Download to read offline






![By GS kosta
Amdahl's law
In computer architecture, Amdahl's law (or Amdahl's
argument[1]
) is a formula which gives the
theoretical speedup in latency of the execution of a
task at fixed workload that can be expected of a
system whose resources are improved. It is named
after computer scientist Gene Amdahl, and was
presented at the AFIPS Spring Joint Computer
Conference in 1967
Amdahl's law is often used in parallel computing to
predict the theoretical speedup when using multiple
processors.
Amdahl's law applies only to the cases where the
problem size is fixed.](https://image.slidesharecdn.com/u1ppcexm-171114101623/85/INTRODUCTION-TO-PARALLEL-PROCESSING-8-320.jpg)
![By GS kosta
Moore’s Law
The quest for higher-performance digital computers seems unending. In
the past two decades,the performance ofmicroprocessors has enjoyed an
exponentialgrowth.The growth ofmicroprocessorspeed/performanceby
a factor of 2 every 18 months (or about 60% per
year)is known as Moore’slaw.This growth is the result ofa combination
of two factors:
1. Increase in complexity (related both to higher device density and to
larger size) ofVLSI chips,projectedto rise to around 10M transistors per
chip for microprocessors, and 1B for dynamic random-access memories
(DRAMs), by the year 2000 [SIA94]
2. Introductionof,andimprovementsin,architectural features suchas on-
chip cache memories, large instruction buffers, multiple instruction issue
per cycle, multithreading, deep pipelines, out-of-order instruction
execution, and branch prediction
Moore’s lawwas originally formulated in 1965 in terms ofthe doubling
of chip complexity every year(laterrevised to every 18months)based
only on a small numberof data points[Scha97].Moore’srevised
prediction matchesalmost perfectly the actualincreasesin the
number of transistors in DRAM and microprocessor chips.
Moore’s lawseems to hold regardlessofhowone measures
processorperformance:counting the numberofexecuted
instructionspersecond(IPS),counting the numberoffloating-point
operationspersecond (FLOPS),or using sophisticatedbenchmark
suites thatattempt to measure theprocessor'sperformance onreal
applications.This is because allof these measures,though
Figure 1.1. The exponential grow th of microprocessor performance,
know n as Moore’s law , show n overthe past two decades.](https://image.slidesharecdn.com/u1ppcexm-171114101623/85/INTRODUCTION-TO-PARALLEL-PROCESSING-9-320.jpg)



![By GS kosta
The ideal speed up formula given below:
is based on a fixed workload, regardless of machine size.
We consider below two cases of DOP< n and of DOP ≥ n.
Parallel algorithm
In computer science, a parallel algorithm, as opposed to a traditional serial algorithm, is an algorithm which can
be executed a piece at a time on many different processing devices, and then combined together again at the end
to get the correct result.[1]
Many parallel algorithms are executed concurrently – though in general concurrent algorithms are a distinct
concept – and thus these concepts are often conflated, with which aspect of an algorithm is parallel and which is
concurrent not being clearly distinguished. Further, non-parallel, non-concurrent algorithms are often referred to
as "sequential algorithms", by contrast with concurrent algorithms.
Examples of Parallel Algorithms
This section describes and analyzes several parallel algorithms. These algorithms provide examples of how to analyze algorithms in terms of work
and depth and of how to use nested data-parallel constructs. They also introduce some important ideas concerning parallel algorithms. We mention
again that the main goals are to have thecode closely match the high-level intuition of the algorithm, and to make it easy to analyzethe asymptotic
performance from the code.
Parallel Algorithm Complexity
Analysis of an algorithm helps us determine whether the algorithm is useful or not. Generally, an algorithm is analyzed based on its
execution time (Time Complexity) and the amount of space (Space Complexity) it requires.
Since we have sophisticated memory devices available at reasonable cost, storage space is no longer an issue. Hence, spa ce
complexity is not given so much of importance.
Parallel algorithms are designed to improve the computation speed of a computer. For analyzing a Parallel Algorithm, we norma lly
consider the following parameters −
Time complexity (Execution Time),](https://image.slidesharecdn.com/u1ppcexm-171114101623/85/INTRODUCTION-TO-PARALLEL-PROCESSING-13-320.jpg)


