the algorithm halts.
* 47
EXAMPLE : K-Means Clustering Method
48.
Advantages:
– With largenumber of variables, k-means may be
computationally faster that hierarchical clustering(if k is
small).
– K-means may produce tighter clusters that hierarchical
clustering especially is the cluster are globular.
Disadvantages:
– Difficult in comparing the quality of the clusters produced.
– Applicable only when mean is defined.
– Need to specify k, the number of clusters in advance.
– Unable to handle noisy data and outliers.
* 48
K-Means Clustering Method
DENSITY BASED CLUSTERING
•The density-based clustering method connects the highly-
dense areas into clusters, and the arbitrarily shaped
distributions are formed as long as the dense region can be
connected.
• This algorithm does it by identifying different clusters in the
dataset and connects the areas of high densities into clusters.
The dense areas in data space are divided from each other by
sparser areas.
• These algorithms can face difficulty in clustering the data
points if the dataset has varying densities and high
dimensions.
* 50
DBSCAN
OPTICS
DENCLUE
CLIQUE
51.
* 51
• DBSCANis the most known and widely used density-based
clustering algorithm, first introduced in 1996 by Ester et. al.
• Due to its importance in both theory and applications, this
algorithm is one of three algorithms awarded the Test of Time
Award at the KDD conference in 2014.
• Density based clustering algorithm has played a vital role in
finding non linear shapes structure based on the density.
• It uses the concept of Density Reachability and Density
Connectivity.
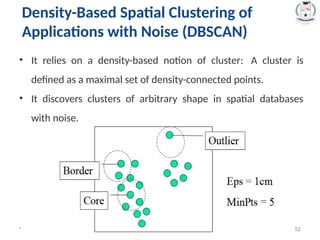
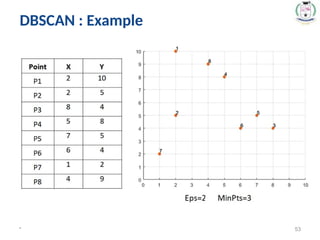
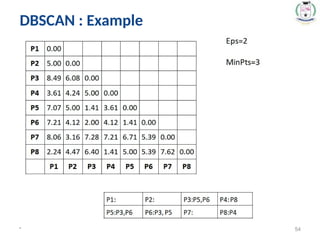
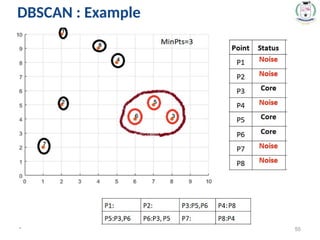
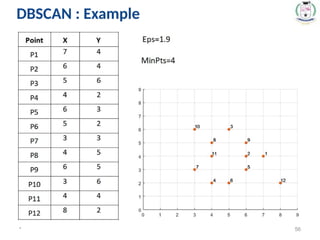
Density-Based Spatial Clustering of
Applications with Noise (DBSCAN)
52.
* 52
• Itrelies on a density-based notion of cluster: A cluster is
defined as a maximal set of density-connected points.
• It discovers clusters of arbitrary shape in spatial databases
with noise.
Density-Based Spatial Clustering of
Applications with Noise (DBSCAN)
* 59
Advantages:
1.Does notrequire a-priori specification of number of clusters.
2.Able to identify noise data while clustering.
3.DBSCAN algorithm is able to find arbitrarily size and arbitrarily
shaped clusters.
Disadvantages:
4.DBSCAN algorithm fails in case of varying density clusters.
5.Fails in case of neck type of dataset.
6.Does not work well in case of high dimensional data.
DENSITY BASED CLUSTERING
60.
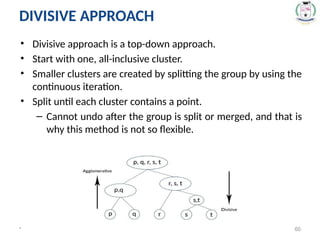
• Divisive approachis a top-down approach.
• Start with one, all-inclusive cluster.
• Smaller clusters are created by splitting the group by using the
continuous iteration.
• Split until each cluster contains a point.
– Cannot undo after the group is split or merged, and that is
why this method is not so flexible.
* 60
DIVISIVE APPROACH
61.
* 61
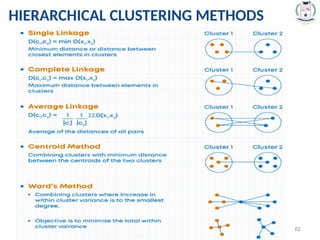
Linkage Criterion:The linkage criterion is where exactly
the distance is measured.
Types of Linkage
⮚ Single-Linkage
⮚ Complete-Linkage
⮚ Average-Linkage
⮚ Centroid-Linkage
⮚ Ward’s Minimum Variance
HIERARCHICAL CLUSTERING METHODS
HIERARCHICAL CLUSTERING METHODS
* 63
Minimum orSingle-Linkage (Nearest Neighbor)
Shortest distance between a pair of observations in two clusters. It tends to
produce long, “loose” clusters.
Maximum or Complete-Linkage (Farthest Neighbor)
Distance measured between the farthest pair of observations in two clusters.
This method usually produces “tighter” clusters than single-linkage.
Mean or Average-Linkage
Computes all pairwise dissimilarities between the elements in cluster 1 and
the elements in cluster 2, and considers the average of these
dissimilarities as the distance between the two clusters.
Centroid-Linkage
Computes the dissimilarity between the centroid for cluster 1 (a mean vector
of length p variables) and the centroid for cluster 2.
Ward’s Minimum Variance Method:
Minimizes the total within-cluster variance. At each step the pair of clusters
with minimum between-cluster distance are merged.
HIERARCHICAL CLUSTERING METHODS
64.
* 64
HIERARCHICAL CLUSTERINGMETHODS
• Starts with one cluster, individual item in its own
cluster and iteratively merge clusters until all the
items belong to one cluster.
• Bottom up approach is followed to merge the
clusters together.
• Dendrograms are pictorially used to represent the
HAC.
Single Linkage Clustering
HIERARCHICAL CLUSTERING METHODS
65.
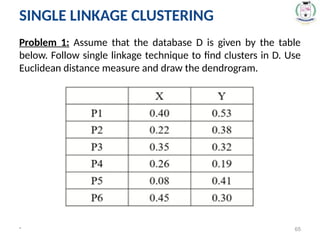
Problem 1: Assumethat the database D is given by the table
below. Follow single linkage technique to find clusters in D. Use
Euclidean distance measure and draw the dendrogram.
* 65
SINGLE LINKAGE CLUSTERING
66.
Solution:
Step 1:
• Plotthe objects in n-dimensional space (where n is the
number of attributes).
• 2 attributes – X and Y, plot the objects P1, P2, … P6 in 2-
dimensional space:
* 66
67.
