The document provides an introduction to parallel programming concepts. It discusses Flynn's taxonomy of parallel systems including SISD, SIMD, MIMD, and MISD models. It then gives examples of adding two vectors in parallel using different models like SISD, SIMD, SIMD-SIMT, MIMD-MPMD, and MIMD-SPMD. It also covers parallel programming concepts like synchronization, computational patterns like map, reduce, and pipeline, and data usage patterns like gather, scatter, subdivide and pack. Finally, it provides an overview of CUDA hardware including its memory model, execution model using kernels, blocks, threads and warps. It highlights some caveats of CUDA like data




![SISD
• Set CX = 0
• Load AX, Array1[CX]
• Load BX, Array2[CX]
• Add AX,BX
• Store Arrary3[CX],ax
• Inc CX
• Loop CX < Length](https://image.slidesharecdn.com/paralell-130425224609-phpapp01/85/Paralell-5-320.jpg)

![SIMD-SIMT (CUDA/OpenCL)
• ThreadID=1
• Set CX = ThreadId
• Load
AX, Array1[CX]
• Load
BX, Array2[CX]
• Add AX,BX
• Store
Arrary3[CX],ax
• ThreadID=2
• Set CX = ThreadID
• Load
AX, Array1[CX]
• Load
BX, Array2[CX]
• Add AX,BX
• Store
Arrary3[CX],ax
• ThreadID=n
• Set CX = ThreadID
• Load
AX, Array1[CX]
• Load
BX, Array2[CX]
• Add AX,BX
• Store
Arrary3[CX],ax](https://image.slidesharecdn.com/paralell-130425224609-phpapp01/85/Paralell-7-320.jpg)

![MIMD-SPMD
• Set CX = 0
• Load AX, Array1[CX]
• Load BX, Array2[CX]
• Add AX,BX
• Store Arrary3[CX],ax
• Inc CX
• Loop CX < Length/2
• Wait for thread 2
• Set CX = Length/2
• Load AX, Array1[CX]
• Load BX, Array2[CX]
• Add AX,BX
• Store Arrary3[CX],ax
• Inc CX
• Loop CX < Length
• Wait for thread 1](https://image.slidesharecdn.com/paralell-130425224609-phpapp01/85/Paralell-9-320.jpg)



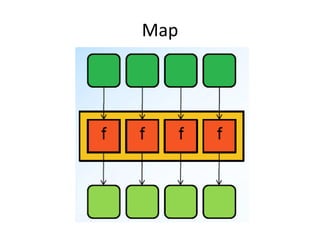
![Map
• Applies a function to one or more collections
and creates a new collection of the results.
– B[] = inc(A[])
– C[] = add(A[],B[])
• Variation of Map is Transform which does this
in place.
• f() is a pure function. Almost impossible to use
non-pure function except in SISD systems.](https://image.slidesharecdn.com/paralell-130425224609-phpapp01/85/Paralell-13-320.jpg)
![Reduction/Fold
• Applies a binary function to a collection
repeatedly till only one value is left.
– B = sum(A[])
– C = max(A[])](https://image.slidesharecdn.com/paralell-130425224609-phpapp01/85/Paralell-15-320.jpg)

![Pipeline
• Multiple functions are applied to a collection
where the output of each function serves as
the input to the next function
– B[] = f(g(A[]))](https://image.slidesharecdn.com/paralell-130425224609-phpapp01/85/Paralell-18-320.jpg)


![Gather
• Takes a collection of indices and creates a
collection from another that includes only the
given indices.
• A[] = {a,b,c,d,e,f,g,h,i}
• B[] = {1,4,8}
• {a,d,h} = gather(A,B)](https://image.slidesharecdn.com/paralell-130425224609-phpapp01/85/Paralell-21-320.jpg)
![Subdivide
• Creates multiple smaller collections from one
collection.
• Many variations based on spatial properties of
source and destination collections.
• A[] = {a,b,c,d,e,f,g,h}
• subdivide(A,4) = {a,b,c,d},{e,f,g,h}
• neighbors(A) = {a,b,c},{b,c,d},{c,d,e},…,{f,g,h}](https://image.slidesharecdn.com/paralell-130425224609-phpapp01/85/Paralell-22-320.jpg)
![Scatter
• Takes a collection of indices and updates a
collection from another that includes only the
given indices.
• Can be non-deterministic if B doesn’t contain
unique indices
• A[] = {a,b,c,d,e,f,g,h,i}
• B[] = {0,1,0,8,0,0,4,0}
• C[] = {m,n,o,p,q,r,s,t,v}
• {m,a,o,h,p,q,d,s,t,v} = scatter(a,b,c)](https://image.slidesharecdn.com/paralell-130425224609-phpapp01/85/Paralell-23-320.jpg)
![Pack
• Takes a collection and creates a new collection
based on a unary boolean function.
• A[] = {a,b,c,d,e,f,g,h,i}
• B[] = {0,1,0,8,0,0,4,0}
• Pack(A,vowels(x)) = {a,e,i}
• Pack(b, f(x>4)) = {8}](https://image.slidesharecdn.com/paralell-130425224609-phpapp01/85/Paralell-24-320.jpg)
































































![[Harvard CS264] 07 - GPU Cluster Programming (MPI & ZeroMQ)](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201107-mpi0mq-110308182928-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