![By GS kosta
THE PRAM SHARED-MEMORY MODEL
The theoretical model used for conventional or sequential computers (SISD class) is
known as therandom-access machine (RAM) (not to be confused with random-access
memory, which has the same acronym). Theparallel version of RAM [PRAM (pea-ram)],
constitutes an abstract model of the class of global-memory parallel processors. The
abstraction consists of ignoring the details of the processor-to-memory interconnection
network and taking theview that each processor can access any memory location in each
machine cycle, independent of what other processors are doing
DISTRIBUTED-MEMORY OR GRAPH MODELS
This network is usually represented as a graph, with vertices corresponding to processor–memory nodes and edges corresponding to
communication links. If communication links are unidirectional, then directed edges are used. Undirected edges imply bidirectional
communication, although not necessarily in both directions at once. Important parameters of an interconnection network include
1. Network diameter: thelongest of the shortest paths
between various pairs of nodes, which should be
relatively small if network latency is to be minimized.
The network diameter is more important with store-and-
forward routing (when a message is stored in its entirety
and retransmitted by intermediate nodes) than with
wormhole routing (when a message is quickly relayed
through a node in small pieces).
2. Bisection (band)width: thesmallest number (total
capacity) of links that need to be cut in order to divide
the network into two subnetworks of half the size. This
is important when nodes communicate with each other
in a random fashion. A small bisection (band)width
limits the rate of data transfer between thetwo halves of
the network, thus affecting theperformance of
communication-intensive algorithms.
3. Vertex or node degree: the number of communication
ports required of each node, which should be a constant
independent of network size if the architecture is to be
readily scalable to larger sizes. Thenode degree has a
direct effect on thecost of each node, with the effect
being more significant for parallel ports containing
several wires or when the node is required to
communicate over all of its ports at once.
CIRCUIT MODEL AND PHYSICAL REALIZATIONS
In a sense, the only sure way to predict the performance of a parallel architecture on a
given set of problems is to actually build themachine and run the programs on it. Because
this is often impossible or very costly, the next best thing is to model themachine at the
circuit level, so that all computationaland signal propagation delays can be taken into
account. Unfortunately, this is also impossible for a complex supercomputer, both because
generating and debugging detailed circuit specifications are not much easier than a
fullblown
implementation and because a circuit simulator would take eons to run the simulation.
Despitetheabove observations, we can produce and evaluate circuit-level designs for
specific applications.
GLOBAL VERSUS DISTRIBUTED MEMORY
Within the MIMDclass ofparallelprocessors,memory can be globalordistributed.
Global memory may be visualized as being in a central location where all processors can
access it with equal ease (or with equal difficulty, if you are a half-empty-glass typeof
person). Figure 4.3 shows a possiblehardware organization for a global-memory parallel
processor. Processors can access memory through a special processor-to-memory network.
A global-memory multiprocessor is characterized by the typeand number p of processors,
the capacity and number m of memory modules, and the network architecture. Even though
p and m are independent parameters, achieving high performance typically requires that they
be comparable in magnitude (e.g., too few memory modules will cause contention among
the processors and too many would complicate the network design).](https://image.slidesharecdn.com/u1ppcexm-171114101623/85/INTRODUCTION-TO-PARALLEL-PROCESSING-16-320.jpg)
![By GS kosta
Distributed-memory architectures can be conceptually viewed as in Fig. 4.5. A collection of p processors, each with its own privatememory,
communicates through an interconnection network. Here, the latency of the
interconnection network may be less critical, as each processor is likely to
access its own local memory most of the time. However, the communication
bandwidth of thenetwork may or may not be critical, depending on the typeof
parallel applications and the extent of task interdependencies. Note that each
processor is usually connected to thenetwork through multiple links or channels
(this is the norm here ,although it can also be the case for shared-memory
parallel processors).
Cache coherence
In computer architecture, cache coherence is the uniformity
of shared resource data that ends up stored in multiple local
caches. When clients in a system maintain caches of a
common memory resource, problems may arise with
incoherent data, which is particularly the case with CPUs in
a multiprocessingsystem.
In the illustration on the right, consider both the clients have
a cached copy of a particular memory block from a previous
read. Suppose the client on the bottom updates/changes
that memory block, the client on the top could be left with an
invalid cache of memory without any notification of the
change. Cache coherence is intended to manage such
conflicts by maintaining a coherent view of the data values in
multiple caches.
The following are the requirements for cache coherence:[2]
Write Propagation
Changes to the data in any cache must be propagated to other copies(of that cache line) in the peer
caches.
Transaction Serialization
Reads/Writes to a single memory location must be seen by all processors in the same order.
Coherence protocols
Coherence Protocols apply cache coherence in multiprocessor systems. The intention is that two clients must
never see different values of the same shared data.
The protocol must implement the basic requirements for coherence. It can be tailor made for the target
system/application.
Protocols can also be classified as Snooping(Snoopy/Broadcast) or Directory based. Typically, early systems
used directory based protocols where a directory would keep a track of the data being shared and the sharers. In
Snoopy protocols , the transaction request. (read/write/upgrade) are sent out to all processors. All processors
snoop the request and respond appropriately.
Write Propagation in Snoopy protocols can be implemented by either of the following:
Write Invalidate
When a write operation is observed to a location that a cache has a copy of, the cache controller
invalidates its own copy of the snooped memory location, and thus forcing reads from main memory of the
new value on their next access.[4]
Write Update
When a write operation is observed to a location that a cache has a copy of, the cache controller updates
its own copy of the snooped memory location with the new data.](https://image.slidesharecdn.com/u1ppcexm-171114101623/85/INTRODUCTION-TO-PARALLEL-PROCESSING-17-320.jpg)



