Download to read offline

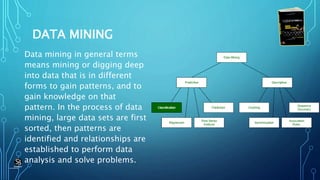





















Classification is a data analysis technique used to predict class membership for new observations based on a training set of previously labeled examples. It involves building a classification model during a training phase using an algorithm, then testing the model on new data to estimate accuracy. Some common classification algorithms include decision trees, Bayesian networks, neural networks, and support vector machines. Classification has applications in domains like medicine, retail, and entertainment.











































































![ict_presentation_final_final_final[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/ictpresentationfinalfinalfinal1-251230145259-2b4839bd-thumbnail.jpg?width=640&height=640&fit=bounds)











