Downloaded 114 times



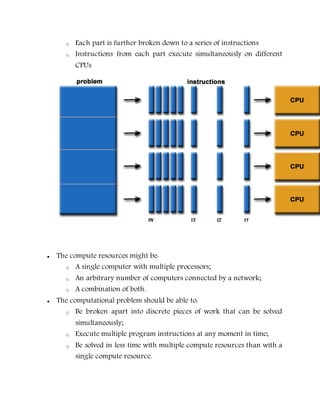











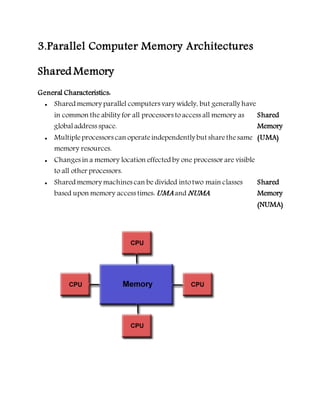
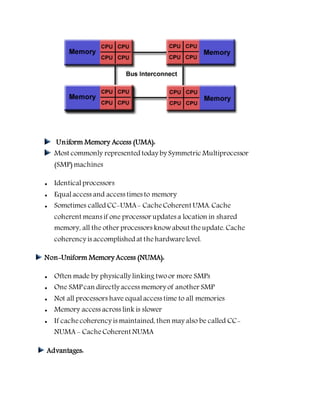


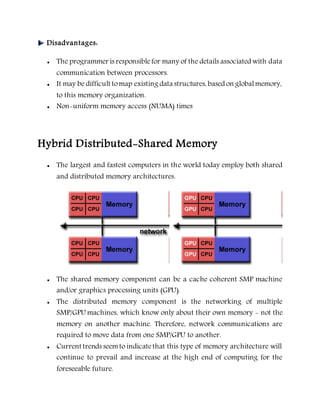














This document provides an overview of parallel computing concepts. It defines parallel computing as using multiple compute resources simultaneously to solve a problem by breaking it into discrete parts that can be solved concurrently. It discusses Flynn's taxonomy for classifying computer architectures based on whether their instruction and data streams are single or multiple. Shared memory, distributed memory, and hybrid memory models are described for parallel computer architectures. Programming models like shared memory, message passing, data parallel and hybrid models are covered. Reasons for using parallel computing include saving time/money, solving larger problems, providing concurrency, and limits of serial computing.






























































































