Downloaded 25 times

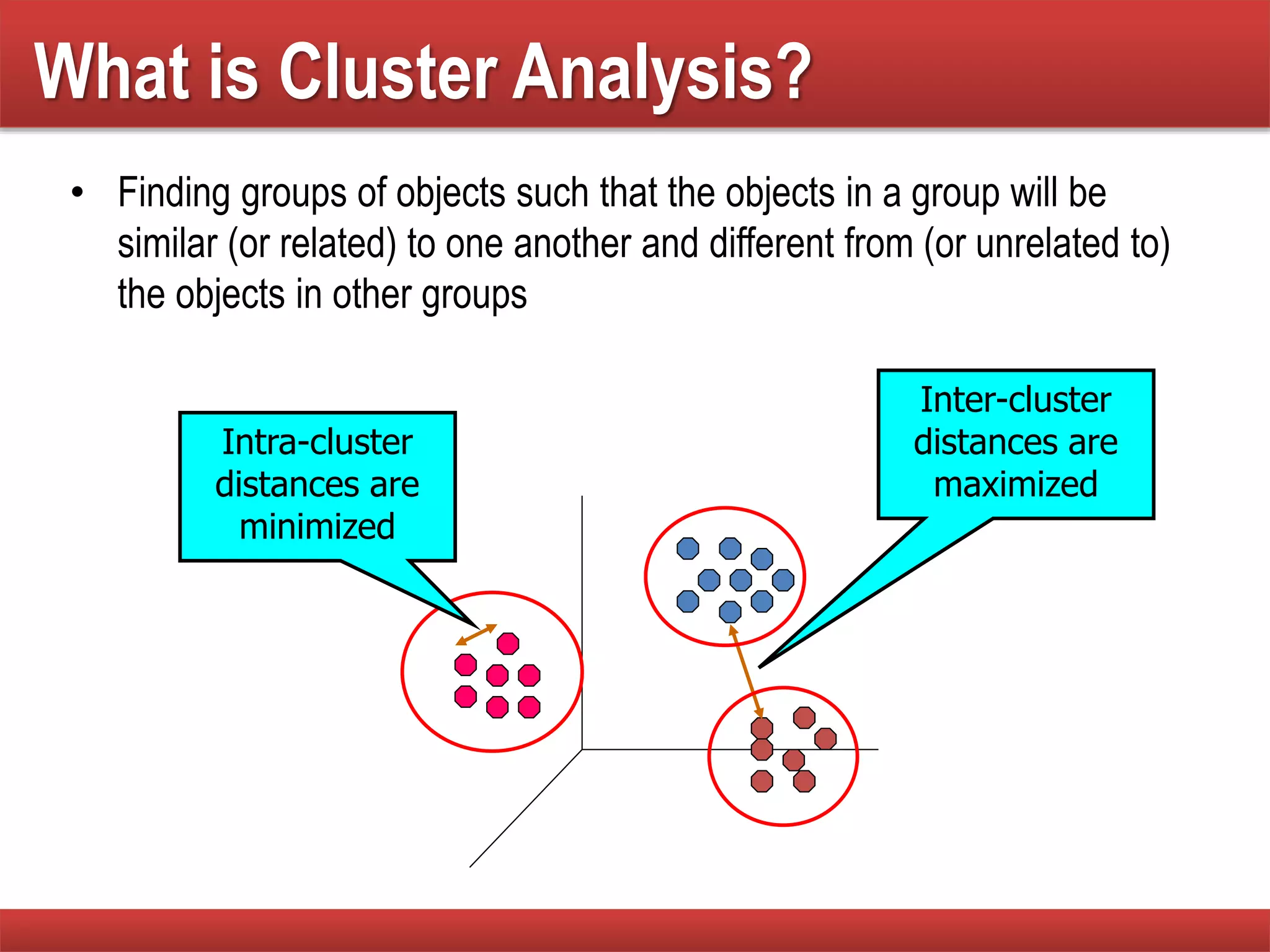










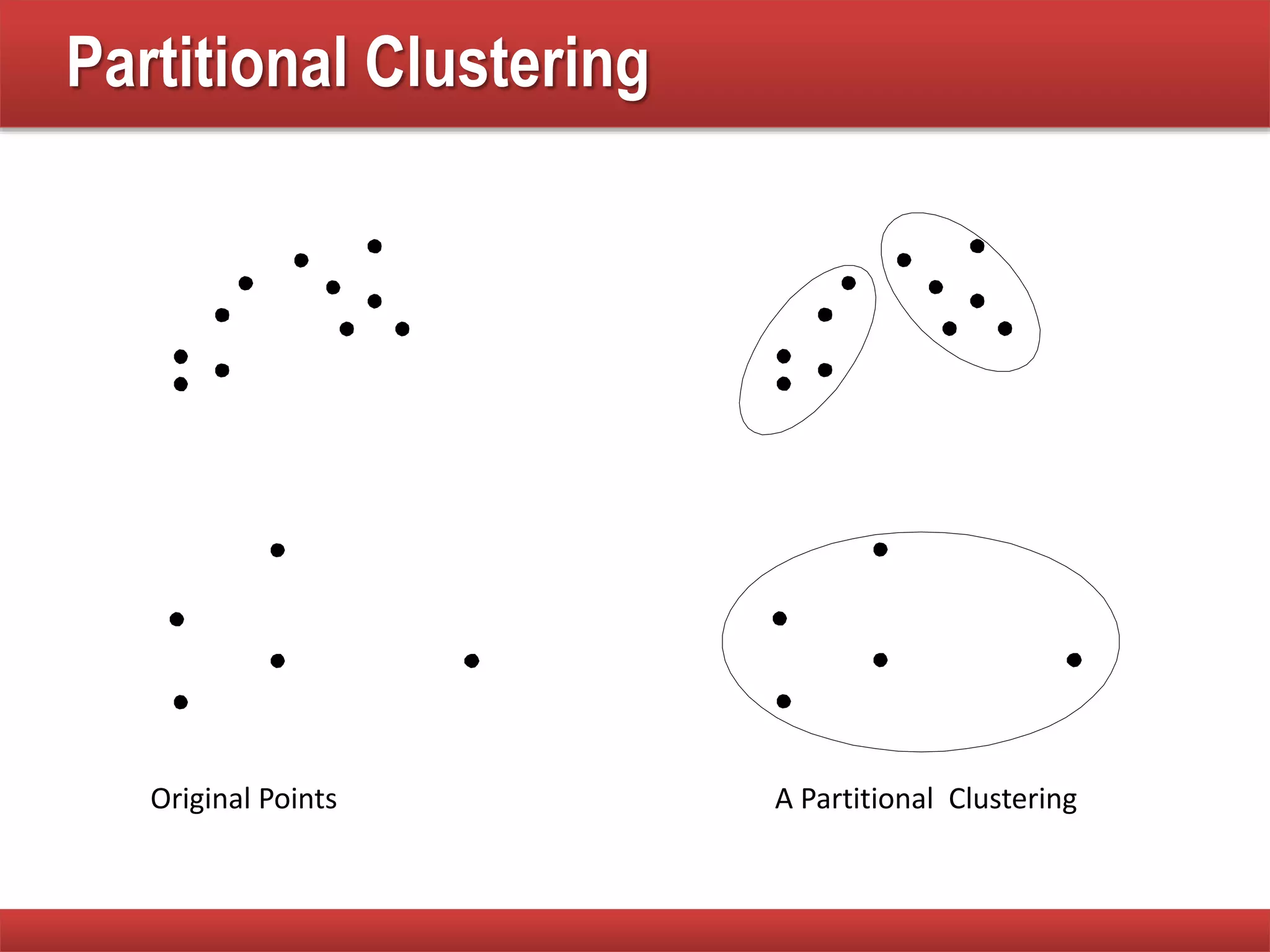
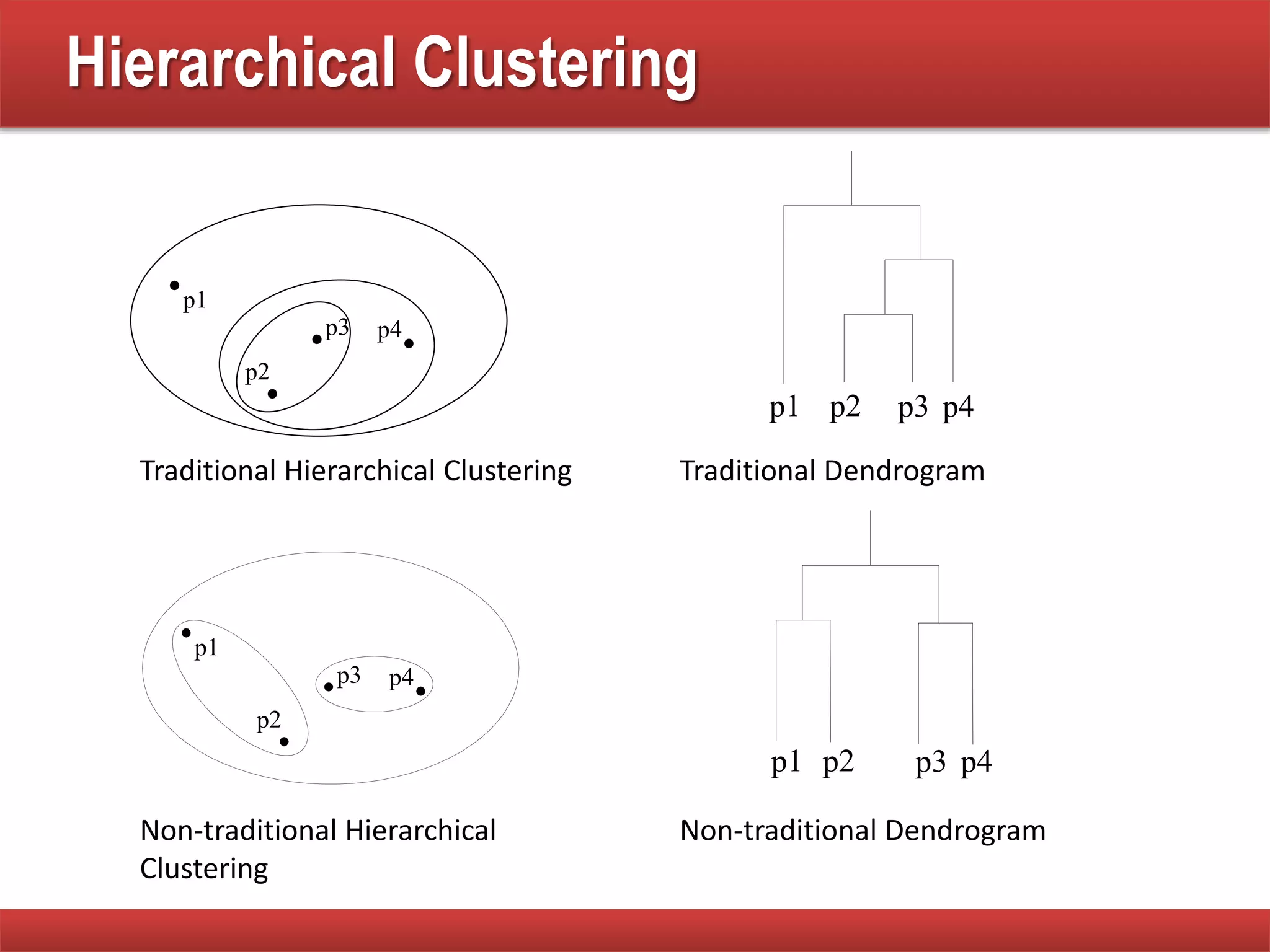


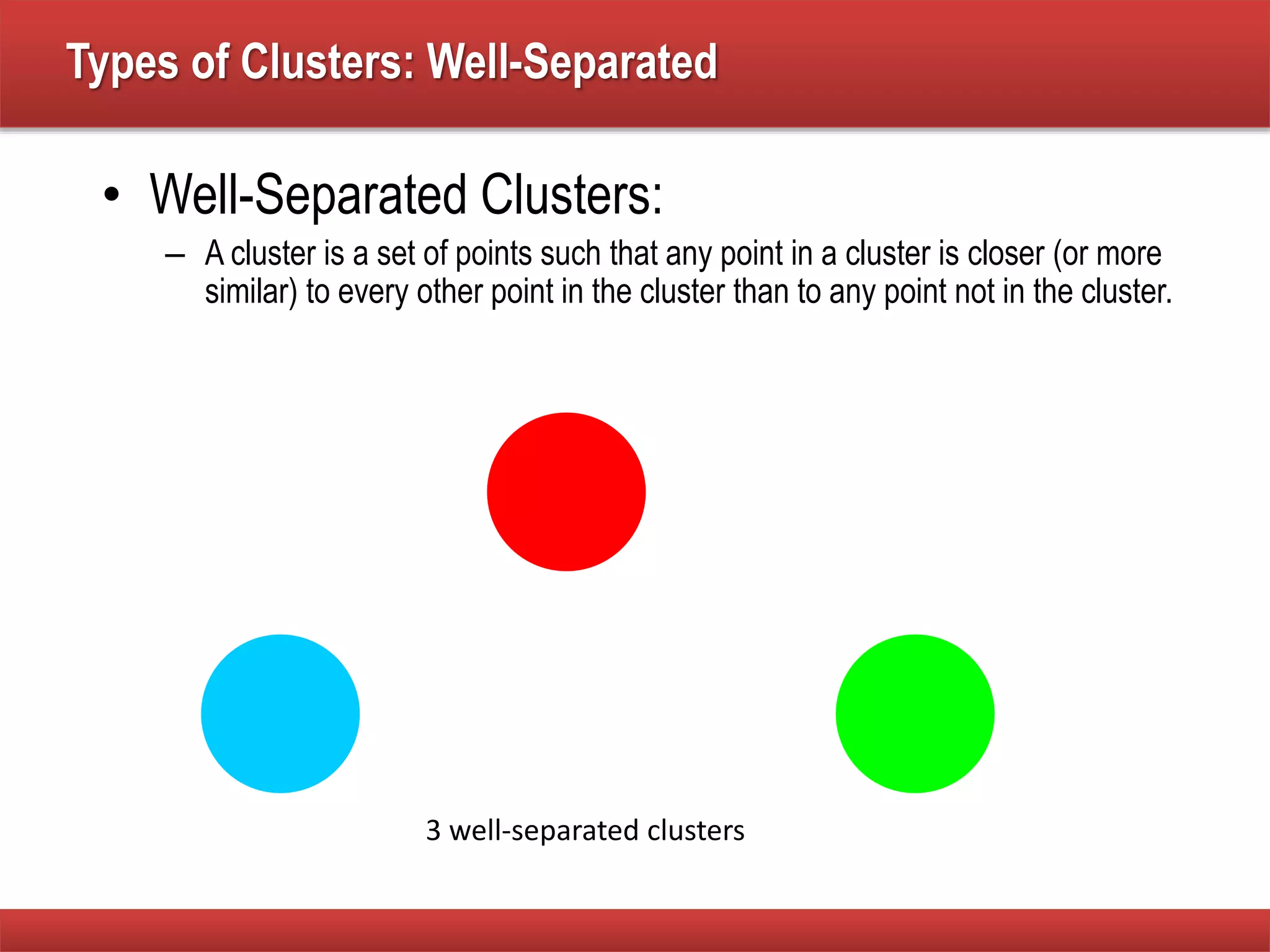







