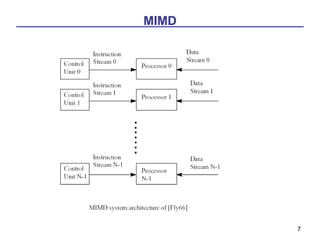
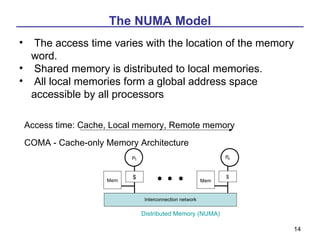
This document discusses various models of parallel computer architectures. It begins with an overview of Flynn's taxonomy, which classifies computer systems based on the number of instruction and data streams. The main categories are SISD, SIMD, MIMD, and MISD. It then covers parallel computer models in more detail, including shared-memory multiprocessors, distributed-memory multicomputers, classifications based on interconnection networks and parallelism. It provides examples of different parallel architectures and references papers on advanced computer architecture and parallel processing.














![Interconnection Network [1]
• Mode of Operation (Synchronous vs. Asynchronous)
• Control Strategy (Centralized vs. Decentralized)
• Switching Techniques (Packet switching vs. Circuit
switching)
• Topology (Static Vs. Dynamic)
17](https://image.slidesharecdn.com/ceg4131models-120316000956-phpapp02/85/Ceg4131-models-17-320.jpg)
![Classification based on the kind of
parallelism[3]
Parallel
architectures
PAs
Data-parallel architectures Function-parallel architectures
Instruction-level Thread-level Process-level
PAs
PAs PAs
DPs
ILPS MIMDs
Vector Associative SIMDs Systolic Pipelined VLIWs Superscalar Ditributed Shared
and neural architecture processors processors memory memory
architecture architecture MIMD (multi-
(multi-computer) Processors)
18](https://image.slidesharecdn.com/ceg4131models-120316000956-phpapp02/85/Ceg4131-models-18-320.jpg)
































































































