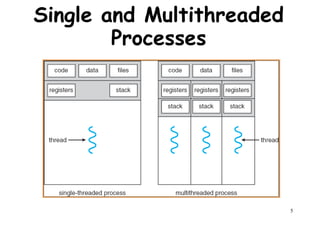
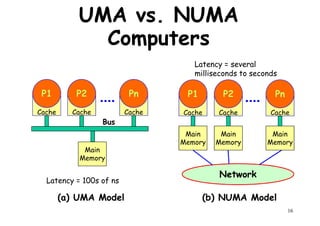
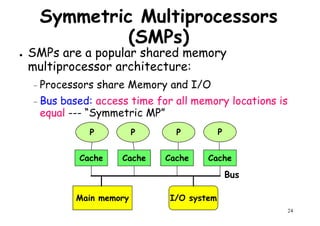
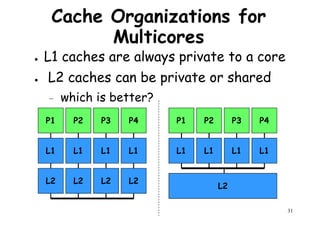
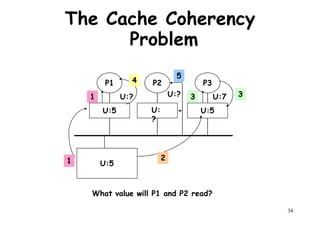
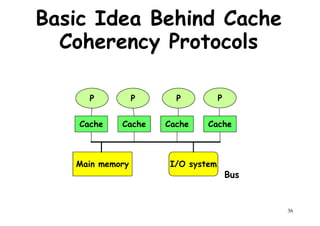
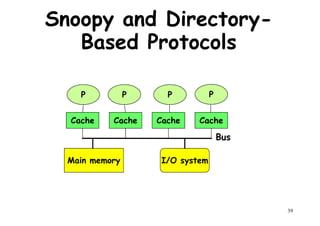
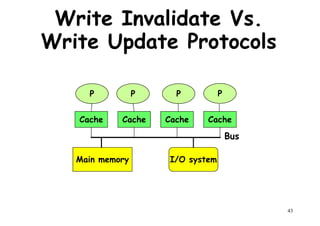
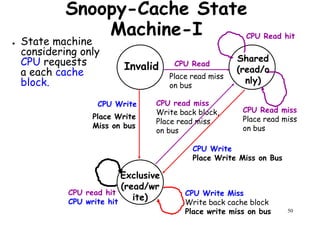
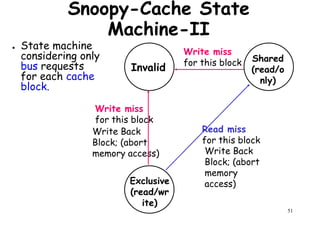
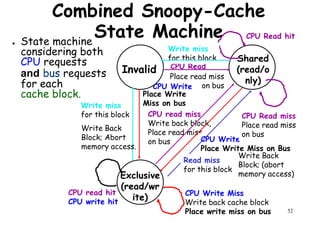
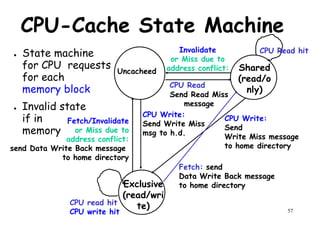
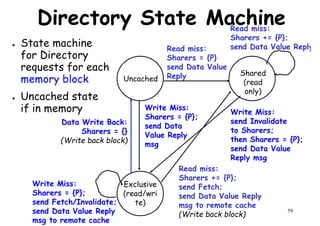
This document provides an introduction to high performance computer architecture and multiprocessors. It discusses how initial improvements in computer performance came from innovative manufacturing techniques and exploitation of instruction level parallelism (ILP). More recently, exploiting thread and process level parallelism across multiple processors has become a focus. The key types of multiprocessor architectures discussed are symmetric multiprocessors (SMPs) and distributed memory computers which use message passing. SMPs connect multiple processors to a shared memory using a bus, while distributed memory computers require explicit message passing between separate processor memories.