Download to read offline









model = KMeans.train(points, 10)
sc.twitterStream(...)
.map(lambda t: (model.closestCenter(t.location), 1))
.reduceByKeyAndWindow(lambda x,y: x+y , Seconds(20), Seconds(3))
Source: The State of Spark, and Where We’re Going Next, presentation by M. Zaharia, 2013](https://image.slidesharecdn.com/20151013dswassimpleasapachespark3-151015015354-lva1-app6892/85/As-simple-as-Apache-Spark-10-320.jpg)


![All rights reserved, © 2015 ICM UW
Third: Code much and often
14
import pyspark.ml.recommendation.ALS
import pyspark.ml.recommendation.Rating
// Transform Strings: "user_id,movie_id,rating" to Ratings: Rating(user_id:Int,movie_id:Int,rating:Double)
data = sc.textFile("path/to/data.csv")
ratings = data.map(lambda s: s.split(',')).map(lambda arr: Rating(int(arr[0]), int(arr[1]), float(arr[2]))
// Build the recommendation model using ALS
// Factor the rating matrix A=[n,m] into B=[n,f] and C=[f,m], where A ~= B x C
numFeatures = 10; numIterations = 20
model = ALS.train(ratings, numFeatures, numIterations, 0.01)](https://image.slidesharecdn.com/20151013dswassimpleasapachespark3-151015015354-lva1-app6892/85/As-simple-as-Apache-Spark-14-320.jpg)
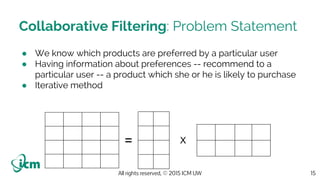




The document discusses Apache Spark and its ecosystem. It begins with introducing the speaker who has 5 years of experience in knowledge discovery and has used big data technologies like Hadoop and Spark. It then explains that Spark provides a versatile ecosystem for batch, streaming, SQL, machine learning and graph processing workloads through components like Spark Core, Spark SQL, Spark Streaming, MLLib and GraphX. The document demonstrates Spark's seamless integration through an example that performs SQL queries, trains a machine learning model and performs streaming analysis in one workflow. It encourages attendees to start using Spark by downloading it and experimenting through hands-on coding examples.



























![Introduction to Data Analtics with Pandas [PyCon Cz]](https://cdn.slidesharecdn.com/ss_thumbnails/introductiontodataanalticswithpandaspyconcz-170617163446-thumbnail.jpg?width=640&height=640&fit=bounds)



























