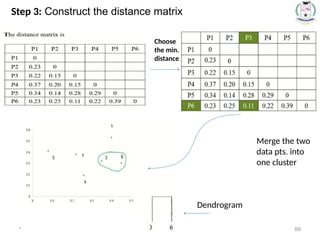
Step 2:
Calculate thedistance from each object (point) to all other
points, using Euclidean distance measure, and place the
numbers in a distance matrix.
– The formula for Euclidean distance between two points i
and j is:
– where xi1 is the value of attribute 1 for i and xj1 is the
value of attribute 1 for j, and so on.
* 67
68.
Given only 2attributes(X,Y). So, the Euclidean distance between
points P1 and P2, which have attributes x and y would be
calculated as follows:
* 68
69.
* SIT1305 Machine69
Choose
the min.
distance
Merge the two
data pts. into
one cluster
Dendrogram
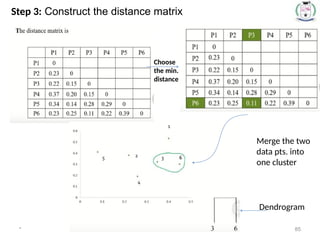
Step 3: Construct the distance matrix
70.
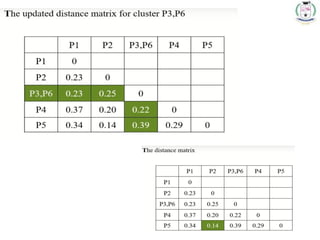
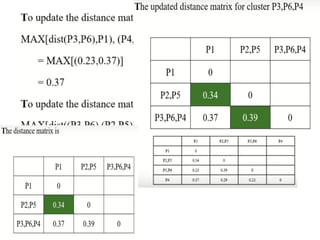
* 70
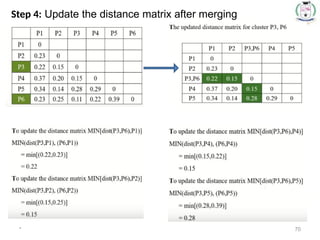
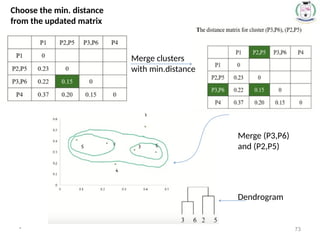
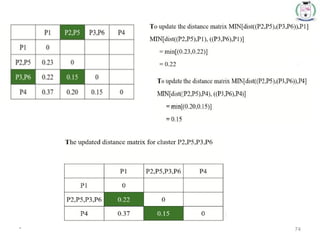
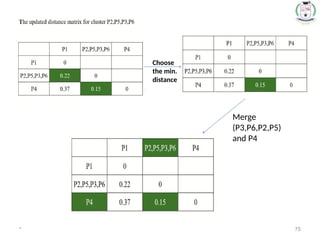
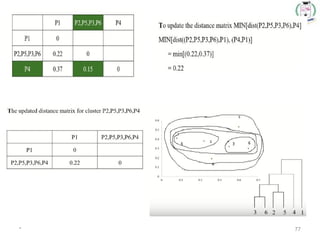
Step 4:Update the distance matrix after merging
71.
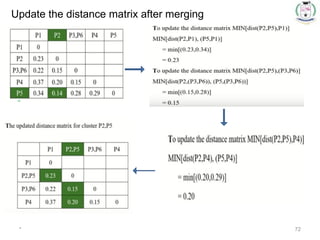
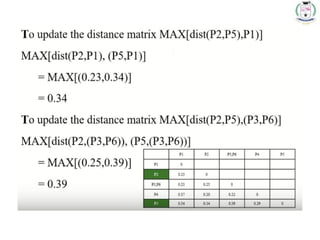
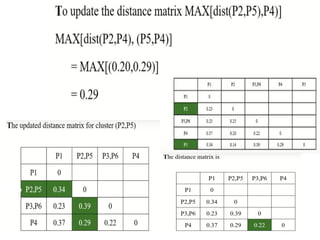
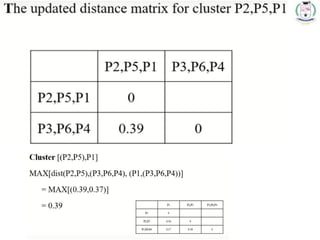
* 71
Choose themin. distance from
the updated matrix
Merge the P2
and P5 one
cluster
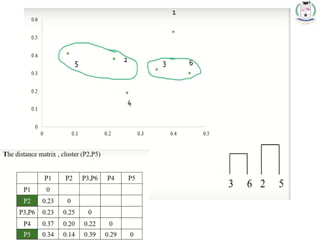
Dendrogram
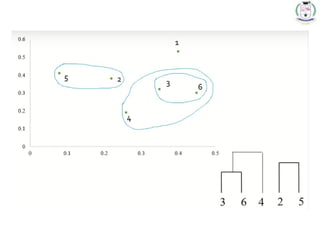
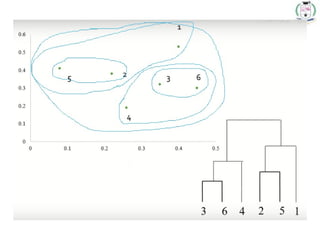
* 78
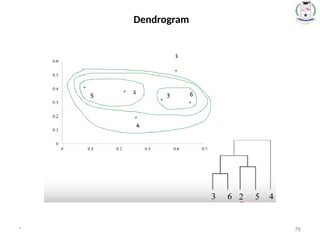
1. Inthe beginning we have 6 clusters : 6,5,4,3,2 and 1.
2. We merge Cluster 3 and 6 into cluster (3,6) at distance
3. We merge Cluster 2 and 5 into cluster (2,5) at distance
4. We merge Cluster (3,6) and (2,5) into cluster ((3,6) (2,5)) at distance
5. We merge Cluster ((3,6) (2,5)) and 4 into cluster (((3,6) (2,5)),4) at distance
6. We merge Cluster (((3,6) (2,5)),4) and 1 into cluster ((((3,6) (2,5)),4),1)at
distance
7. The last cluster contain all the objects, thus conclude the computation.
SINGLE LINKAGE CLUSTERING
79.
* 79
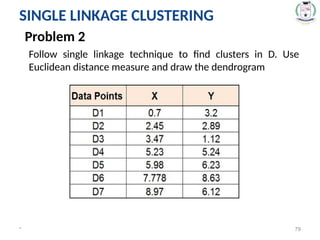
Problem 2
Followsingle linkage technique to find clusters in D. Use
Euclidean distance measure and draw the dendrogram
SINGLE LINKAGE CLUSTERING
80.
* 80
HIERARCHICAL CLUSTERINGMETHODS
• Starts with one cluster, individual item in its own
cluster and iteratively merge clusters until all the
items belong to one cluster.
• Bottom up approach is followed to merge the
clusters together.
• Dendrograms are pictorially used to represent the
HAC.
Complete Linkage Clustering
81.
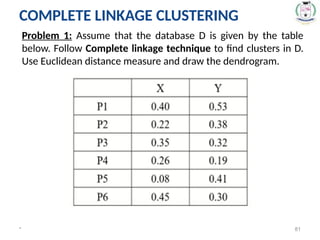
Problem 1: Assumethat the database D is given by the table
below. Follow Complete linkage technique to find clusters in D.
