Download to read offline














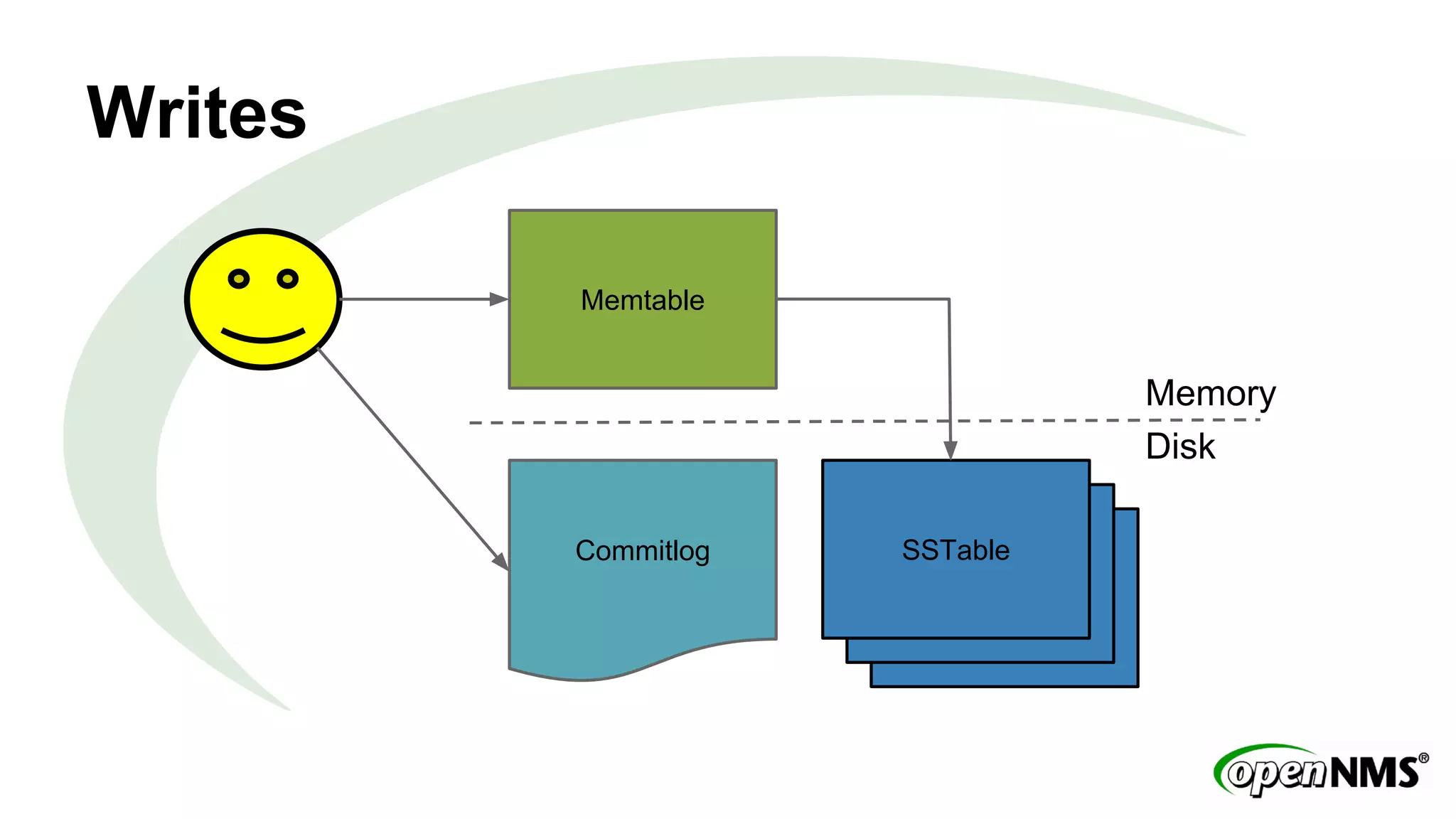

