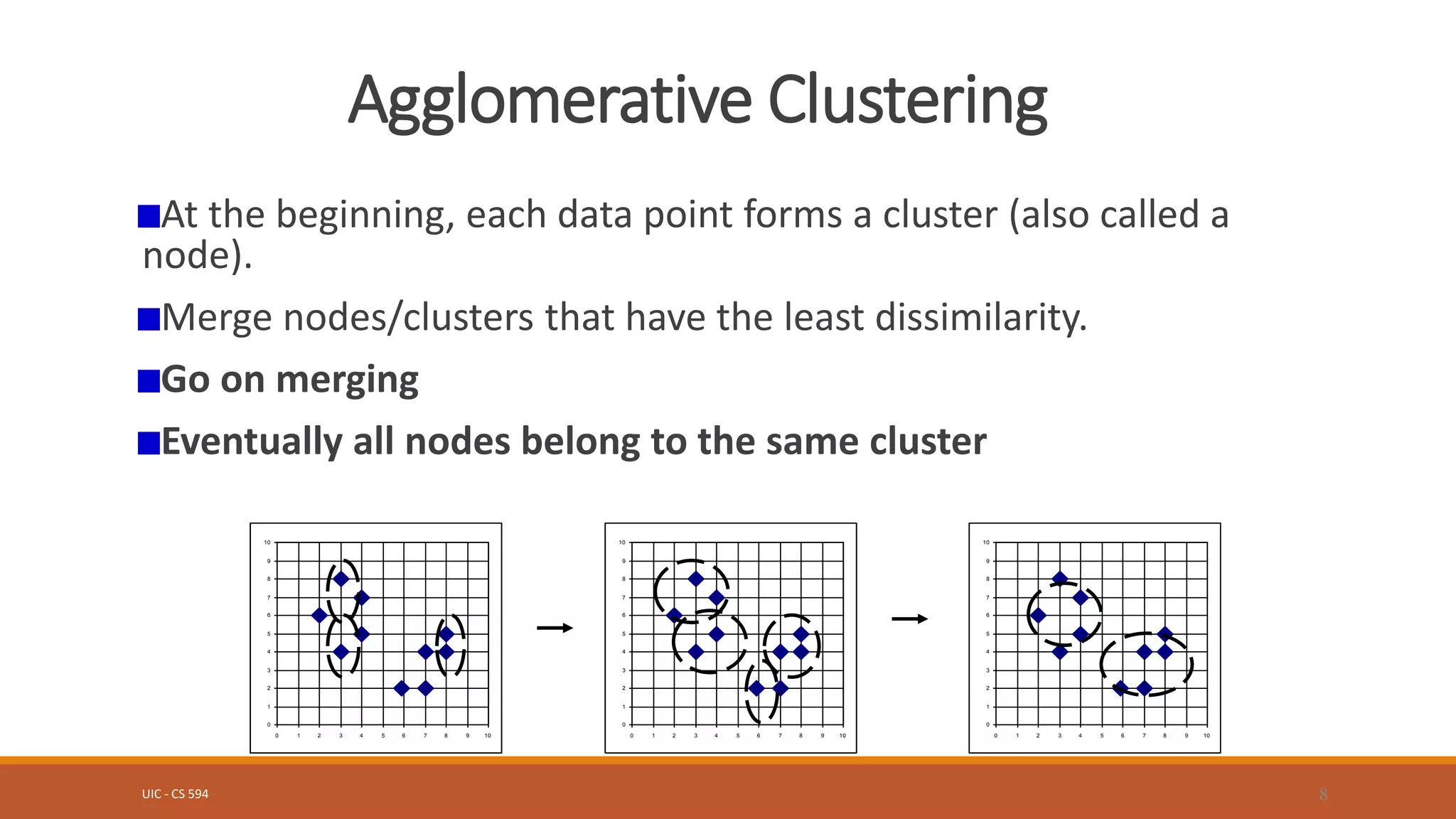
Clustering is an unsupervised machine learning technique used to group unlabeled data points. There are two main approaches: hierarchical clustering and partitioning clustering. Partitioning clustering algorithms like k-means and k-medoids attempt to partition data into k clusters by optimizing a criterion function. Hierarchical clustering creates nested clusters by merging or splitting clusters. Examples of hierarchical algorithms include agglomerative clustering, which builds clusters from bottom-up, and divisive clustering, which separates clusters from top-down. Clustering can group both numerical and categorical data.