Use Euclidean distance measure and draw the dendrogram.
* 81
COMPLETE LINKAGE CLUSTERING
82.
Solution:
Step 1:
• Plotthe objects in n-dimensional space (where n is the
number of attributes).
• 2 attributes – X and Y, plot the objects P1, P2, … P6 in 2-
dimensional space:
* 82
83.
Step 2:
Calculate thedistance from each object (point) to all other
points, using Euclidean distance measure, and place the
numbers in a distance matrix.
– The formula for Euclidean distance between two points i
and j is:
– where xi1 is the value of attribute 1 for i and xj1 is the
value of attribute 1 for j, and so on.
* 83
84.
Given only 2attributes(X,Y). So, the Euclidean distance between
points P1 and P2, which have attributes x and y would be
calculated as follows:
* 84
* 96
• Theheight in the dendrogram at which two clusters are merged represents
the Distance between two clusters in the data space.
• The decision of merging two clusters is taken on the basis of closeness of
these clusters. There are multiple metrics for deciding the closeness of two
clusters. (Distance).
• The red horizontal line in the dendrogram below covers maximum vertical
distance AB.
HIERARCHICAL CLUSTERING
97.
* 97
Advantages:
•We canobtain the optimal (desired) number of clusters from
the model itself, human intervention not required.
•Dendrograms help us in clear visualization, which is practical
and easy to understand.
Disadvantages:
•Not suitable for large datasets due to high time and space
complexity.
•In hierarchical Clustering, once a decision is made to combine
two clusters, it can not be undone.
•The time complexity for the clustering can result in very
long computation times.
HIERARCHICAL CLUSTERING
98.
a. Search EngineResult Grouping.
b. Document Clustering.
c. Banking and Insurance fraud detection.
d. Image Segmentation.
e. Customer Segmentation.
f. Recommendation Engines.
g. Social Network Analysis.
h. Network Traffic Analysis.
* 98
APPLICATIONS OF CLUSTERING
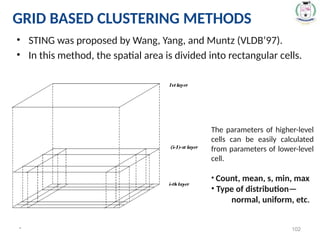
• STING wasproposed by Wang, Yang, and Muntz (VLDB’97).
• In this method, the spatial area is divided into rectangular cells.
* 102
The parameters of higher-level
cells can be easily calculated
from parameters of lower-level
cell.
• Count, mean, s, min, max
• Type of distribution—
normal, uniform, etc.
GRID BASED CLUSTERING METHODS
103.
There are multipleways to implement clustering using a grid, but
most methods are based on density. The algorithm of Grid-based
clustering is as follows −
– Represent a set of grid cells.
– Create objects to the appropriate cells and calculate the
density of each cell.
– Remove cells having a density below a defined threshold, r.
– Form clusters from contiguous set of dense cells.
* 103
GRID BASED CLUSTERING METHODS
104.
* 104
• Thegrid-based clustering methods use a multi-resolution grid data
structure.
• It quantizes the object areas into a finite number of cells that form a grid
structure on which all of the operations for clustering are implemented.
The benefit of the method is its quick processing time, which is generally
independent of the number of data objects, still dependent on only the
multiple cells in each dimension in the quantized space.
• An instance of the grid-based approach involves STING, which explores
statistical data stored in the grid cells.
• WaveCluster, which clusters objects using a wavelet transform approach,
and CLIQUE, which defines a grid-and density-based approach for
clustering in high-dimensional data space
GRID BASED CLUSTERING METHODS
105.
* 105
• ASTING is a grid-based clustering technique. It uses a multidimensional
grid data structure that quantifies space into a finite number of cells.
Instead of focusing on data points, it focuses on the value space
surrounding the data points.
• In STING, the spatial area is divided into rectangular cells and several levels
of cells at different resolution levels. High-level cells are divided into
several low-level cells.
• In STING Statistical Information about attributes in each cell, such as mean,
maximum, and minimum values, are precomputed and stored as
statistical parameters. These statistical parameters are useful for query
processing and other data analysis tasks
STATISTICAL INFORMATION GRID(STING)
106.
* 106
Step 1:Determine a layer, to begin with.
Step 2: For each cell of this layer, it calculates the confidence interval or
estimated range of probability that this is cell is relevant to the query.
Step 3: From the interval, it labels the cell as relevant or not relevant.
Step 4: If this layer is the bottom layer, go to step 6, otherwise, go to step 5.
Step 5: It goes down the hierarchy structure by one level. Go to step 2 for
those cells that form the relevant cell of the high-level layer.
Step 6: If the specification of the query is met, go to step 8, otherwise step 7.
Step 7: Retrieve those data that fall into the relevant cells and do further
processing. Return the result that meets the requirement of the query. Go to
step 9.
Step 8: Find the regions of relevant cells. Return those regions that meet the
requirement of the query.
Step 9: Stop or terminate.
STATISTICAL INFORMATION GRID(STING)
107.
* 107
Advantages:
•Grid-based computingis query-independent because the
statistics stored in each cell represent a summary of the data in
the grid cells and are query-independent.
•The grid structure facilitates parallel processing and incremental
updates.
•Time Complexity is O(K), where K is the number of grid cells at
the lowest level.
Disadvantage:
•All cluster boundaries are either horizontal or vertical, so no
diagonal boundaries are detected.
GRID BASED CLUSTERING METHODS
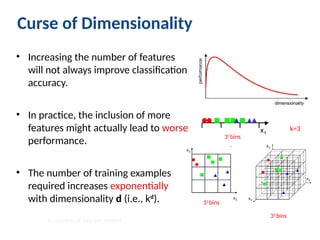
Curse of Dimensionality
•Increasing the number of features
will not always improve classification
accuracy.
• In practice, the inclusion of more
features might actually lead to worse
performance.
• The number of training examples
required increases exponentially
with dimensionality d (i.e., kd
). 32
bins
33
bins
31
bins
k: number of bins per feature
k=3
110.
110
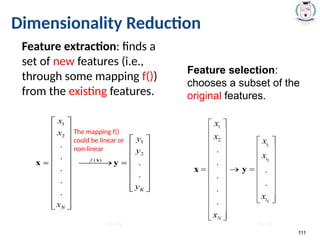
Dimensionality Reduction
• Whatis the objective?
– Choose an optimum set of features of lower
dimensionality to improve classification accuracy.
• Different methods can be used to reduce
dimensionality:
– Feature extraction
– Feature selection
111.
111
Dimensionality Reduction
Feature extraction:finds a
set of new features (i.e.,
through some mapping f())
from the existing features.
Feature selection:
chooses a subset of the
original features.
The mapping f()
could be linear or
non-linear
K<<N K<<N
112.