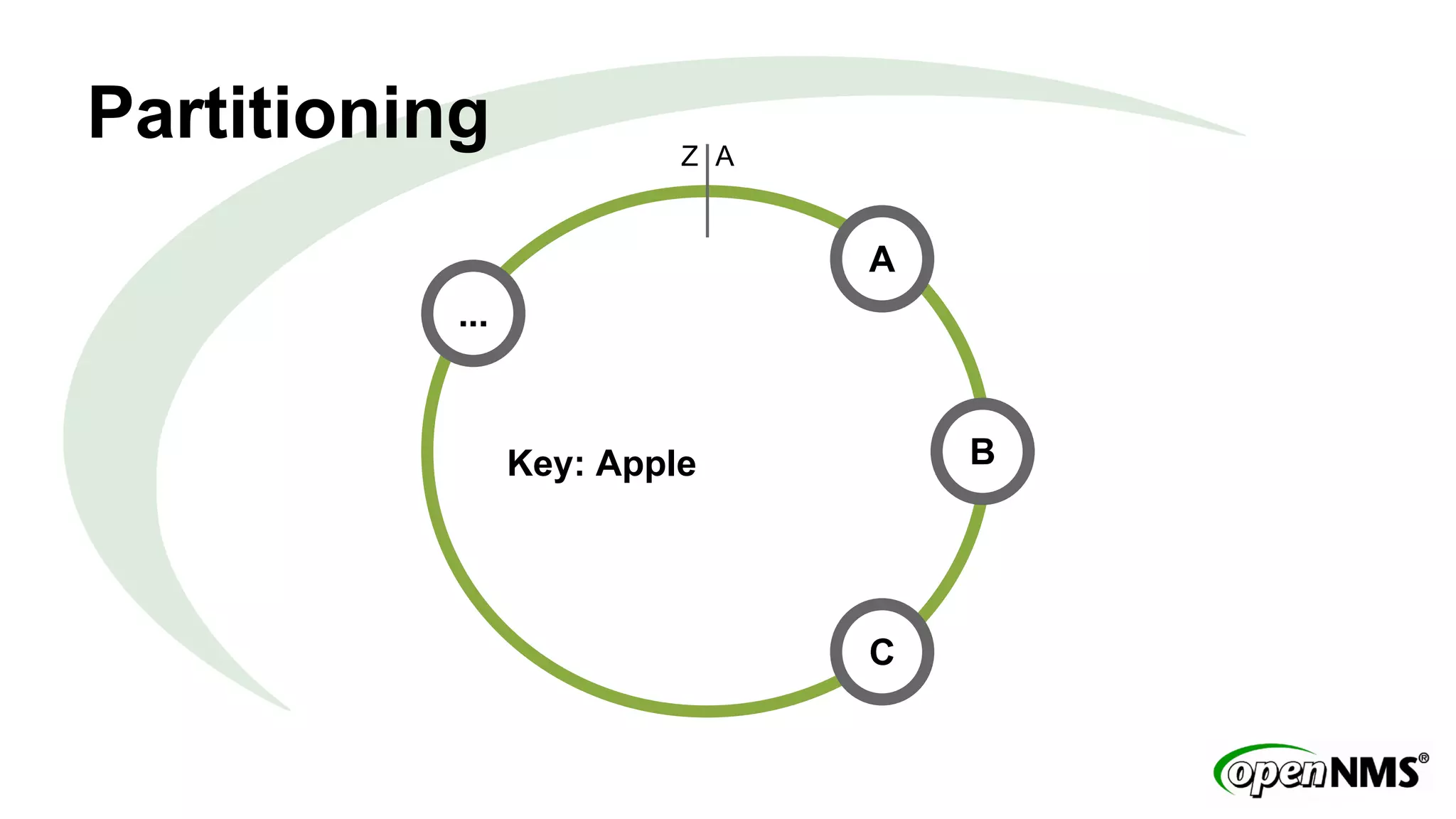
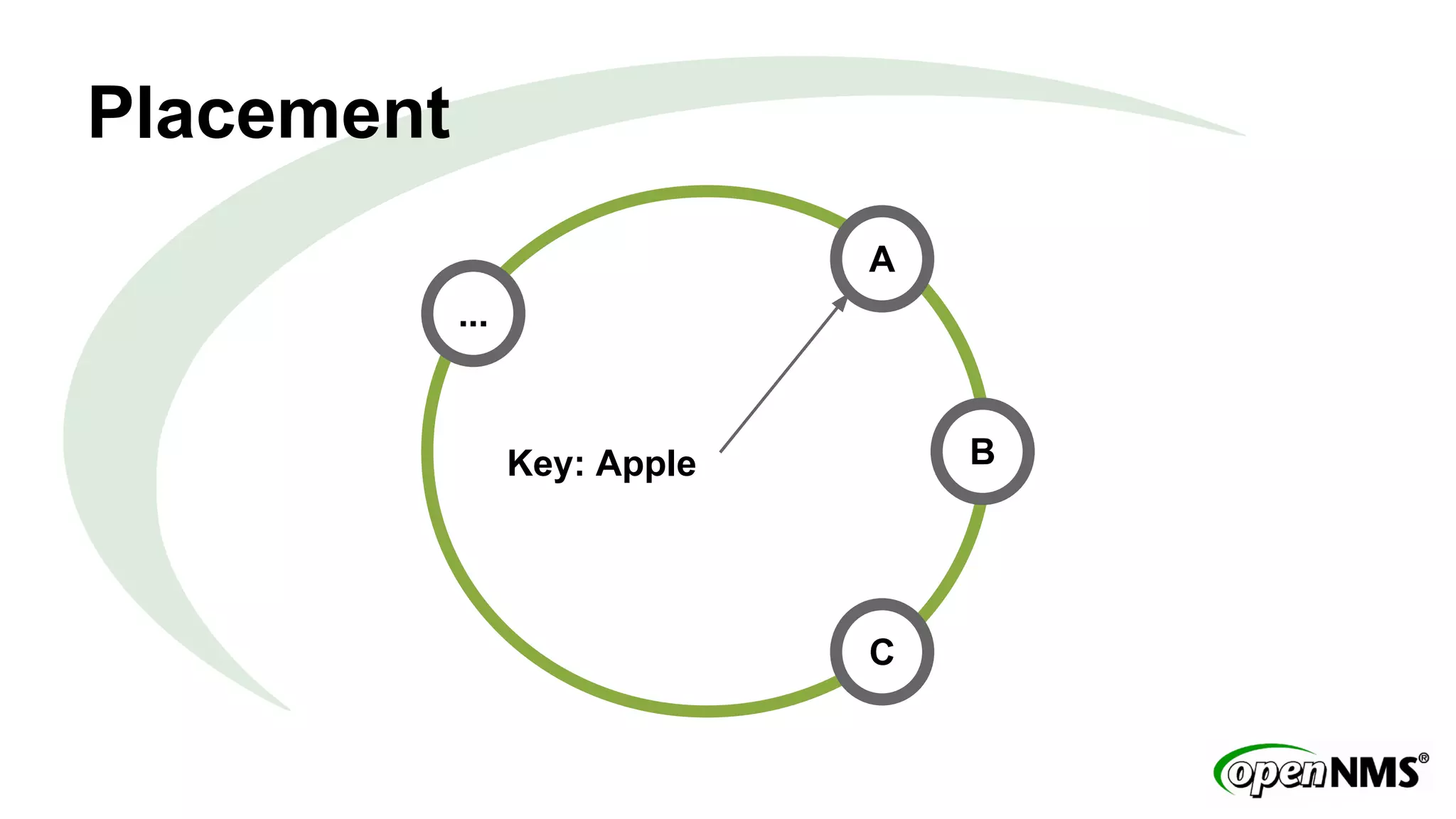
