Download as PDF, PPTX















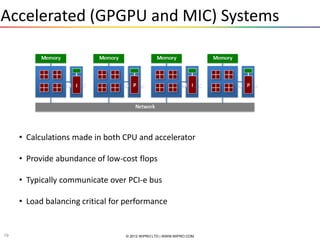









![MPI Example #1
• Every MPI program needs these:
#include “mpi.h”
int main(int argc, char *argv[])
{
int nPEs, iam;
/* Initialize MPI */
ierr = MPI_Init(&argc, &argv);
/* How many total PEs are there */
ierr = MPI_Comm_size(MPI_COMM_WORLD, &nPEs);
/* What node am I (what is my rank?) */
ierr = MPI_Comm_rank(MPI_COMM_WORLD, &iam);
ierr = MPI_Finalize();
}
33 © 2012 WIPRO LTD | WWW.WIPRO.COM](https://image.slidesharecdn.com/introtoparallelcomputing-130408003748-phpapp02/85/Intro-to-parallel-computing-33-320.jpg)
![MPI Example #2
#include “mpi.h”
int main(int argc, char *argv[])
{
int numprocs, myid;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD,&numprocs);
MPI_Comm_rank(MPI_COMM_WORLD,&myid);
/* print out my rank and this run's PE size */
printf("Hello from %d of %dn", myid, numprocs);
MPI_Finalize();
}
34 © 2012 WIPRO LTD | WWW.WIPRO.COM](https://image.slidesharecdn.com/introtoparallelcomputing-130408003748-phpapp02/85/Intro-to-parallel-computing-34-320.jpg)






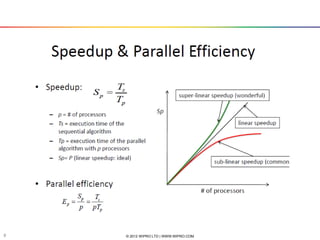
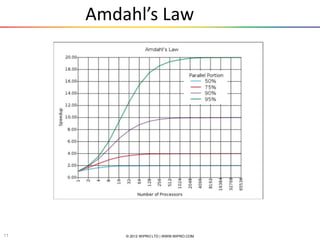
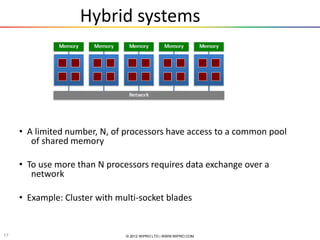
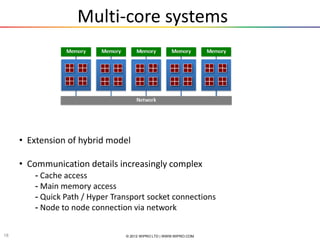
The document provides an introduction and overview of parallel computing. It discusses parallel computing systems and parallel programming models like MPI and OpenMP. It covers theoretical concepts like Amdahl's law and practical limits of parallel computing related to load balancing and non-computational sections. Examples of parallel programming using MPI and OpenMP are also presented.












































![[Harvard CS264] 07 - GPU Cluster Programming (MPI & ZeroMQ)](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201107-mpi0mq-110308182928-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






