Feature Extraction
• Linearcombinations are particularly attractive because they are
simpler to compute and analytically tractable.
• Given x R
ϵ N
, find an K x N matrix T such that:
y = Tx R
ϵ K
where K<<N
112
T This is a projection from the
N-dimensional space to a K-
dimensional space.
113.
• From amathematical point of view, finding an optimum
mapping y= (
𝑓 x) is equivalent to optimizing an objective
criterion.
• Different methods use different objective criteria, e.g.,
– Minimize Information Loss: represent the data as accurately as possible
in the lower-dimensional space.
– Maximize Discriminatory Information: enhance the class-discriminatory
information in the lower-dimensional space.
113
Feature Extraction
114.
• Popular linearfeature extraction methods:
– Principal Components Analysis (PCA): Seeks a projection that
preserves as much information in the data as possible.
– Linear Discriminant Analysis (LDA): Seeks a projection that best
discriminates the data.
• Many other methods:
– Making features as independent as possible (Independent Component
Analysis or ICA).
– Retaining interesting directions (Projection Pursuit).
– Embedding to lower dimensional manifolds (Isomap, Locally Linear
Embedding or LLE).
114
Feature Extraction
115.
Vector Representation
• Avector x ϵ Rn
can be represented
by n components:
• Assuming the standard base <v1,
v2, …, vN> (i.e., unit vectors in each
dimension), xi can be obtained by
projecting x along the direction of
vi:
• x can be “reconstructed” from its
projections as follows:
115
• Since the basis vectors are the same for all x R
ϵ n
(standard basis), we typically represent them as a
n-component vector.
Vector Representation
116.
• Example assumingn=2:
• Assuming the standard base <v1=i,
v2=j>, xi can be obtained by
projecting x along the direction of
vi:
• x can be “reconstructed” from its
projections as follows:
116
i
j
Vector Representation
• In 1936,Ronald A.Fisher formulated Linear Discriminant first
time and showed some practical uses as a classifier, it was
described for a 2-class problem.
• Generalized as ‘Multi-class Linear Discriminant Analysis’ or ‘Multiple
Discriminant Analysis’ by C.R.Rao in the year 1948.
• Linear Discriminant Analysis is the most commonly used
Dimensionality Reduction Technique in supervised learning.
• Basically, it is a preprocessing step for pattern classification and
machine learning applications.
• Under Linear Discriminant Analysis, we look for :
– Which set of parameters can best describe the association of
the group for an object?
– What is the best classification preceptor model that separates
those groups?
* 118
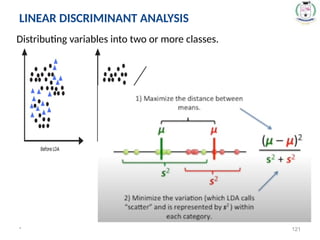
LINEAR DISCRIMINANT ANALYSIS
LINEAR DISCRIMINANT ANALYSIS
119.
• Linear DiscriminantAnalysis, or LDA, is a machine learning
algorithm that is used to find the Linear Discriminant function that
best classifies or discriminates two classes of data points.
• LDA is a supervised learning algorithm, which means that it
requires a labelled training set of data points in order to learn the
Linear Discriminant function.
• Once the Linear Discriminant function has been learned, it can then
be used to predict the class label of new data points.
• LDA is similar to PCA (principal component analysis) in the sense
that LDA reduces the dimensions. However, the main purpose of
LDA is to find the line (or plane) that best separates data points
belonging to different classes.
• The key idea behind LDA is that the decision boundary should be
chosen such that it maximizes the distance between the means of
the two classes while simultaneously minimizing the variance
within each classes data or within-class scatter.
* 119
LINEAR DISCRIMINANT ANALYSIS
* 122
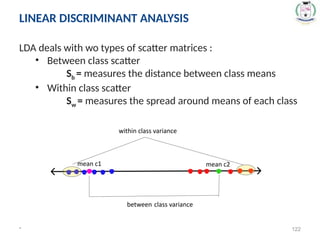
LDA dealswith wo types of scatter matrices :
• Between class scatter
Sb = measures the distance between class means
• Within class scatter
Sw = measures the spread around means of each class
LINEAR DISCRIMINANT ANALYSIS
123.
* 123
• Calculatethe separability between classes which is the distance
between the mean of different classes, called the between-class
variance.
LINEAR DISCRIMINANT ANALYSIS
• Calculate the distance between the mean and sample of each
class. It is also called the within-class variance.
• Construct the lower-dimensional space which maximizes the
between-class variance and minimizes the within-class variance. P
is considered as the lower-dimensional space projection, also
called Fisher’s criterion.
124.
* 124
Step1: Calculatethe Mean and Standard Deviation of each feature.
Step2: Calculate Within class scatter matrix and Between class
scatter matrix.
Step3: Using these matrices then calculate the Eigenvectors and
Eigenvalues.
Step4: Choose the k Eigenvectors with the largest Eigenvalues to
form a transformation matrix.
Step5: Use this transformation matrix to transform the data into a
new space with k dimensions.
Step6: Once the transformation matrix transforms the data, then
we could do classification or dimensionality reduction.
LDA ALGORITHM
125.
* 125
LDA ModelLearning Pattern
The mean value of each input for each of the classes can be calculated by
dividing the sum of values by the total number of values:
Mean = Sum(x)/ Nk
where
Mean = mean value of x for class
N = number of instances
k = number of classes
Sum(x) = sum of values of each input x.
The variance is computed across all the classes as the average of the square
of the difference of each value from the mean:
Σ²=Sum((x - M)²)/(N - k)
where Σ² = Variance across all inputs x.
N = number of instances.
k = number of classes.
Sum((x - M)²) = Sum of values of all (x - M)².
M = mean for input x.
126.
Goal : Toproject a feature space (N-Dimensional Data)
on to a smaller subspace k (k<= N-1) while maintaining
the class discriminating information.
Consider a 2-D Data set
C1=(x1,y1) = { (4,1) (2,4) (2,3) (3,6) (4,4) }
C2=(x2,y2) = { (9,10) (6,8) (9,5) (8,7) (10,8) }
Step1: Compute within_class Scatter Matrix Sw
Sw = S1 + S2
S1 is the Covariance Matrix for the class C1 and S2 is the
Covariance Matrix for the class C2
* 126
LDA - EXAMPLE
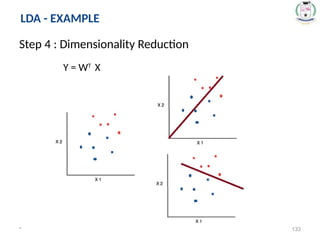
* 133
Step 4: Dimensionality Reduction
Y = WT
X
LDA - EXAMPLE
134.
Advantages:
• It issimple, fast and portable algorithm.
• Performs better than logistic regression, when its
assumptions are met.
Disadvantages:
• It requires normal distribution assumptions on
features/predictors.
•Not good for few categories variables.
•Complex Matrix Manipulations.
