Downloaded 219 times















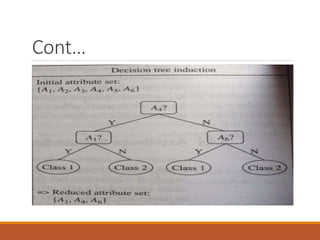


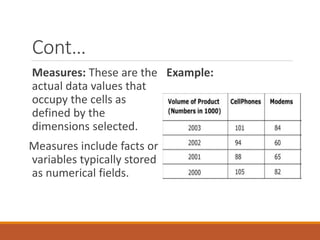






This document discusses various data reduction techniques including dimensionality reduction through attribute subset selection, numerosity reduction using parametric and non-parametric methods like data cube aggregation, and data compression. It describes how attribute subset selection works to find a minimum set of relevant attributes to make patterns easier to detect. Methods for attribute subset selection include forward selection, backward elimination, and bi-directional selection. Decision trees can also help identify relevant attributes. Data cube aggregation stores multidimensional summarized data to provide fast access to precomputed information.













































































