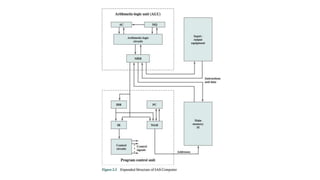
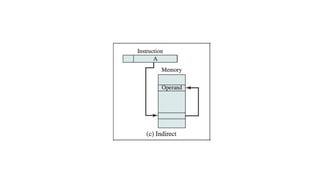
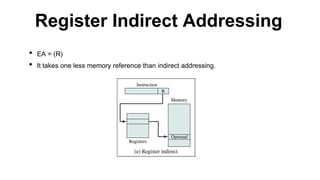
This document discusses processor organization and architecture. It covers the stored program concept where both instructions and data are stored in memory. It describes the Von Neumann architecture, which includes a main memory, ALU, control unit, and I/O. It discusses the registers used in processor control and execution like the program counter, accumulator, and instruction register. Finally, it examines addressing modes like immediate, direct, indirect, register, displacement, and stack addressing.