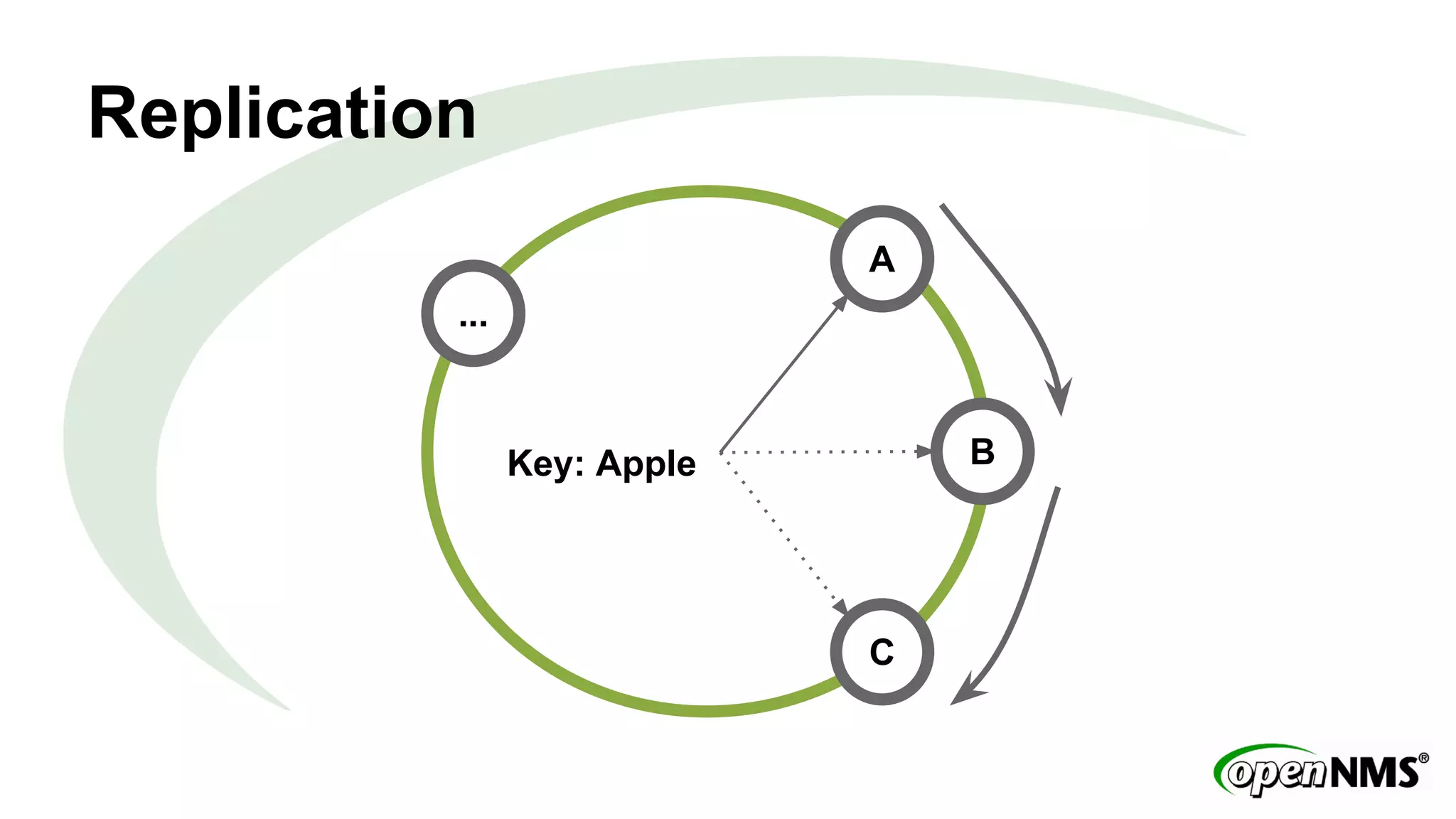