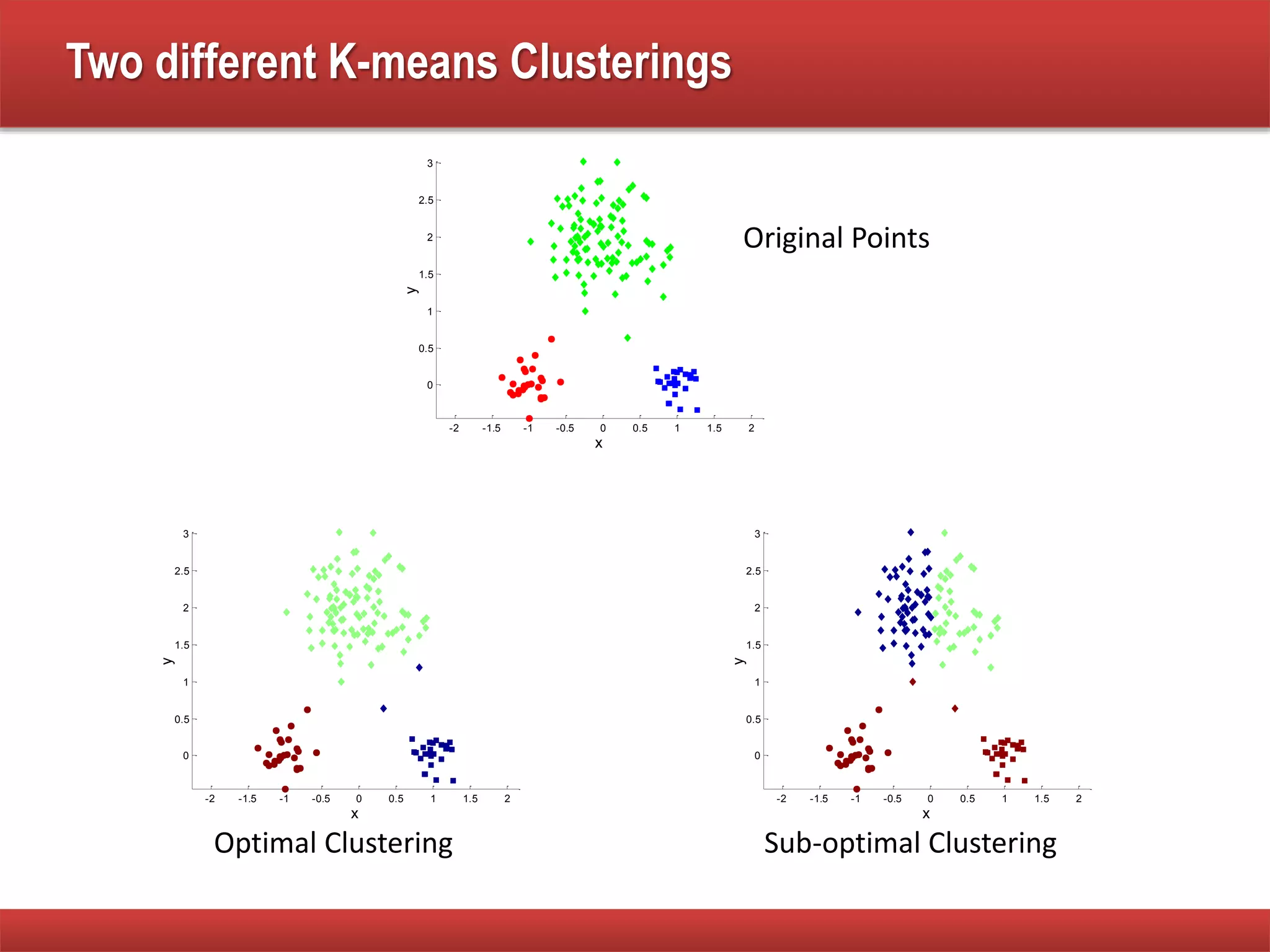
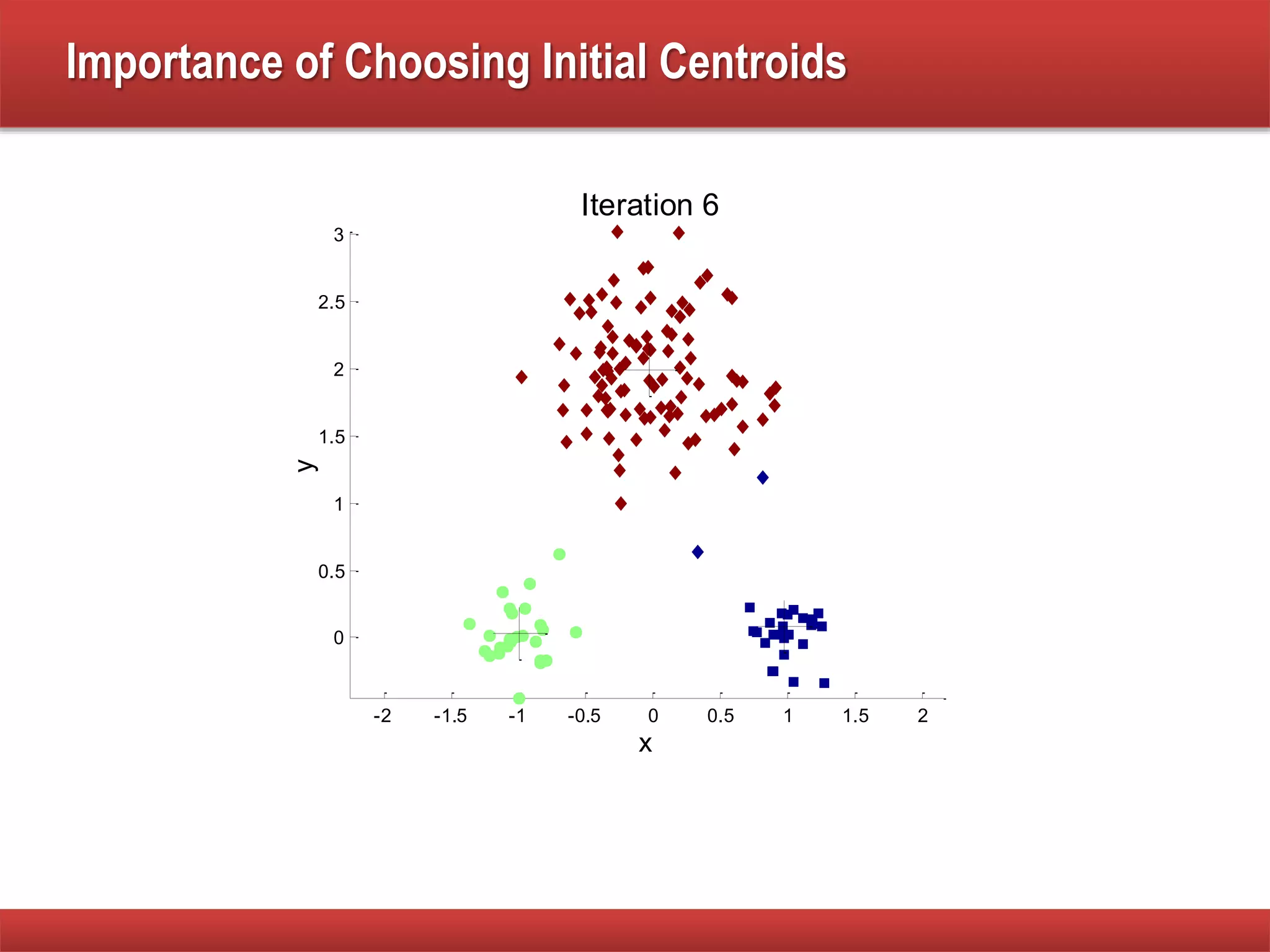
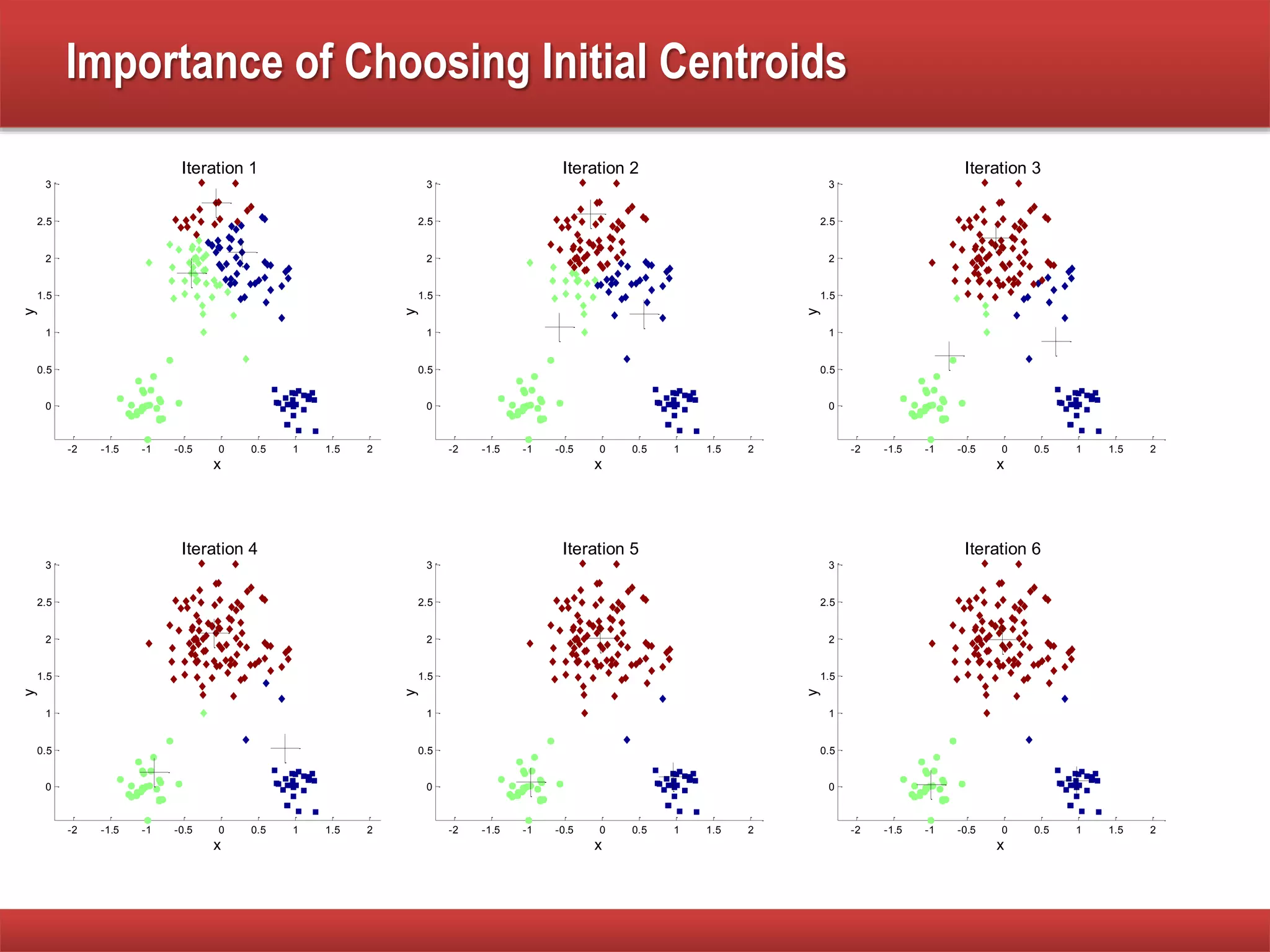
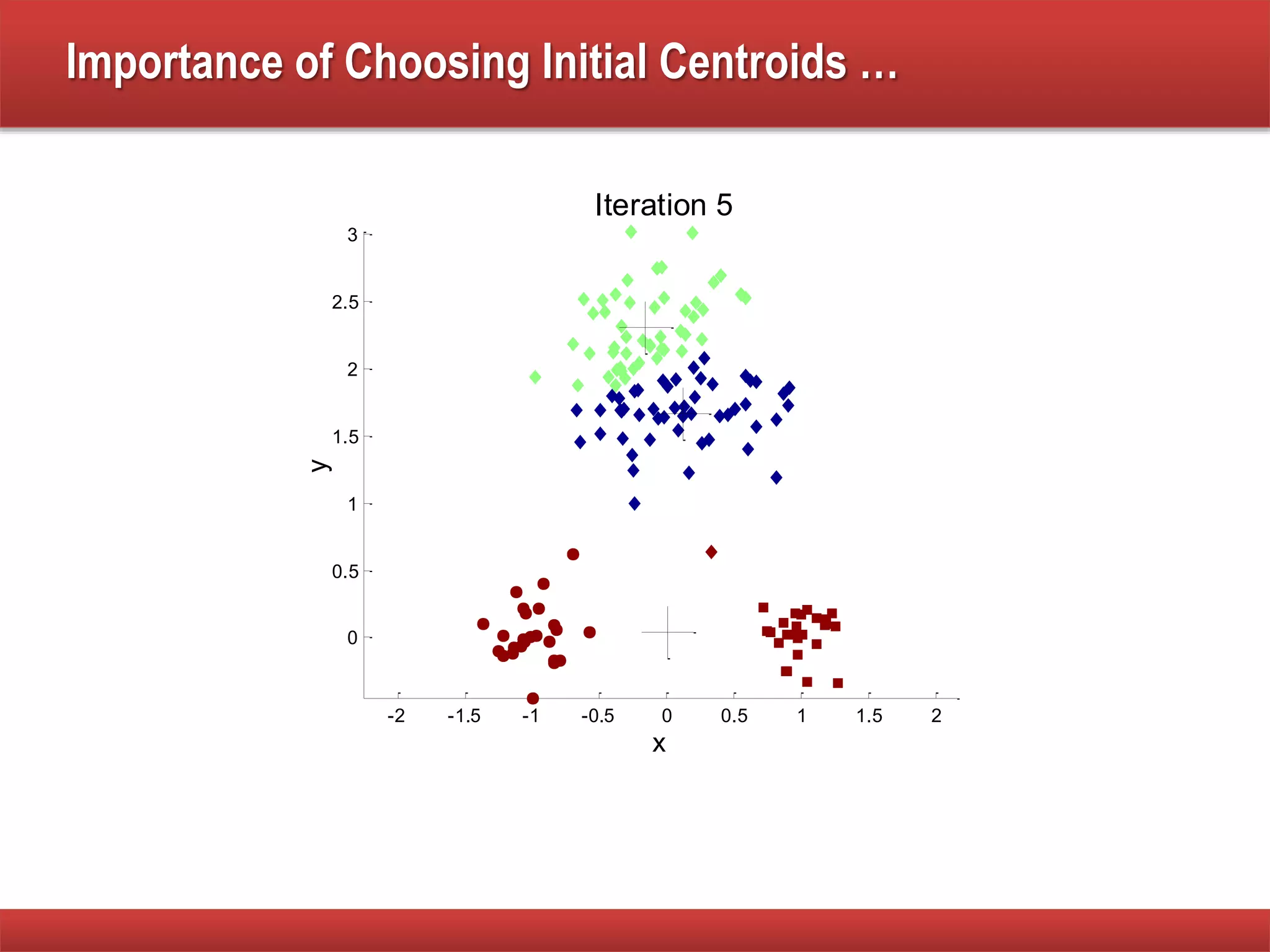
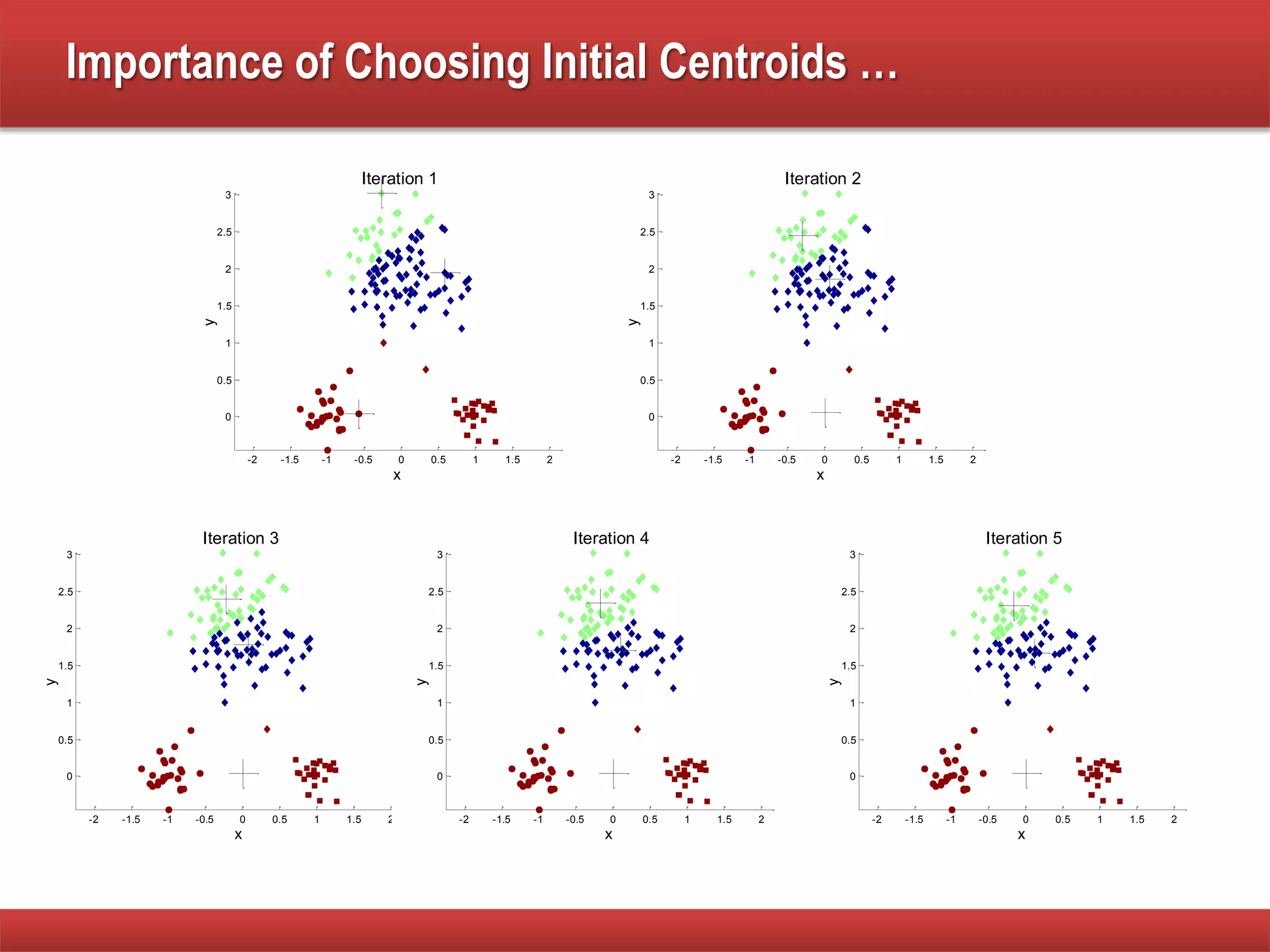