* 134
LINEAR DISCRIMINANT ANALYSIS
* 136
PRINCIPLE COMPONENTANALYSIS
• PCA was invented in 1901 by Karl Pearson, as an analogue of
the principal axis theorem in mechanics, it was later independently
developed and named by Harold Hotelling in the 1930s.
• PCA can be thought of as fitting a p-dimensional ellipsoid to the data,
where each axis of the ellipsoid represents a principal component. If
some axis of the ellipsoid is small, then the variance along that axis is
also small.
• Principal Component Analysis (PCA) is a technique used in machine
learning to reduce the dimensionality of a large dataset by projecting it
onto a smaller number of linearly uncorrelated variables called principal
components.
* 138
PCA -ALGORITHM
Step 1 - Load data : Let's say we have a dataset with n data points,
where each data point has m features. We load the data into a matrix X
of size n x m.
Step 2 - Center data : center the data by subtracting the mean of each
feature from each data point. This ensures that each feature has a
mean of zero.
Step 3 - Compute covariance matrix : compute the covariance matrix of
the centered data, which is a measure of how much two features vary
together. The covariance matrix is a square matrix of size m x m.
Step 4 - Compute eigenvectors and eigenvalues of covariance matrix :
compute the eigenvectors and eigenvalues of the covariance matrix.
The eigenvectors are a set of orthogonal vectors that define the
directions of the principal components, and the eigenvalues represent
the variance of the data along these directions.
139.
* 139
Step 5- Sort eigenvectors by their eigenvalues : sort the eigenvectors by
their corresponding eigenvalues in decreasing order. The eigenvectors
with the largest eigenvalues represent the directions of the most
significant variation in the data.
Step 6 - Select Top k eigenvectors : select the top k eigenvectors with the
largest eigenvalues to define the new subspace for the data, thereby
choosing the principle components. Typically, we choose k to be much
smaller than m to reduce the dimensionality of the data.
Step 7 - Project the data onto the new subspace : Project the centered
data onto the new subspace defined by the top k eigenvectors to obtain
the new dataset Y. The size of Y is n x k.
PCA - ALGORITHM
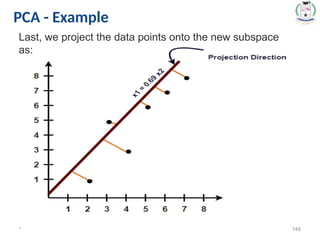
* 147
PCA -Example
Thus, principal component for the given data set is-
148.
* 148
PCA -Example
Last, we project the data points onto the new subspace
as:
149.
Advantages:
• Removes correlatedfeatures.
• Improves machine learning algorithm performance.
• Reduce overfitting.
Disadvantages:
•Independent variables are now less interpretable.
•Information loss.
•Feature scaling
* 149
PRINCIPLE COMPONENT ANALYSIS
Editor's Notes
#6 Clustering is the task of dividing the population or data points into a number of groups such that data points in the same groups are more similar to other data points in the same group than those in other groups. In simple words, the aim is to segregate groups with similar traits and assign them into clusters. Let’s understand this with an example. Suppose, you are the head of a rental store and wish to understand preferences of your costumers to scale up your business. Is it possible for you to look at details of each costumer and devise a unique business strategy for each one of them? Definitely not. But, what you can do is to cluster all of your costumers into say 10 groups based on their purchasing habits and use a separate strategy for costumers in each of these 10 groups. And this is what we call clustering
#23 Hard Clustering: In hard clustering, each data point either belongs to a cluster completely or not. For example, in the above example each customer is put into one group out of the 10 groups.
Soft Clustering: In soft clustering, instead of putting each data point into a separate cluster, a probability or likelihood of that data point to be in those clusters is assigned. For example, from the above scenario each costumer is assigned a probability to be in either of 10 clusters of the retailstore.
Depending on scalability, attributes, dimensional, boundary shape, noise, and interpretation, we have various types of clustering methods that solve one or many of these problems and of course, many statistical and machine learning clustering algorithms that implement the methodology.
Let’s understand this with an example. Suppose, you are the head of a rental store and wish to understand preferences of your costumers to scale up your business.
Definitely not. But, what you can do is to cluster all of your costumers into say 10 groups based on their purchasing habits and use a separate strategy for costumers in each of these 10 groups. And this is what we call clustering.
Now, that we understand what is clustering. Let’s take a look at the types of clustering.
#25 one would observe that both hierarchical and centroid based algorithms are dependent on a distance (similarity/proximity) metric. The very definition of a cluster is based on this metric.
Density-based clustering methods take density into consideration instead of distances.
Clusters are considered as the densest region in a data space, which is separated by regions of lower object density and it is defined as a maximal-set of connected points.
When performing most of the clustering, we take two major assumptions, one, the data is devoid of any noise and two, the shape of the cluster so formed is purely geometrical (circular or elliptical).
Density-based algorithms can get us clusters with arbitrary shapes, clusters without any limitation in cluster sizes,
clusters that contain the maximum level of homogeneity by ensuring the same levels of density within it, and also these clusters are inclusive of outliers or the noisy data.
DBSCAN – Density-based Spatial Clustering
#26 Hierarchical Clustering is a method of unsupervised machine learning clustering where it begins with a pre-defined top to bottom hierarchy of clusters.
It then proceeds to perform a decomposition of the data objects based on this hierarchy, hence obtaining the clusters.
This method follows two approaches based on the direction of progress, i.e., whether it is the top-down or bottom-up flow of creating clusters.
In this technique, the dataset is divided into clusters to create a tree-like structure, which is also called a dendrogram.
The observations or any number of clusters can be selected by cutting the tree at the correct level.
Flow of creating clusters
The most common example of this method is the Agglomerative Hierarchical algorithm.
The observations or any number of clusters can be selected by cutting the tree at the correct level. The most common example of this method is the Agglomerative Hierarchical algorithm.
#27 Until now, the clustering techniques as we know are based around either proximity (similarity/distance) or composition (density).
There is a family of clustering algorithms that take a totally different metric into consideration – probability.
Distribution-based clustering creates and groups data points based on their likely hood of belonging to the same probability distribution (Gaussian, Binomial etc.) in the data.
Distribution based clustering has a vivid advantage over the proximity and centroid based clustering methods in terms of flexibility, correctness and shape of the clusters formed.
The major problem however is that these clustering methods work well only with synthetic or simulated data or with data where most of the data points most certainly belong to a predefined distribution, if not, the results will overfit.
Gaussian Mixed Models (GMM) with Expectation-Maximization Clustering
#28 The general idea about clustering revolves around assigning data points to mutually exclusive clusters, meaning, a data point always resides uniquely inside a cluster and it cannot belong to more than one cluster.
Fuzzy clustering methods change this paradigm by assigning a data-point to multiple clusters with a quantified degree of belongingness metric.
The data-points that are in proximity to the center of a cluster, may also belong in the cluster that is at a higher degree than points in the edge of a cluster. The possibility of which an element belongs to a given cluster is measured by membership coefficient that vary from 0 to 1.
