Downloaded 676 times



![WHAT IS A PARALLEL INSTRUCTION?
Parallel instructions are a set of instructions that do not depend on each other
to be executed.
Hierarchy
Bit level Parallelism
• 16 bit add on 8 bit processor
Instruction level Parallelism
Loop level Parallelism
• for (i=1; i<=1000; i= i+1)
x[i] = x[i] + y[i];
Thread level Parallelism
• multi-core computers](https://image.slidesharecdn.com/f2ccb870-9ddf-4739-aef7-8e12d9256a14-150413000941-conversion-gate01/85/INSTRUCTION-LEVEL-PARALLALISM-3-320.jpg)










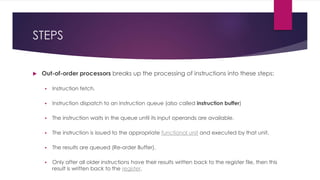



This document discusses instruction-level parallelism (ILP), which refers to executing multiple instructions simultaneously in a program. It describes different types of parallel instructions that do not depend on each other, such as at the bit, instruction, loop, and thread levels. The document provides an example to illustrate ILP and explains that compilers and processors aim to maximize ILP. It outlines several ILP techniques used in microarchitecture, including instruction pipelining, superscalar, out-of-order execution, register renaming, speculative execution, and branch prediction. Pipelining and superscalar processing are explained in more detail.





















