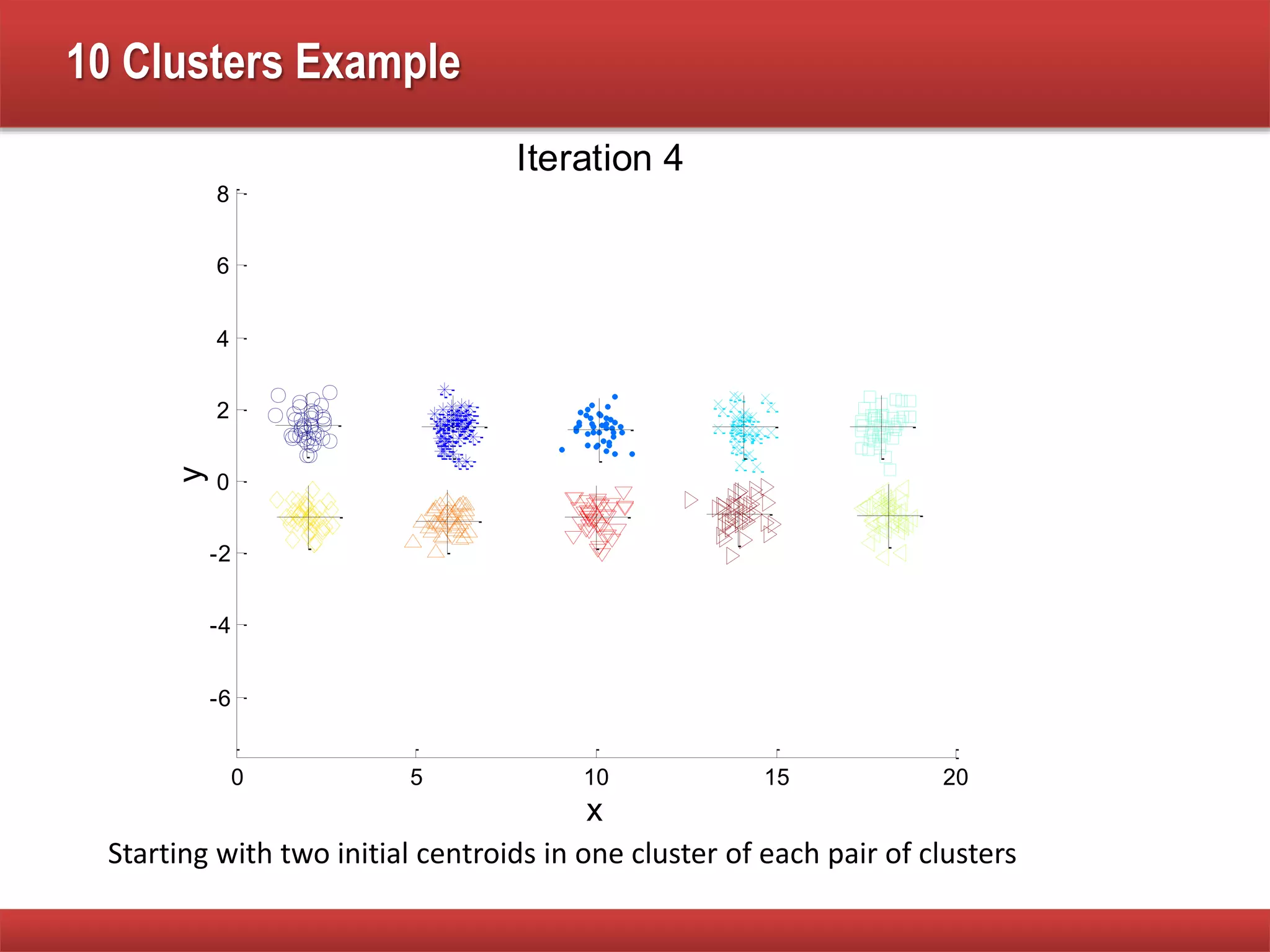
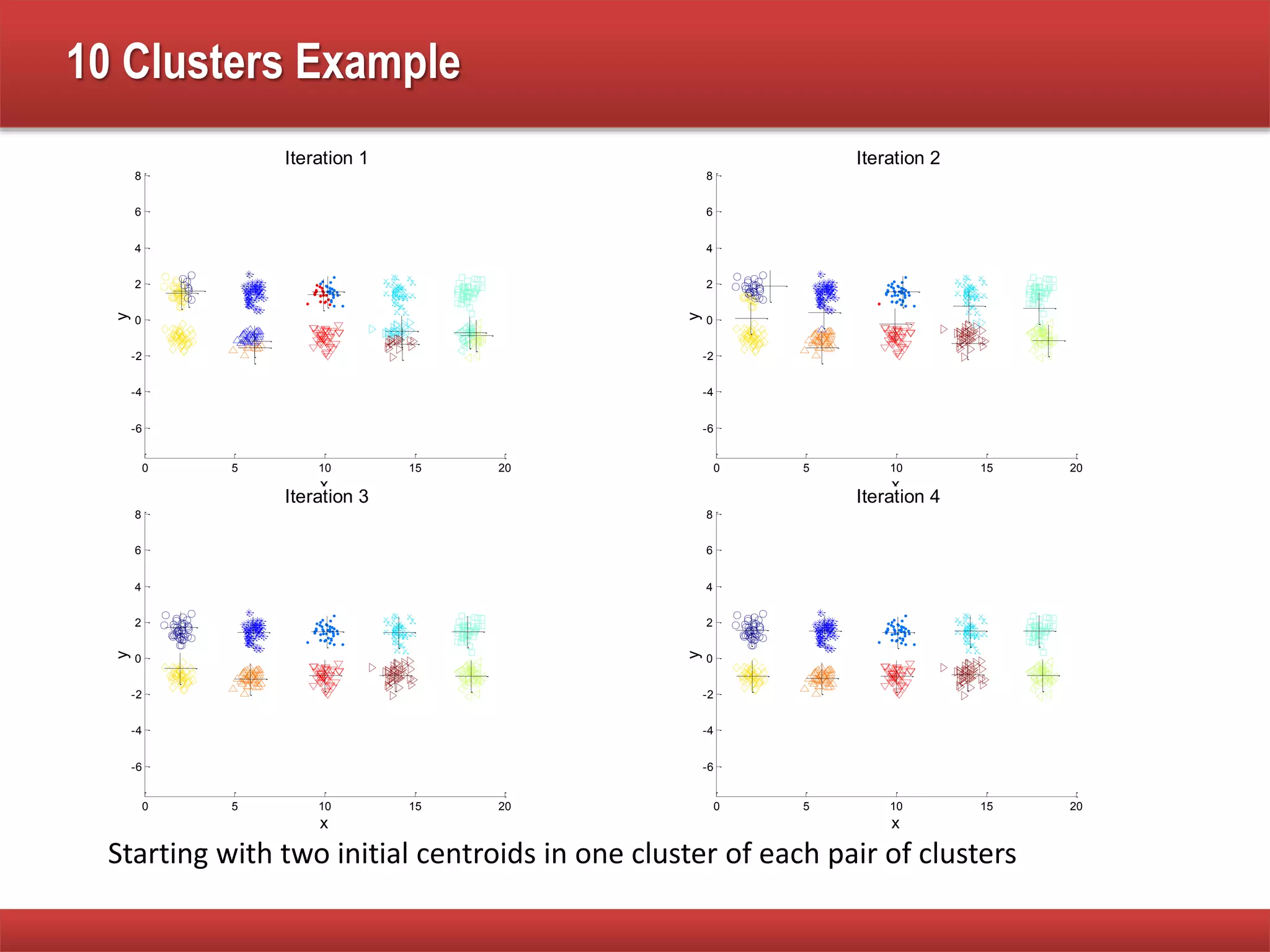
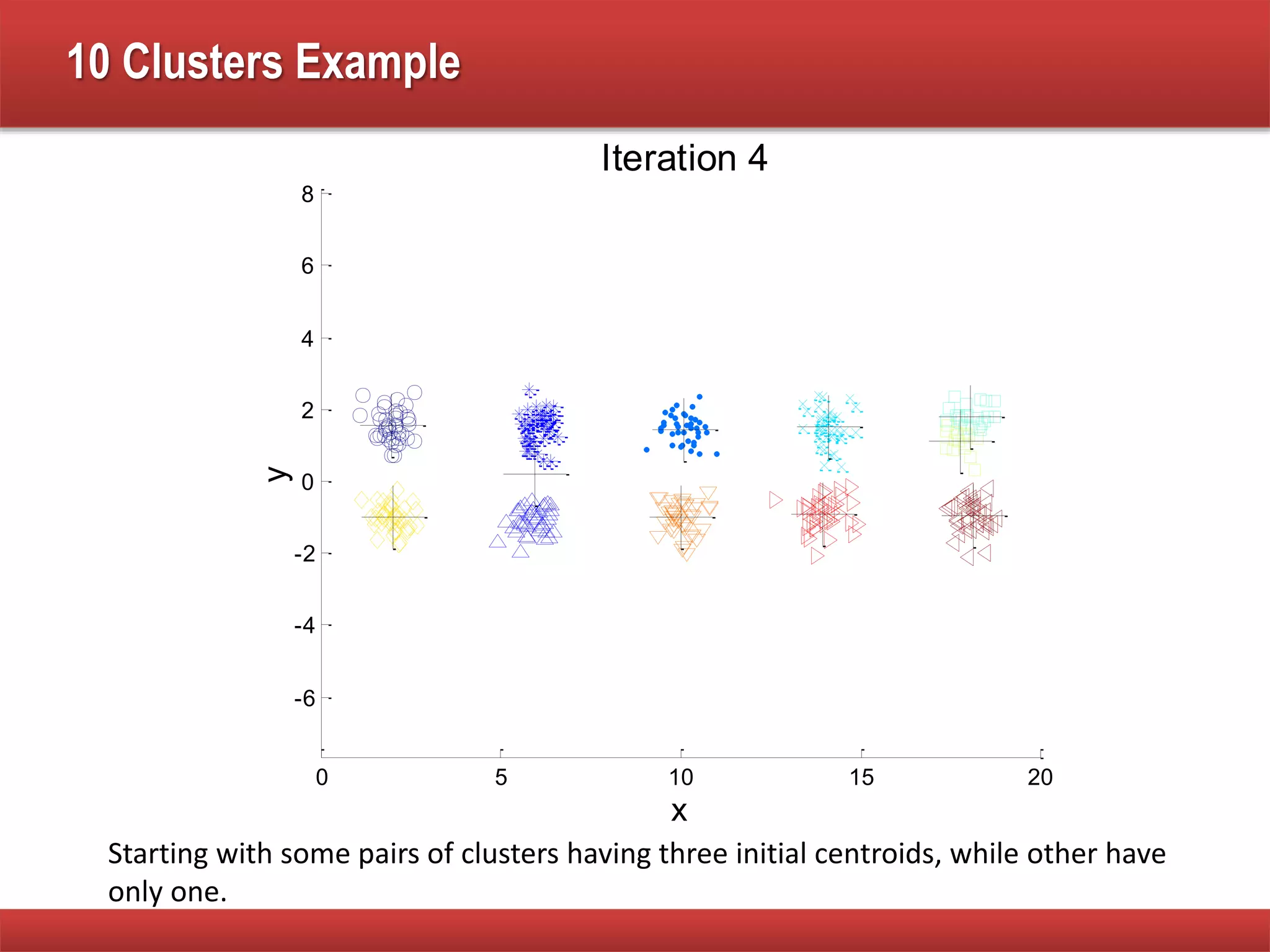
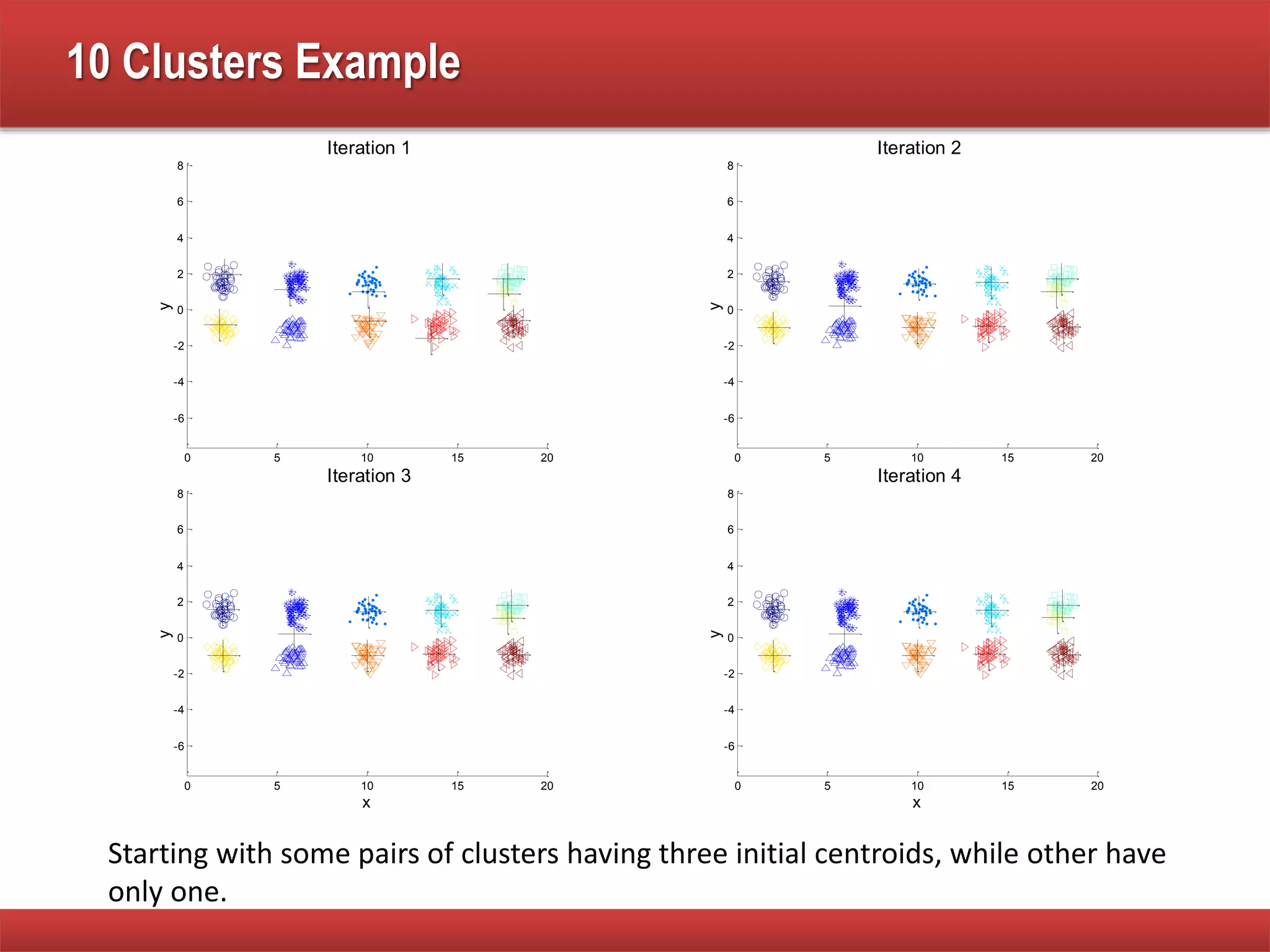



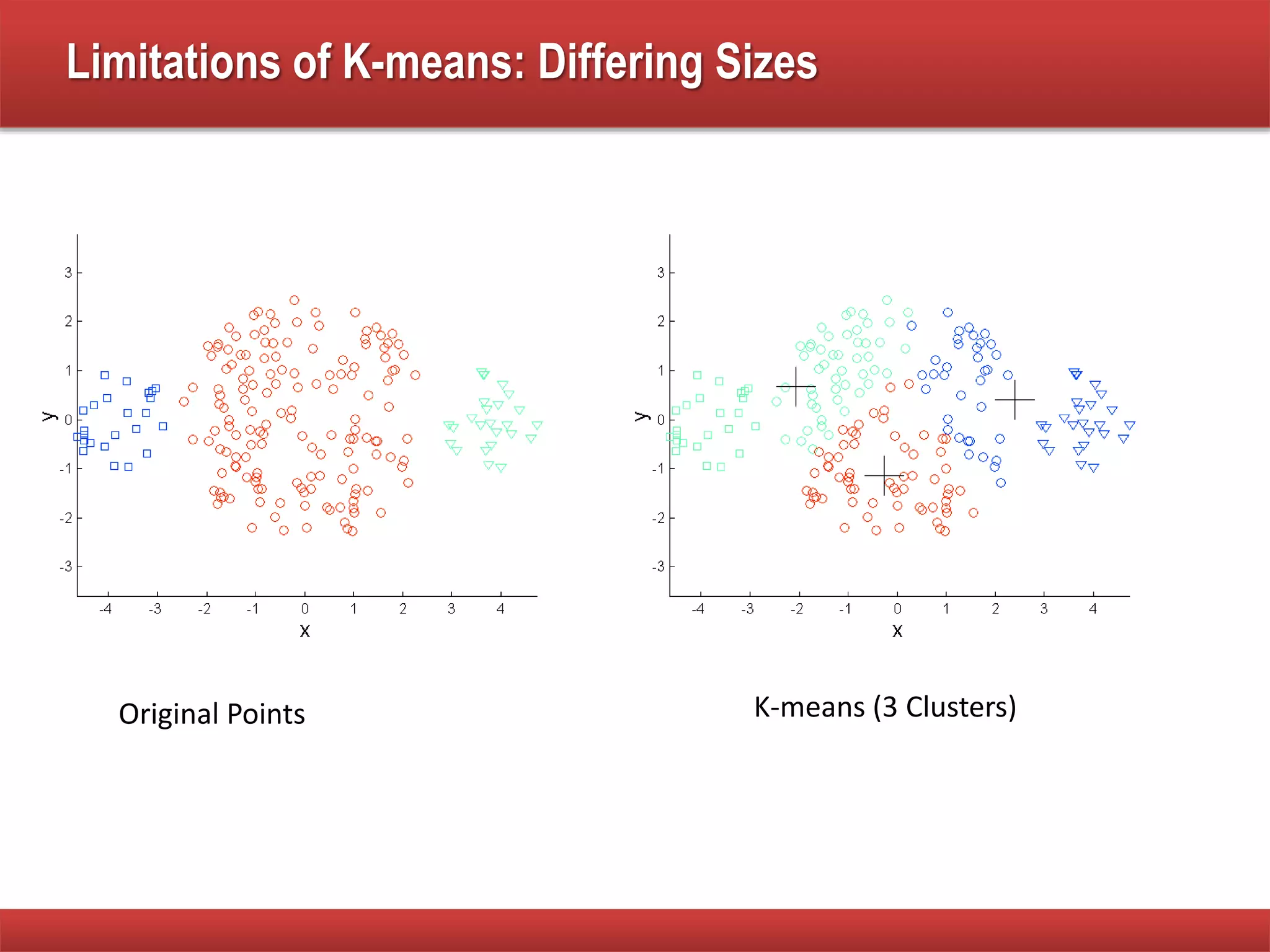