Fuzzy clustering can be used with datasets where the variables have a high level of overlap. It is a strongly preferred algorithm for Image Segmentation, especially in bioinformatics
where identifying overlapping gene codes makes it difficult for generic clustering algorithms to differentiate between the image’s pixels and they fail to perform a proper clustering.
Fuzzy C Means Algorithm – FANNY (Fuzzy Analysis Clustering)
#29 The clustering process, in general, is based on the approach that the data can be divided into an optimal number of “unknown” groups.
The underlying stages of all the clustering algorithms to find those hidden patterns and similarities, without any intervention or predefined conditions.
A tree is constructed by splitting without the interference of the constraints or clustering labels.
Then, the leaf nodes of the tree are combined together to form the clusters while incorporating the constraints and using suitable algorithms.
#31 It is a type of clustering that divides the data into non-hierarchical groups.
It is also known as the centroid-based method. The most common example of partitioning clustering is the K-Means Clustering algorithm.
In this type, the dataset is divided into a set of k groups, where K is used to define the number of pre-defined groups. The cluster center is created in such a way that the distance between the data points of one cluster is mi
#33 Partioning algorithm constructs partitions of a database of N objects into a set of K Clusters.
Optimal partition w.r.t an objective function.
Each element is placed in exactly one of the K non-overlapping clusters.
We obtain only one set of clusters as output, user has to input the desired no of clusters.
We optimize the objective fn defied either locally or globally (criterion)
Global : Euclidean square Error Measure.
Represents each cluster by a prototype or Centroid and assigns each sample to clusters according to most similar prototypes.
Local : Minimal Mutual Neighbor Distance (MND) forms clusters by utilizing the local structure or context in the data.
#34 In R, there is a built-in function kmeans() and in Python, we make use of scikit-learn cluster module which has the KMeans function. (sklearn.cluster.KMeans)
#36 k-Means is one of the most widely used and perhaps the simplest unsupervised algorithms to solve the clustering problems.
Using this algorithm, we classify a given data set through a certain number of predetermined clusters or “k” clusters.
Each cluster is assigned a designated cluster center and they are placed as much as possible far away from each other.
Subsequently, each point belonging gets associated with it to the nearest centroid till no point is left unassigned.
Once it is done, the centers are re-calculated and the above steps are repeated.
The algorithm converges at a point where the centroids cannot move any further.
This algorithm targets to minimize an objective function called the squared error function F(V) :
The most commonly used partitioning-clustering strategy is based on the square error criterion.
#38 where,
||xi – vj|| is the distance between Xi and Vj.
Ci is the count of data in cluster. C is the number of cluster centroids.
Well known Partioning method : Kmeans,K Medoids and their variations,
Simplest :kmeans and well known USLA
Cluster similarity is measured with regard to mean value of the objects in a cluster,which is viewd as centroid or center of gravity.
Intracluster similarity is high and inter cluster similarity is low.
#39 Algorithm :
Partition objects into K Non empty subsets.
Compute seed points as the centroids of the clusters of the current partition (Center : Mean point of Cluster)
Assign each object to the cluster with the nearest seed point.
Go back to step 2, when no new more assignment.
Algorithm aims at minimizing Objective Function,in our case its
Mean Squared error Function
#50 It is an unsupervised machine learning algorithm that makes clusters based upon the density of the data points or how close the data is.
one would observe that both hierarchical and centroid based algorithms are dependent on a distance (similarity/proximity) metric.
The very definition of a cluster is based on this metric.
Density-based clustering methods take density into consideration instead of distances.
Clusters are considered as the densest region in a data space, which is separated by regions of lower object density and it is defined as a maximal-set of connected points.
When performing most of the clustering, we take two major assumptions, one, the data is devoid of any noise and two, the shape of the cluster so formed is purely geometrical (circular or elliptical).
Density-based algorithms can get us clusters with arbitrary shapes, clusters without any limitation in cluster sizes,
clusters that contain the maximum level of homogeneity by ensuring the same levels of density within it, and also these clusters are inclusive of outliers or the noisy data.
DBSCAN – Density-based Spatial Clustering
#51 That said, the points which are outside the dense regions are excluded and treated as noise or outliers.
This characteristic of the DBSCAN algorithm makes it a perfect fit for outlier detection and making clusters of arbitrary shape.
The algorithms like K-Means Clustering lack this property and make spherical clusters only and are very sensitive to outliers.
By sensitivity, we mean the sphere-shaped clusters made through K-Means can easily get influenced by the introduction of a single outlier as they are included too.
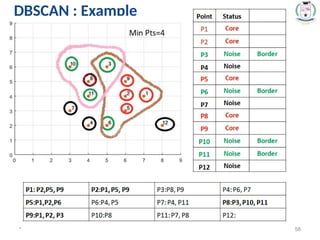
#52 Eps: Maximum radius of the neighborhood.
MinPts: Minimum number of points in an Eps-neighbourhood of that point.
#60 Hence, iteratively, we are splitting the data which was once grouped as a single large cluster, to “n” number of smaller clusters in which the data points now belong to.
It must be taken into account that this algorithm is highly “rigid” when splitting the clusters –
meaning, one a clustering is done inside a loop, there is no way that the task can be undone
#77 Hierarchical clustering is a powerful technique that allows you to build tree structures from data similarities. You can now see how different sub-clusters relate to each other, and how far apart data points are.
#78 Stopping condition - The single link technique indicates that “each object is placed in a separate cluster, and at each step we merge the closest pair of clusters, until certain termination conditions are satisfied”.
In the example above, we have merged all points into a single cluster at the end.
The goal of user is to likely to perform data partition into several clusters for unsupervised learning purposes.
Therefore, the algorithm has to stop clustering at some point – either the user will specify the number of clusters he/she would like to have, or the algorithm has to make a decision on its own.
#96 Hierarchical clustering, as the name suggests is an algorithm that builds hierarchy of clusters. This algorithm starts with all the data points assigned to a cluster of their own. Then two nearest clusters are merged into the same cluster. In the end, this algorithm terminates when there is only a single cluster left
#97 Can obtain any desired number of clusters by cutting the Dendrogram at the proper level.
All the approaches to calculate the similarity between clusters has their own disadvantages.
Time complexity of at least O(n2 log n) is required, where ‘n’ is the number of data points.
#98 It is the backbone of search engine algorithms – where objects that are similar to each other must be presented together and dissimilar objects should be ignored. Also, it is required to fetch objects that are closely related to a search term, if not completely related.
A similar application of text clustering like search engine can be seen in academics where clustering can help in the associative analysis of various documents – which can be in-turn used in – plagiarism, copyright infringement, patent analysis etc.
Used in image segmentation in bioinformatics where clustering algorithms have proven their worth in detecting cancerous cells from various medical imagery – eliminating the prevalent human errors and other bias.
Netflix has used clustering in implementing movie recommendations for its users.
News summarization can be performed using Cluster analysis where articles can be divided into a group of related topics.
