Downloaded 11 times





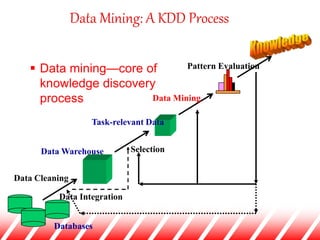







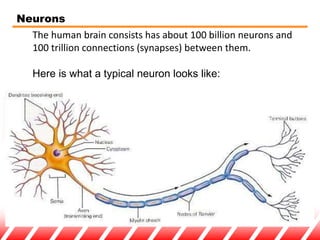
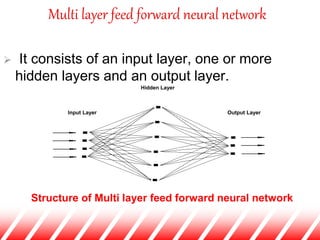


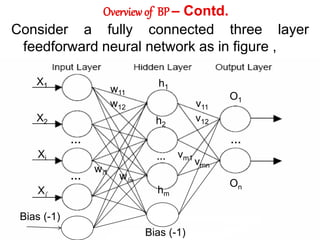
























The document provides an overview of neural networks for data mining. It discusses how neural networks can be used for classification tasks in data mining. It describes the structure of a multi-layer feedforward neural network and the backpropagation algorithm used for training neural networks. The document also discusses techniques like neural network pruning and rule extraction that can optimize neural network performance and interpretability.







![Competitive Learning [Deep Learning And Nueral Networks].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/competitivelearning-240211053020-bc9a8437-thumbnail.jpg?width=640&height=640&fit=bounds)
















































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)










