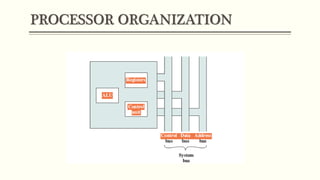
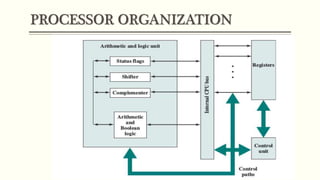
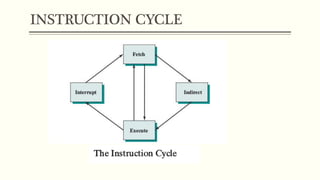
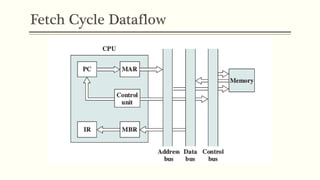
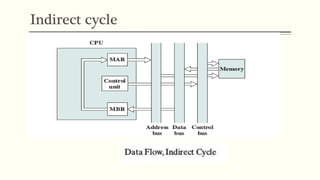
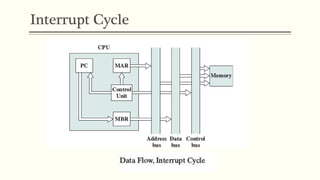
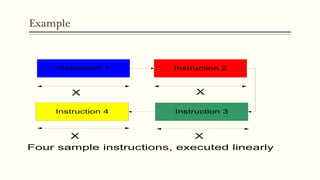
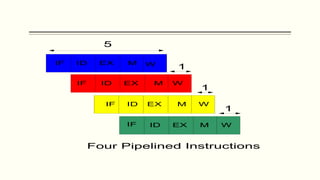
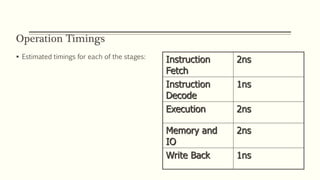
This document discusses the structure and function of a CPU. It describes the basic components of a processor including the ALU, control unit, and registers. It explains the roles of different types of registers like general purpose, data, address, and control/status registers. The document then outlines the basic instruction cycle including fetch, execute, and interrupt cycles. It provides diagrams to illustrate the data flow during these cycles. Finally, it introduces the concept of pipelining which allows overlapping the stages of instruction processing to improve processor throughput.