Clustering is used in getting recommendations for sports training for athletes based on their goals and various body related metrics and assign the training regimen to the players accordingly.
Marketing and sales applications use clustering to identify the Demand-Supply gap based on various past metrics – where a definitive meaning can be given to huge amounts of scattered data.
Various job search portals use clustering to divide job posting requirements into organized groups which becomes easier for a job-seeker to apply and target for a suitable job.
Resumes of job-seekers can be segmented into groups based on various factors like skill-sets, experience, strengths, type of projects, expertise etc., which makes potential employers connect with correct resources.
Clustering effectively detects hidden patterns, rules, constraints, flow etc. based on various metrics of traffic density from GPS data and can be used for segmenting routes and suggesting users with best routes, location of essential services, search for objects on a map etc.
Satellite imagery can be segmented to find suitable and arable lands for agriculture.
Pizza Hut very famously used clustering to perform Customer Segmentation which helped them to target their campaigns effectively and helped increase their customer engagement across various channels.
Clustering can help in getting customer persona analysis based on various metrics of Recency, Frequency, and Monetary metrics and build an effective User Profile – in-turn this can be used for Customer Loyalty methods to curb customer churn.
Document clustering is effectively being used in preventing the spread of fake news on Social Media.
Website network traffic can be divided into various segments and heuristically when we can prioritize the requests and also helps in detecting and preventing malicious activities.
Fantasy sports have become a part of popular culture across the globe and clustering algorithms can be used in identifying team trends, aggregating expert ranking data, player similarities, and other strategies and recommendations for the users.
#102 There are several levels of cells corresponding to different levels of resolution.
For each cell, the high level is partitioned into several smaller cells in the next lower level.
The statistical info of each cell is calculated and stored beforehand and is used to answer queries.
Then using a top-down approach we need to answer spatial data queries.
Then start from a pre-selected layer—typically with a small number of cells.
For each cell in the current level compute the confidence interval.
#103 A grid is an effective method to organize a set of data, minimum in low dimensions.
The concept is to divide the applicable values of each attribute into a multiple contiguous intervals, making a set of grid cells.
Each object declines into a grid cell whose equivalent attribute intervals include the values of the object.
Then using a top-down approach we need to answer spatial data queries.
Then start from a pre-selected layer—typically with a small number of cells.
For each cell in the current level compute the confidence interval.
#104 In Grid-Based Methods, the space of instance is divided into a grid structure. Clustering techniques are then applied using the Cells of the grid, instead of individual data points, as the base units. The biggest advantage of this method is to improve the processing time.
#105 The statistical parameter of higher-level cells can easily be computed from the parameters of the lower-level cells.
#107 The specification of higher-level cells can be simply computed from the specification of lower-level cells:
count, mean, s, min, max
type of distribution-normal, uniform, etc.
#117 The techniques of dimensionality reduction are important in applications of Machine Learning, Data Mining, Bioinformatics, and Information Retrieval. The main agenda is to remove the redundant and dependent features by changing the dataset onto a lower-dimensional space.
In simple terms, they reduce the dimensions (i.e. variables) in a particular dataset while retaining most of the data.
Multi-dimensional data comprises multiple features having a correlation with one another. You can plot multi-dimensional data in just 2 or 3 dimensions with dimensionality reduction. It allows the data to be presented in an explicit manner which can be easily understood by a layman. But to achieve this kind of feat you data analysts need to learn relevant skills.
Let's talk about linear regression first. You may know that, linear regression analysis tries to fit a line through the data points in an n-dimensional plane,
such that the distances between the points and the line is minimized.
Discrminant Analysis is opposite of linear regression. Here, the task is to maximize the distance between the discrminating
boundary or the discrminating line to the data points on either side of the line and minimize the distances between the points
themselves.
we know that the hypothesis equation is h(x) = w(t).x + c
The discriminant analysis tries to find the optimum w's and c, such that the above explained theory holds true.
Quadratic Discriminant Analysis(QDA) – When there are multiple input variables, each of the class uses its own estimate of variance and covariance.
Flexible Discriminant Analysis(FDA) – This technique is performed when a non-linear combination of inputs is used as splines.
Regularized Discriminant Analysis(RDA) – It moderates the influence of various variables in LDA by regularizing the estimate of the covariance.
Flexible Discriminant Analysis (FDA)
Quadratic Discriminant Analysis (QDA)
Regularized Discriminant Analysis (RDA)
#118 With the aim to classify objects into one of two or more groups based on some set of parameters that describes objects, LDA has come up with specific functions and applications
#119 With the aim to classify objects into one of two or more groups based on some set of parameters that describes objects, LDA has come up with specific functions and applications
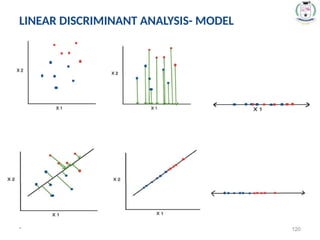
#120 Consider a situation where you have plotted the relationship between two variables where each color represents a different class.
One is shown with a red color and the other with blue.
If you are willing to reduce the number of dimensions to 1, you can just project everything to the x-axis as shown below:
This approach neglects any helpful information provided by the second feature.
However, you can use LDA to plot it. The advantage of LDA is that it uses information from both the features to create a new axis which in turn minimizes the variance and maximizes the class distance of the two variables.
#121 However, it is impossible to draw a straight line in a 2-d plane that can separate these data points efficiently
but using linear Discriminant analysis; we can dimensionally reduce the 2-D plane into the 1-D plane.
Using this technique, we can also maximize the separability between multiple classes.
To create a new axis, Linear Discriminant Analysis uses the following criteria:
It maximizes the distance between means of two classes.
It minimizes the variance within the individual class.
In the above picture, data get projected on most appropriate separating line or hyperplane such that the distance between the means is maximized and the variance within the data from same class is minimized.
#123 LDA focuses primarily on projecting the features in higher dimension space to lower dimensions. You can achieve this in three steps:
The representation of LDA is pretty straight-forward. The model consists of the statistical properties of your data that has been calculated for each class. The same properties are calculated over the multivariate Gaussian in the case of multiple variables. The multivariates are means and covariate matrix.
Predictions are made by providing the statistical properties into the LDA equation. The properties are estimated from your data. Finally, the model values are saved to file to create the LDA model.
#124 LDA works by projecting the data onto a lower-dimensional space while preserving as much of the class information as possible and then finding the hyperplane that maximizes the separation between the classes based on Fisher criterian. The picture below represents aspect of projecting the data on a separation line and finding the best possible line.
LDA is a supervised machine learning algorithm that can be used for both classification and dimensionality reduction. LDA algorithm works based on the following steps:
LDA can be used for classification, such as classifying emails as spam or not spam.
LDA can be used for dimensionality reduction, such as reducing the number of features in a dataset.
LDA can be used to find the most important features in a dataset.
#125 The representation of LDA is pretty straight-forward. The model consists of the statistical properties of your data that has been calculated for each class.
The same properties are calculated over the multivariate Gaussian in the case of multiple variables.
