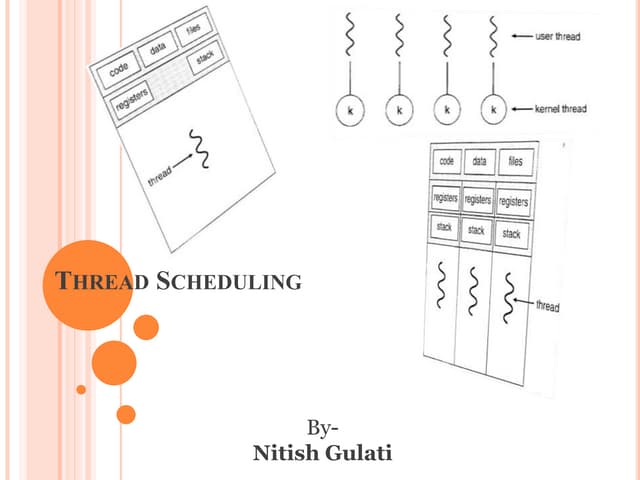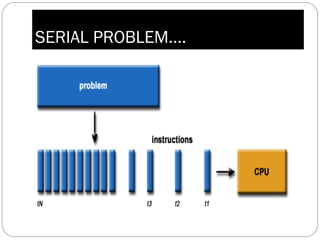

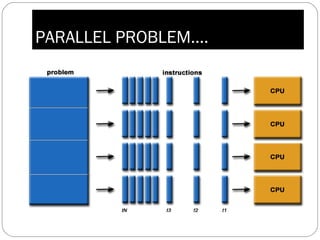


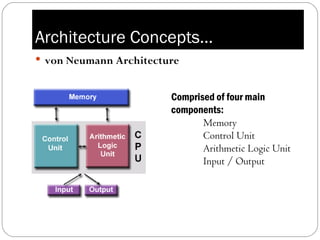



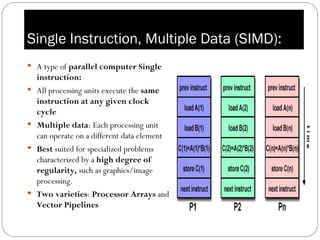



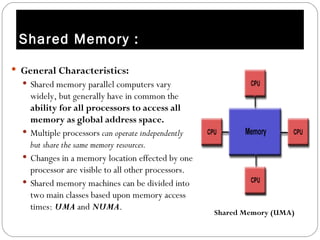

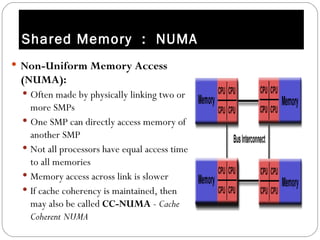
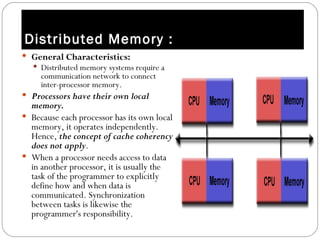
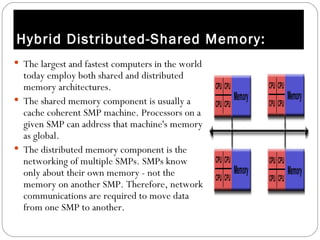



Parallel computing involves solving computational problems simultaneously using multiple processors. It can save time and money compared to serial computing and allow larger problems to be solved. Parallel programs break problems into discrete parts that can be solved concurrently on different CPUs. Shared memory parallel computers allow all processors to access a global address space, while distributed memory systems require communication between separate processor memories. Hybrid systems combine shared and distributed memory architectures.