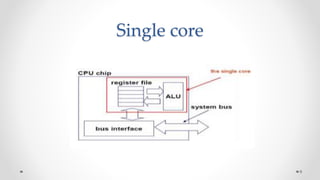
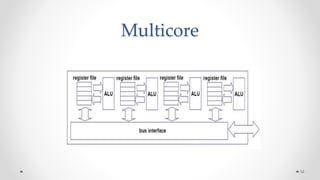
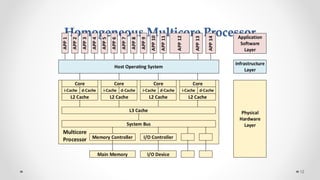
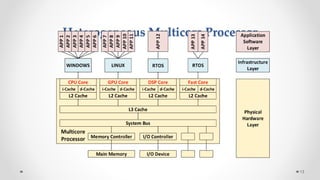
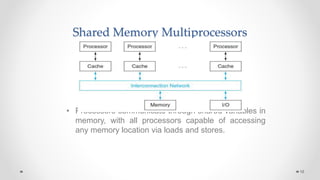
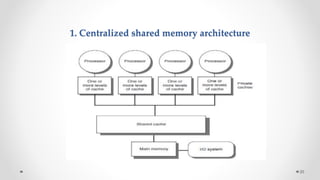
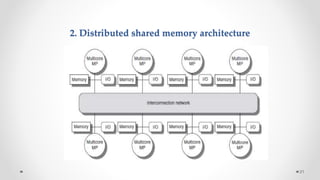
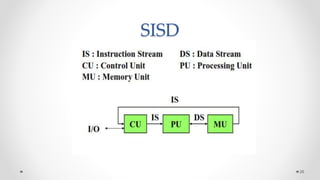
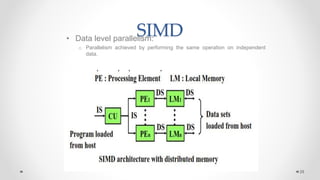
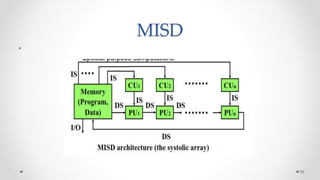
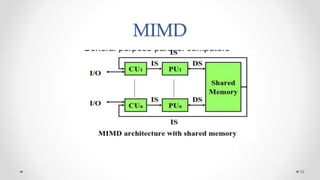
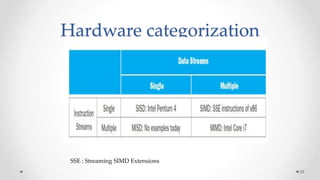
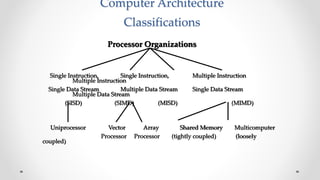
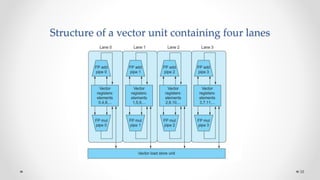
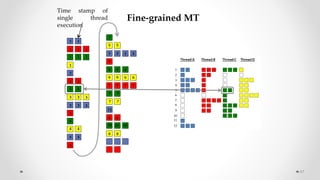
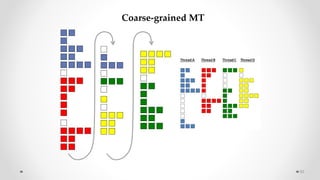
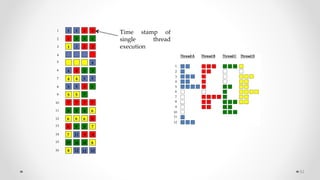
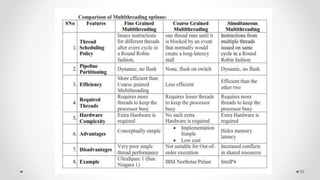
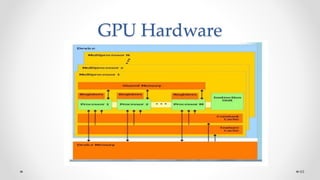
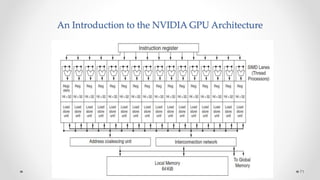
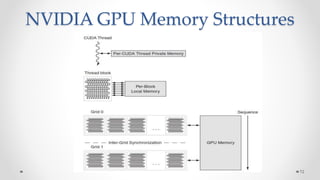
The document provides an overview of multicore processors and shared memory multiprocessors in computer architecture, including Flynn's classification and hardware multithreading concepts. It outlines various types of multicore processors (homogeneous and heterogeneous) and shared memory architectures (UMA and NUMA). Additionally, the document discusses parallelism in computing and the architecture of GPUs, emphasizing their role in visual computing.