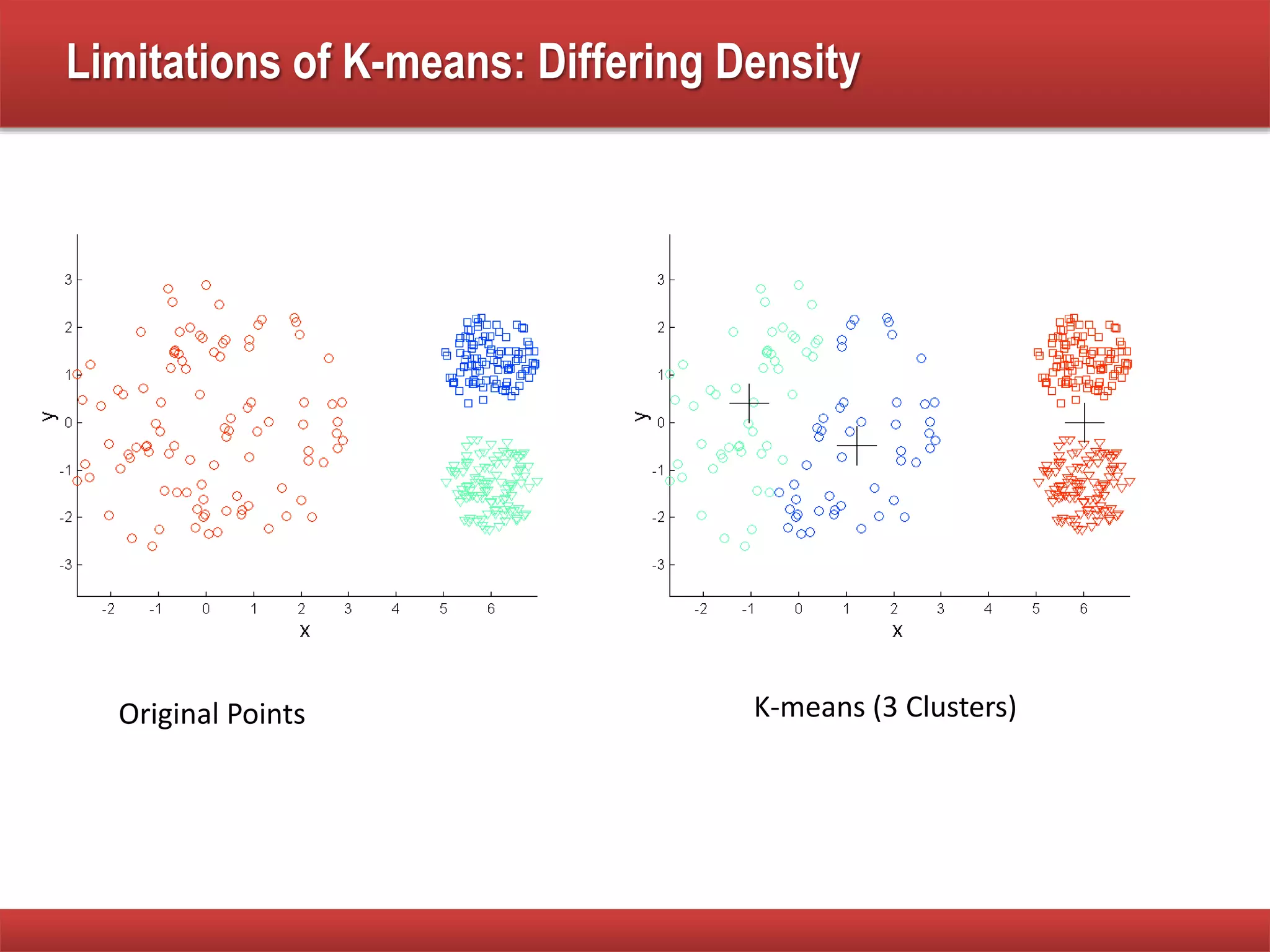
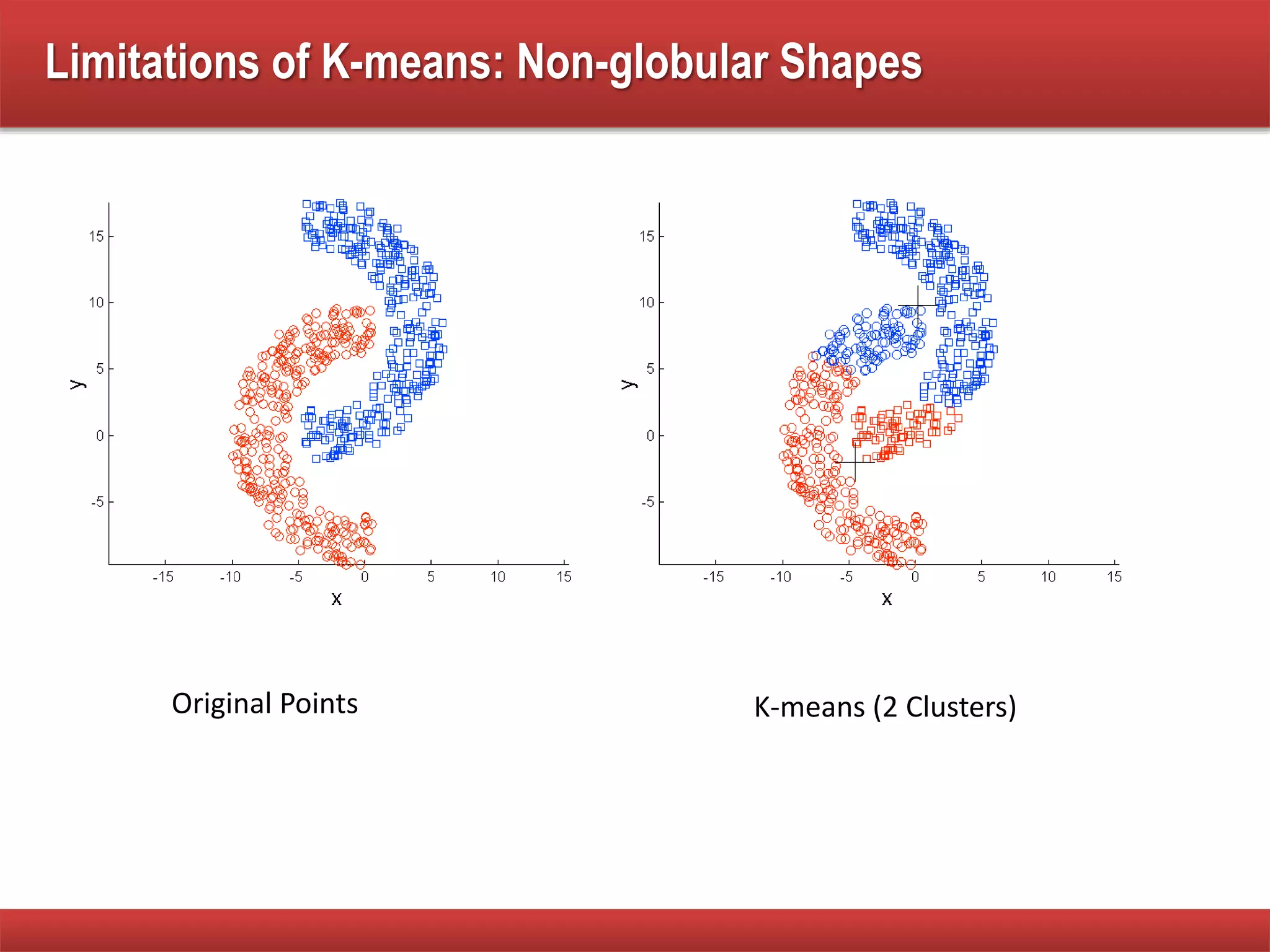
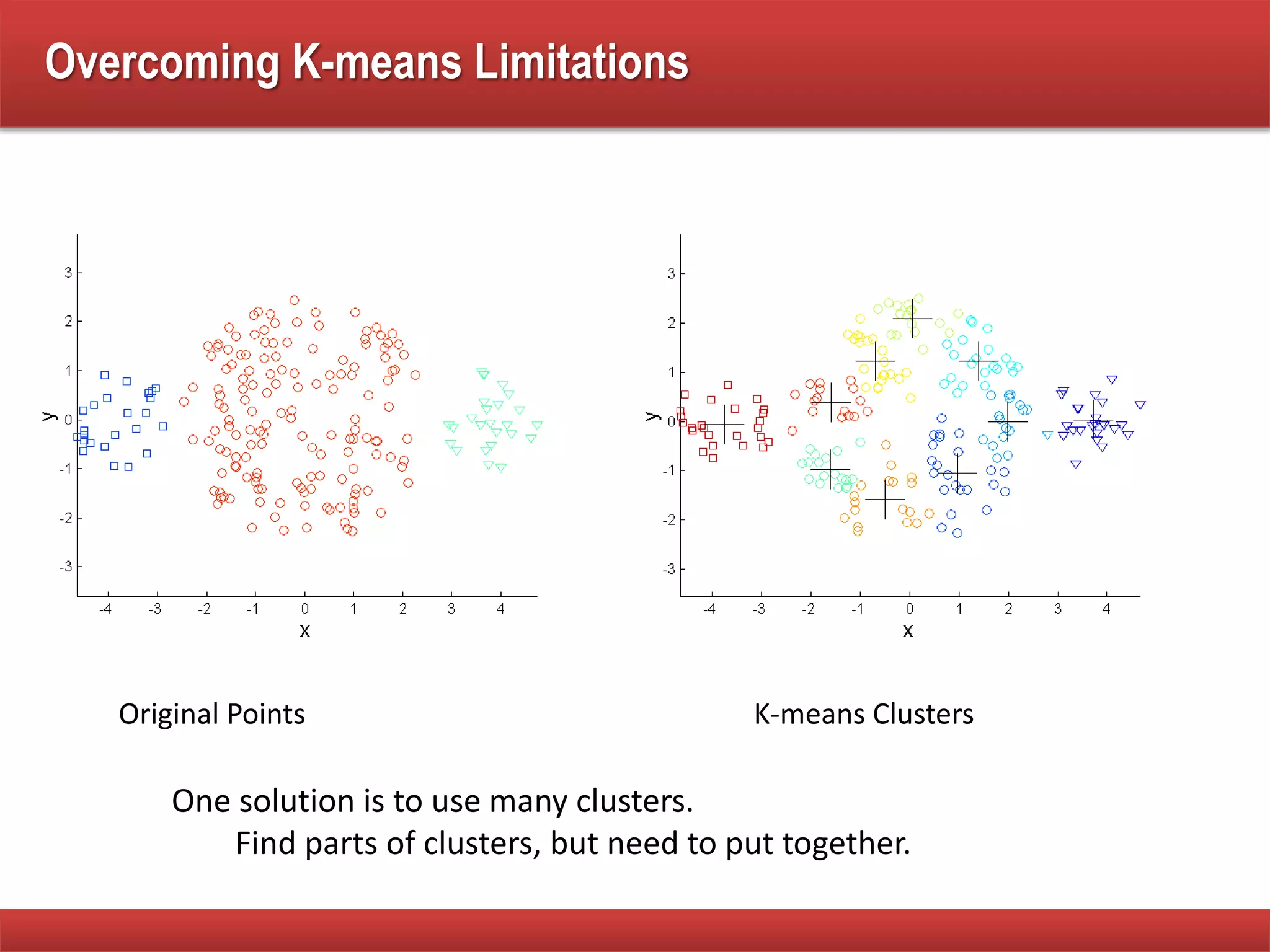
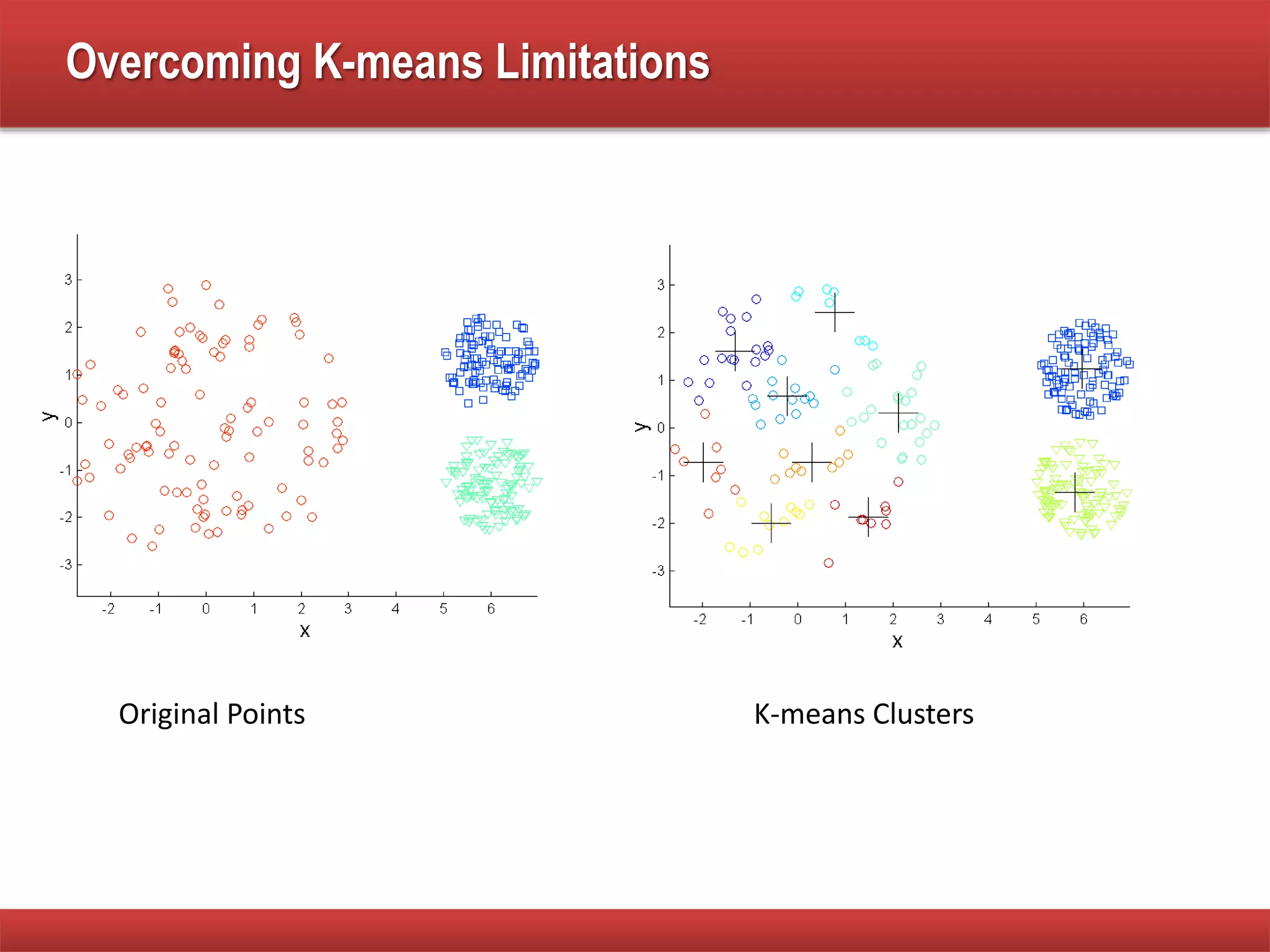
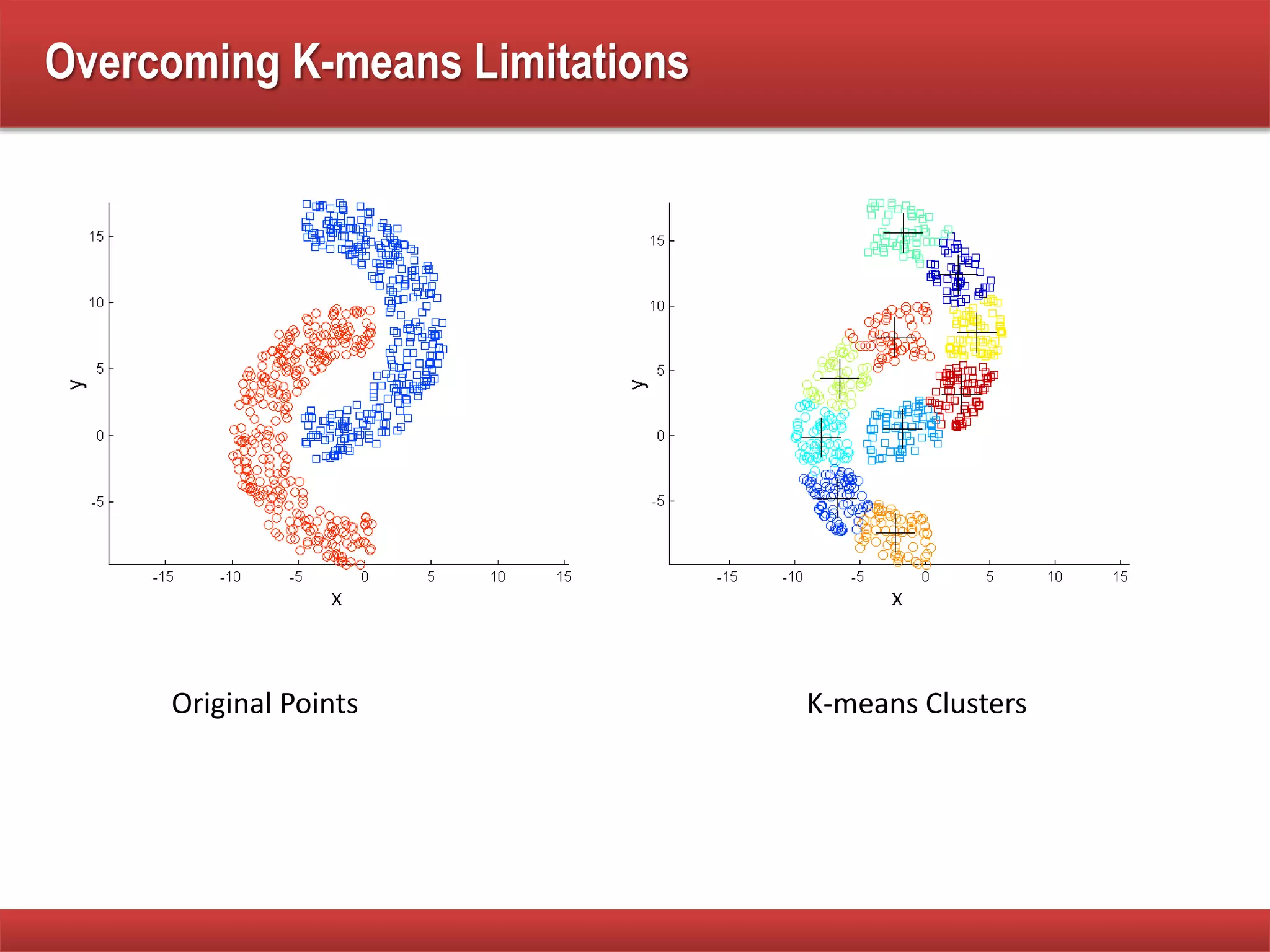





