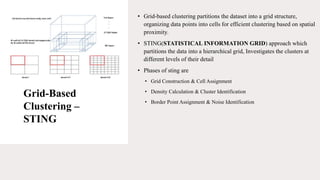
The document provides an overview of various clustering techniques used for data organization and analysis, emphasizing their evolution from biology to diverse applications in marketing, healthcare, and anomaly detection. It details techniques such as k-means, hierarchical clustering, and DBSCAN, along with their benefits and drawbacks. Additionally, it highlights future research directions, including improved visualization and integration with machine learning.