The multivariates are means and covariate matrix.
Predictions are made by providing the statistical properties into the LDA equation.
The properties are estimated from your data. Finally, the model values are saved to file to create the LDA model.
The assumptions made by an LDA model about your data:
Each variable in the data is shaped in the form of a bell curve when plotted,i.e. Gaussian.
The values of each variable vary around the mean by the same amount on the average,i.e. each attribute has the same variance.
#127 For each x we are going to calculate (x-U1) (x-U1)t so we have to find 5 matrices
Similarly calculate for U2
#128 For each x we are going to calculate (x-U1) (x-U1)t so we have to find 5 matrices.
Adding all 5 and taking average we get covariance matrix S1.
#130 V – Projection Vector
Labda eigen value [Scaled by a value]
#132 V – Projection Vector
Ad = 8
Bc = 7
Ad=13.94
Bc = 0.19
-2.074-0.128
-0.173-0.768
#133 V – Projection Vector
Projection Vector corresponding to highest Eigen Value.
#135 In Machine Learning, PCA is an unsupervised machine learning algorithm.
Principal component analysis, or PCA, is a dimensionality-reductionPrincipal component analysis, or PCA, is a dimensionality-reduction method that is often used to reduce the dimensionality of large data sets, by transforming a large set of variables into a smaller one that still contains most of the information in the large set.
Reducing the number of variables of a data set naturally comes at the expense of accuracy, but the trick in dimensionality reduction is to trade a little accuracy for simplicity.
Because smaller data sets are easier to explore and visualize and make analyzing data much easier and faster for machine learning algorithms without extraneous variables to process.
So, to sum up, the idea of PCA is simple — reduce the number of variables of a data set, while preserving as much information as possible.
Formally, PCA is a statistical technique for reducing the dimensionality of a dataset. This is accomplished by linearly transforming the data into a new coordinate system where (most of) the variation in the data can be described with fewer dimensions than the initial data. Many studies use the first two principal components in order to plot the data in two dimensions and to visually identify clusters of closely related data points. Principal component analysis has applications in many fields such as population genetics, microbiome studies, and atmospheric science.[1]
#136 Depending on the field of application, it is also named the discrete Karhunen–Loève transform (KLT) in signal processing, the Hotelling transform in multivariate quality control, proper orthogonal decomposition (POD) in mechanical engineering, singular value decomposition (SVD) of X and eigenvalue decomposition (EVD) of XTX in linear algebra, factor analysis. Eckart–Young theorem (Harman, 1960), or empirical orthogonal functions (EOF) in meteorological science (Lorenz, 1956), empirical eigenfunction decomposition (Sirovich, 1987), quasiharmonic modes (Brooks et al., 1988), spectral decomposition in noise and vibration, and empirical modal analysis in structural dynamics.
An ellipsoid is a surface that may be obtained from a sphere by deforming it by means of directional scalings, or more generally, of an affine transformation.
An ellipsoid is a quadric surface; that is, a surface that may be defined as the zero set of a polynomial of degree two in three variables.
#137 The main aim of PCA is to find such principal components, which can describe the data points with a set of... well, principal components.
principal components remove noise by reducing a large number of features to just a couple of principal components.
The principal components are vectors, but they are not chosen at random. The first principal component is computed so that it explains the greatest amount of variance in the original features. The second component is orthogonal to the first, and it explains the greatest amount of variance left after the first principal component.
The original data can be represented as feature vectors. PCA allows us to go a step further and represent the data as linear combinations of principal components. Getting principal components is equivalent to a linear transformation of data from the feature1 x feature2 axis to a PCA1 x PCA2 axis.
#138 More specifically, the reason why it is critical to perform standardization prior to PCA, is that the latter is quite sensitive regarding the variances of the initial variables. That is, if there are large differences between the ranges of initial variables, those variables with larger ranges will dominate over those with small ranges (for example, a variable that ranges between 0 and 100 will dominate over a variable that ranges between 0 and 1), which will lead to biased results. So, transforming the data to comparable scales can prevent this problem.
Mathematically, this can be done by subtracting the mean and dividing by the standard deviation for each value of each variable.
Once the standardization is done, all the variables will be transformed to the same scale.
s
#145 Clearly, the second eigen value is very small compared to the first eigen value.
So, the second eigen vector can be left out.
Eigen vector corresponding to the greatest eigen value is the principal component for the given data set.
So. we find the eigen vector corresponding to eigen value λ1.
#146 Substituting the values in the above equation, we get-
#149 Removes correlated features. PCA will help you remove all the features that are correlated,
a phenomenon known as multi-collinearity. Finding features that are correlated is time consuming, especially if the number of features is large.
Improves machine learning algorithm performance. With the number of features reduced with PCA, the time taken to train your model is now significantly reduced.
Reduce overfitting. By removing the unnecessary features in your dataset, PCA helps to overcome overfitting.
Independent variables are now less interpretable. PCA reduces your features into smaller number of components.
Each component is now a linear combination of your original features, which makes it less readable and interpretable.
Information loss. Data loss may occur if you do not exercise care in choosing the right number of components.
Feature scaling. Because PCA is a variance maximizing exercise, PCA requires features to be scaled prior to processing.





















![HIERARCHICAL CLUSTERING
• Hierarchical clustering can be used as an alternative for the
partitioned clustering as there is no requirement of pre-
specifying the number of clusters to be created.
• In this technique, the dataset is divided into clusters to create
a tree-like structure, which is also called a Dendrogram.
1. Top-down [Divisive Approach]
2. Bottom-up [Agglomerative Approach]
* 26](https://image.slidesharecdn.com/unit-iii-250826093056-3f3ba010/85/Unit-Three-for-Machine-Learning-Essentials-26-320.jpg)
































































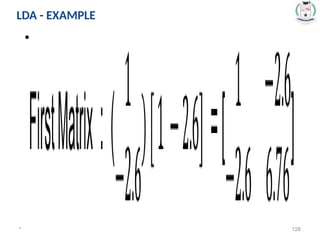
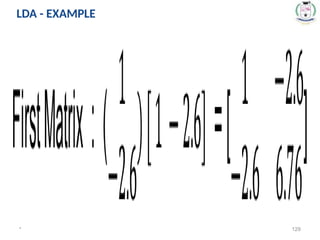

























![Clustering[306] [Read-Only].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/clustering306read-only-230112103535-3fb144db-thumbnail.jpg?width=640&height=640&fit=bounds)

















![Chapter#04[Part#01]K-Means Clusterig.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/chapter04part01k-meansclusterig-250525201708-2d369307-thumbnail.jpg?width=640&height=640&fit=bounds)





