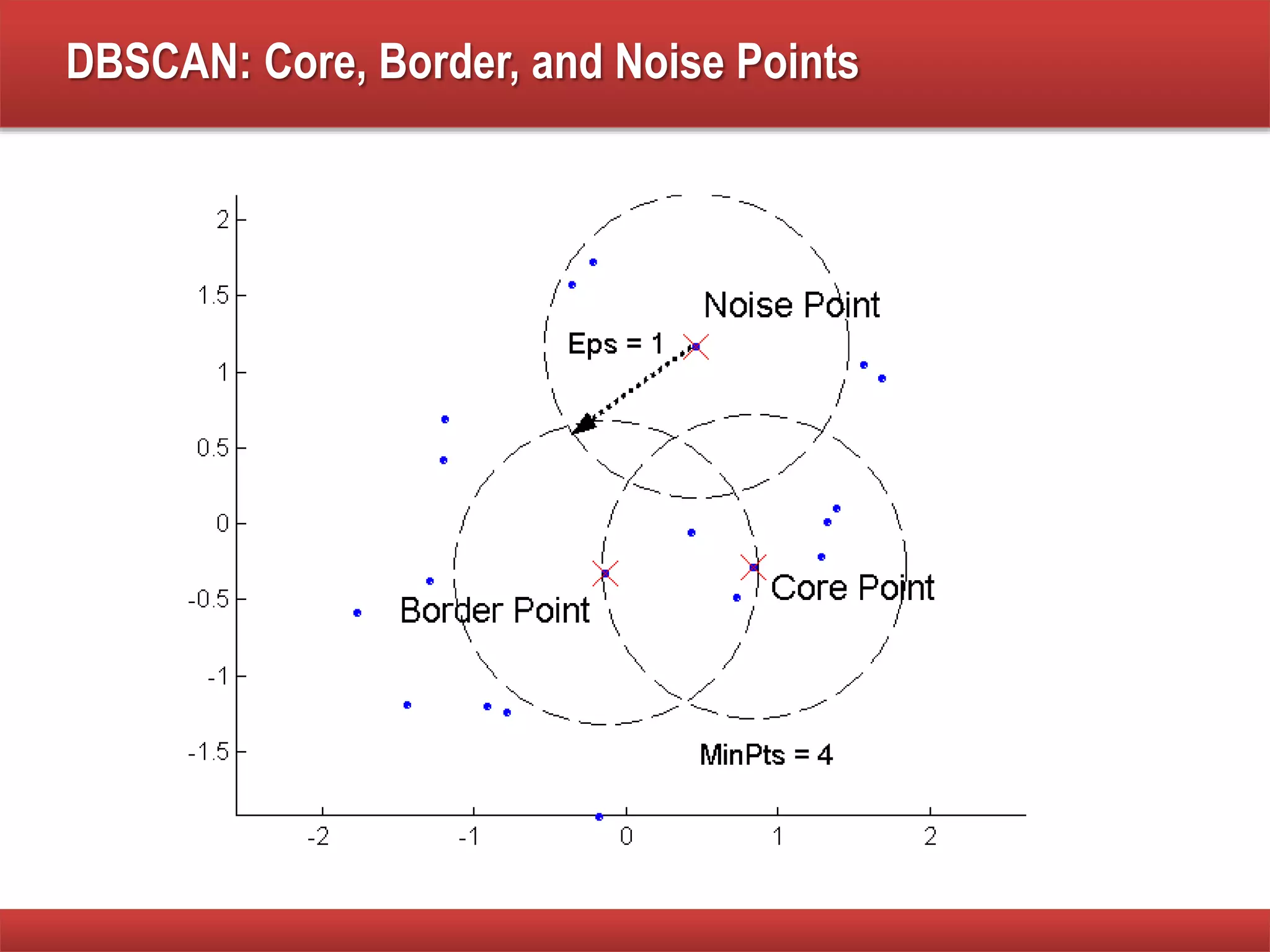




The document explains cluster analysis, focusing on finding groups of objects with similarities and distinguishing them from other groups. It discusses various applications in fields such as biology, information retrieval, and business, emphasizing the utility of clustering techniques for data simplification and organization. Additionally, it outlines different clustering types, the k-means algorithm, and its limitations regarding cluster characteristics.









































![Chapter#04[Part#01]K-Means Clusterig.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/chapter04part01k-meansclusterig-250525201708-2d369307-thumbnail.jpg?width=640&height=640&fit=bounds)













