![By GS kosta
interaction minimization technique applicable to this model is overlapping interaction
with computation.
Example − Parallel LU factorization algorithm.
Hybrid Models
A hybrid algorithm model is required when more than one model may be needed to
solve a problem.
A hybrid model may be composed of either multiple models applied hierarchically or
multiple models applied sequentially to different phases of a parallel algorithm.
Example − Parallel quick sort
Shared memory/Parallel Processing in Memory
In computer science, shared memory is memory that may be
simultaneously accessed by multiple programs with an intent
to provide communication among them or avoid redundant
copies. Shared memory is an efficient means of passing data
between programs. Depending on context, programs may
run on a single processor or on multiple separate
processors.
Using memory for communication inside a single
program, e.g. among its multiple threads, is also referred
to as shared memory.
In hardware[edit]
In computer hardware, shared memory refers to a (typically large) block of random access memory (RAM) that
can be accessed by several different central processing units (CPUs) in a multiprocessor computer system.
Shared memory systems may use:[1]
uniform memory access (UMA): all the processors share the physical memory uniformly;
non-uniform memory access (NUMA): memory access time depends on the memory location relative to a
processor;
cache-only memory architecture (COMA): the local memories for the processors at each node is used as
cache instead of as actual main memory.
In software[edit]
In computer software, shared memory is either](https://image.slidesharecdn.com/u1ppcexm-171114101623/85/INTRODUCTION-TO-PARALLEL-PROCESSING-22-320.jpg)


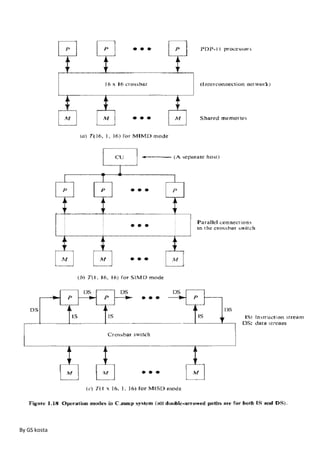
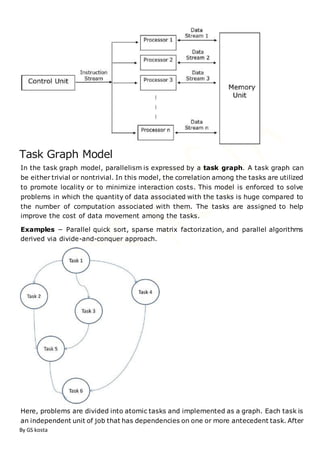
This document discusses parallel processing and the evolution of computer systems. It covers several topics: - The evolution of computer systems from vacuum tubes to integrated circuits, organized into generations. - Concepts of parallel processing including Flynn's classification of computer architectures based on instruction and data streams. - Parallel processing mechanisms in uniprocessor systems including pipelining and memory hierarchies. - Three classes of parallel computer structures: pipeline computers, array processors, and multiprocessor systems. - Architectural classification schemes including Flynn's, Feng's based on serial vs parallel processing, and Handler's based on parallelism levels.



































































