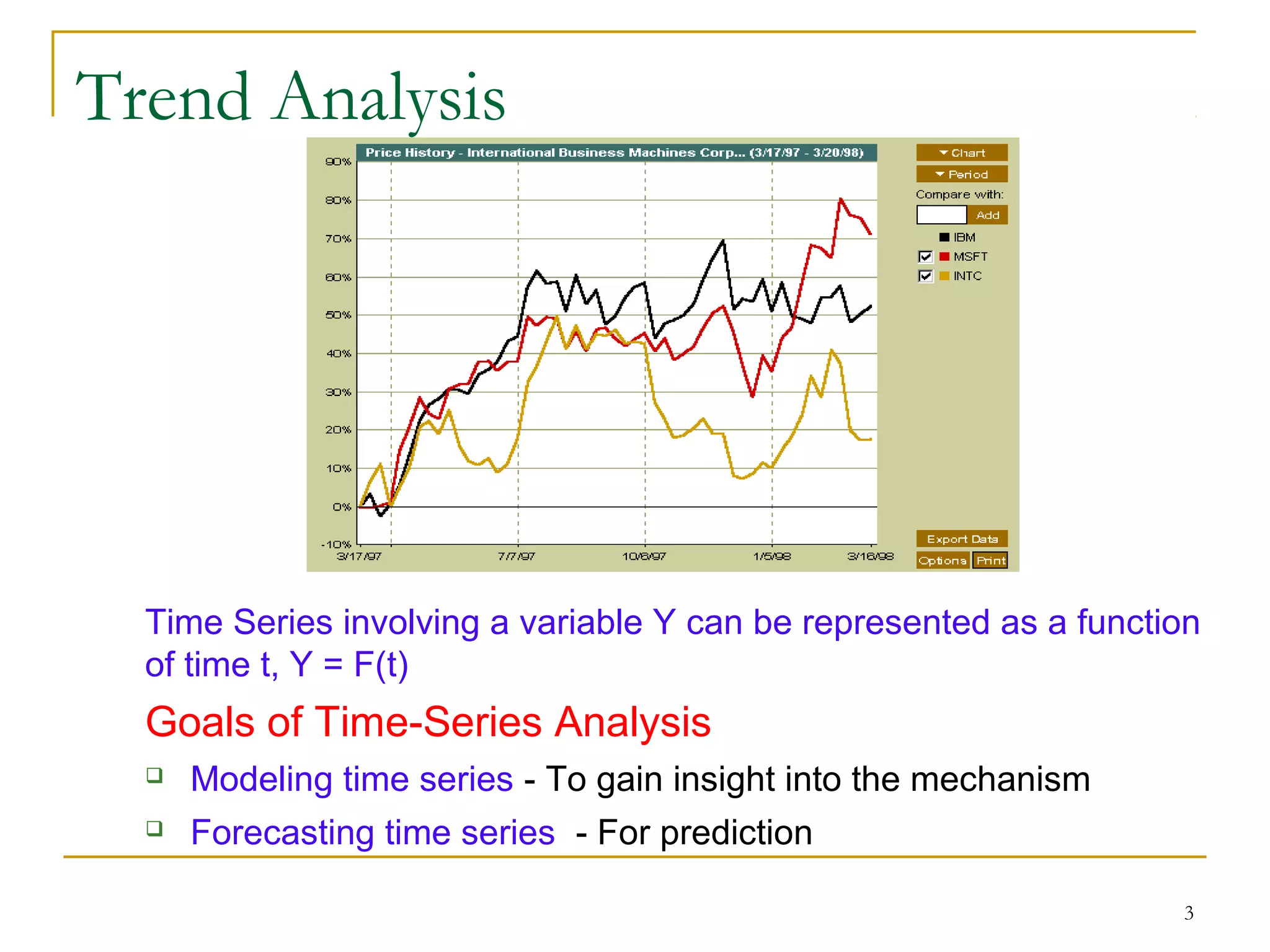
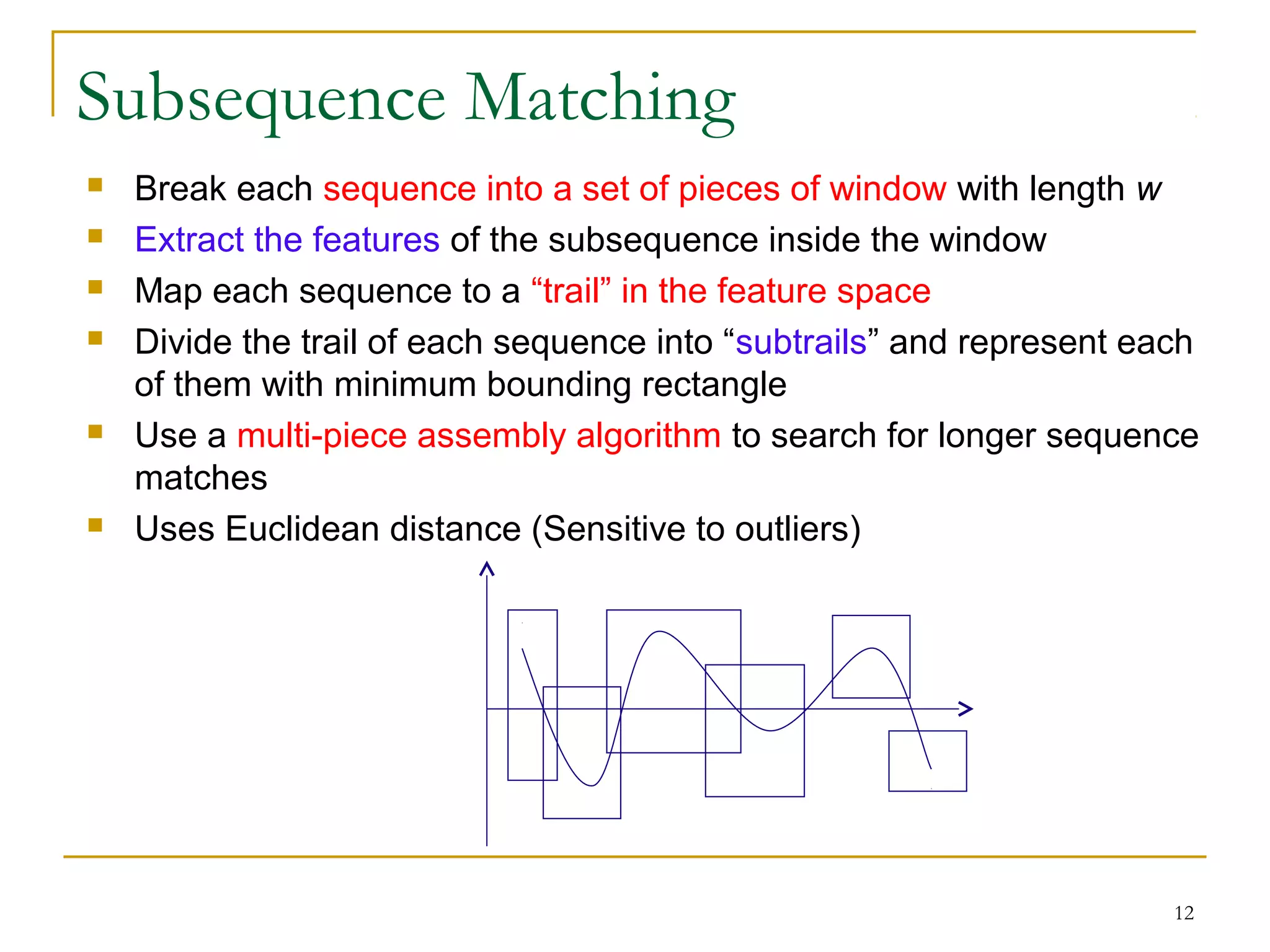
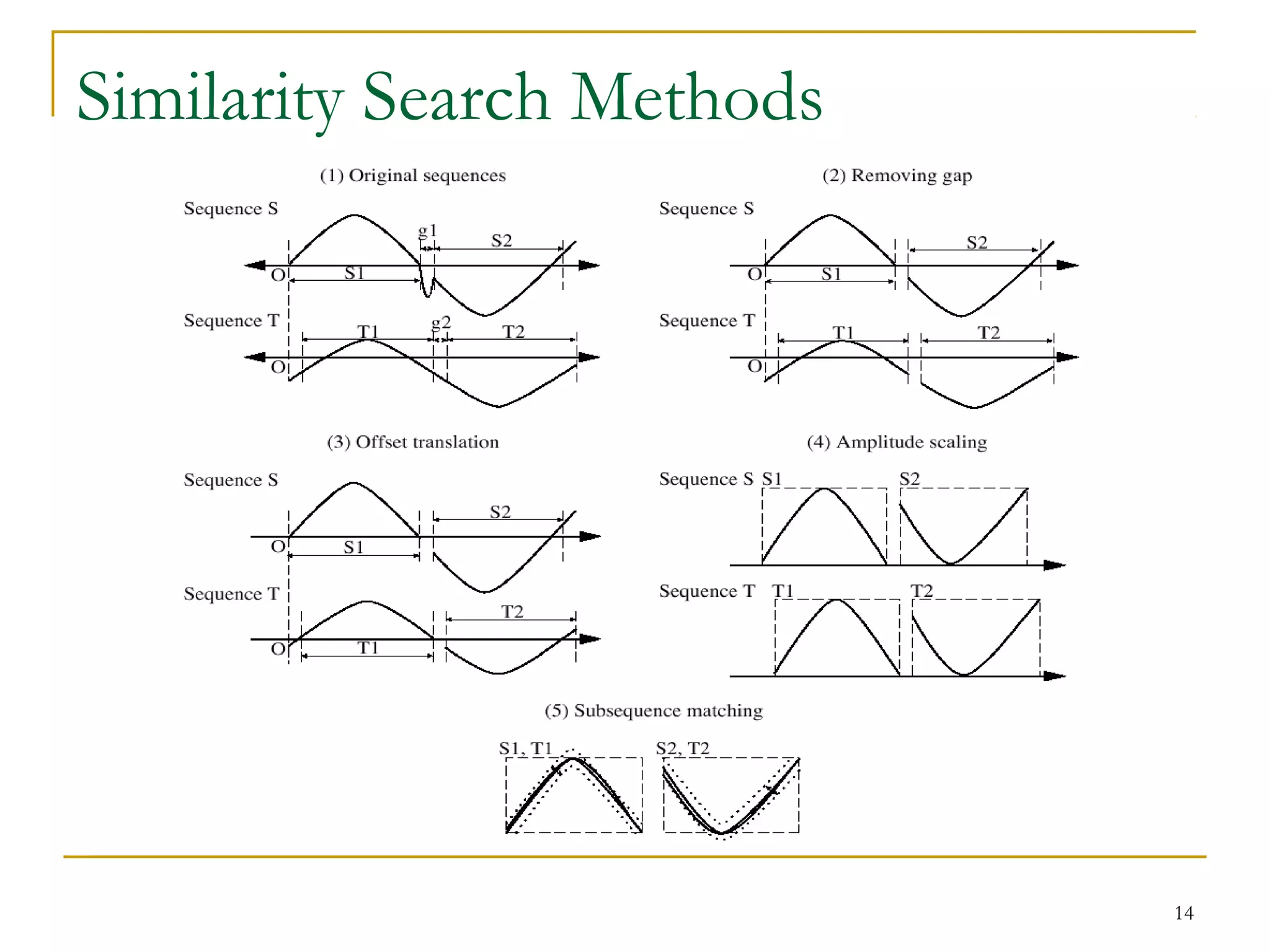
This document discusses time-series data and methods for analyzing it. Time-series data consists of sequential values measured over time that can be analyzed to identify patterns, trends, and outliers. Key methods discussed include trend analysis to identify long-term movements, seasonal variations, and irregular components; similarity search to find similar sequences; and dimensionality reduction and transformation techniques to reduce data size before analysis or indexing.
























































![[PDF] Visualizing and discovering non trivial patterns in large time-series d...](https://cdn.slidesharecdn.com/ss_thumbnails/pdfvisualizinganddiscoveringnon-trivialpatternsinlargetime-seriesdatabases-150322204558-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)











