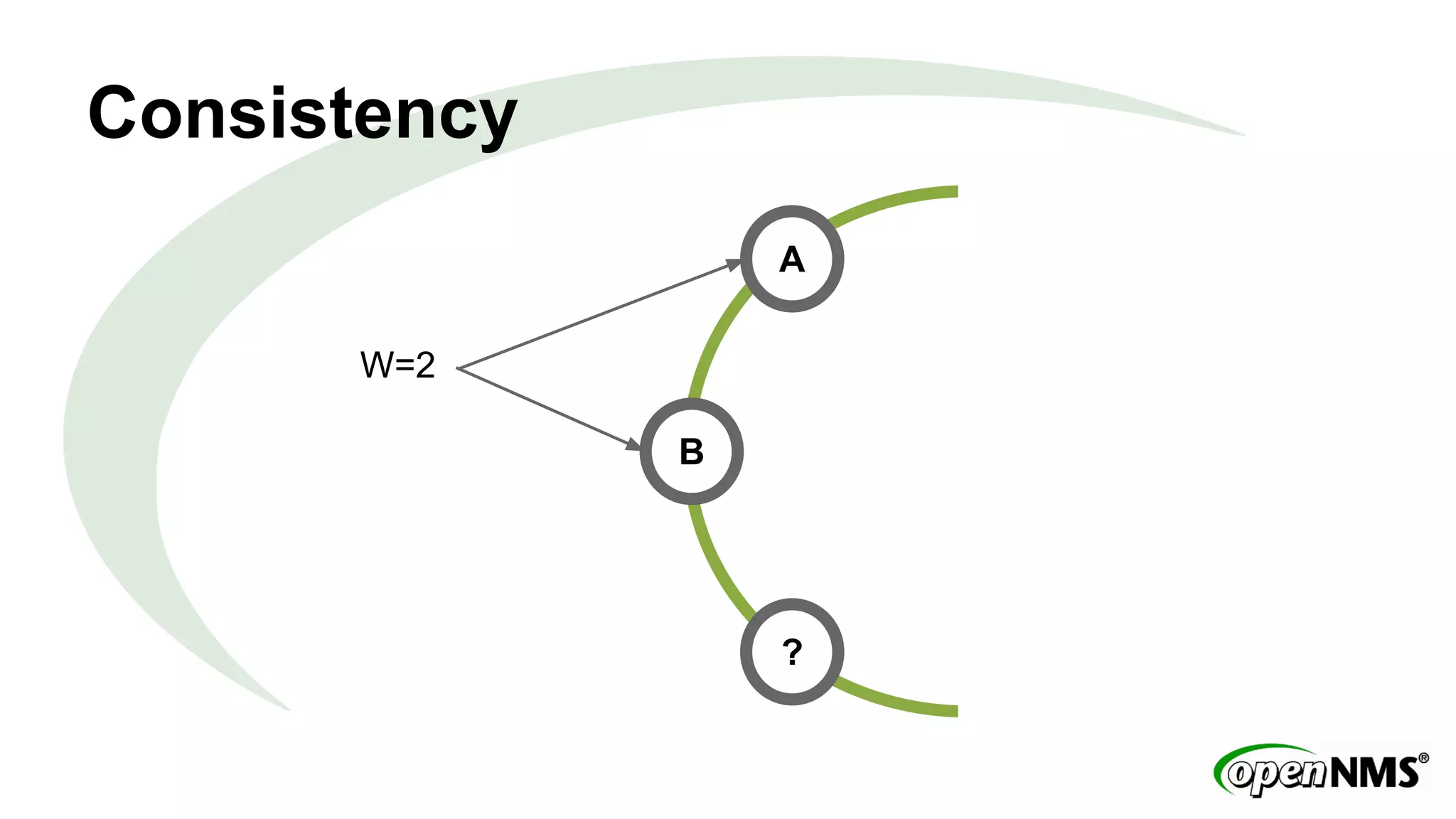
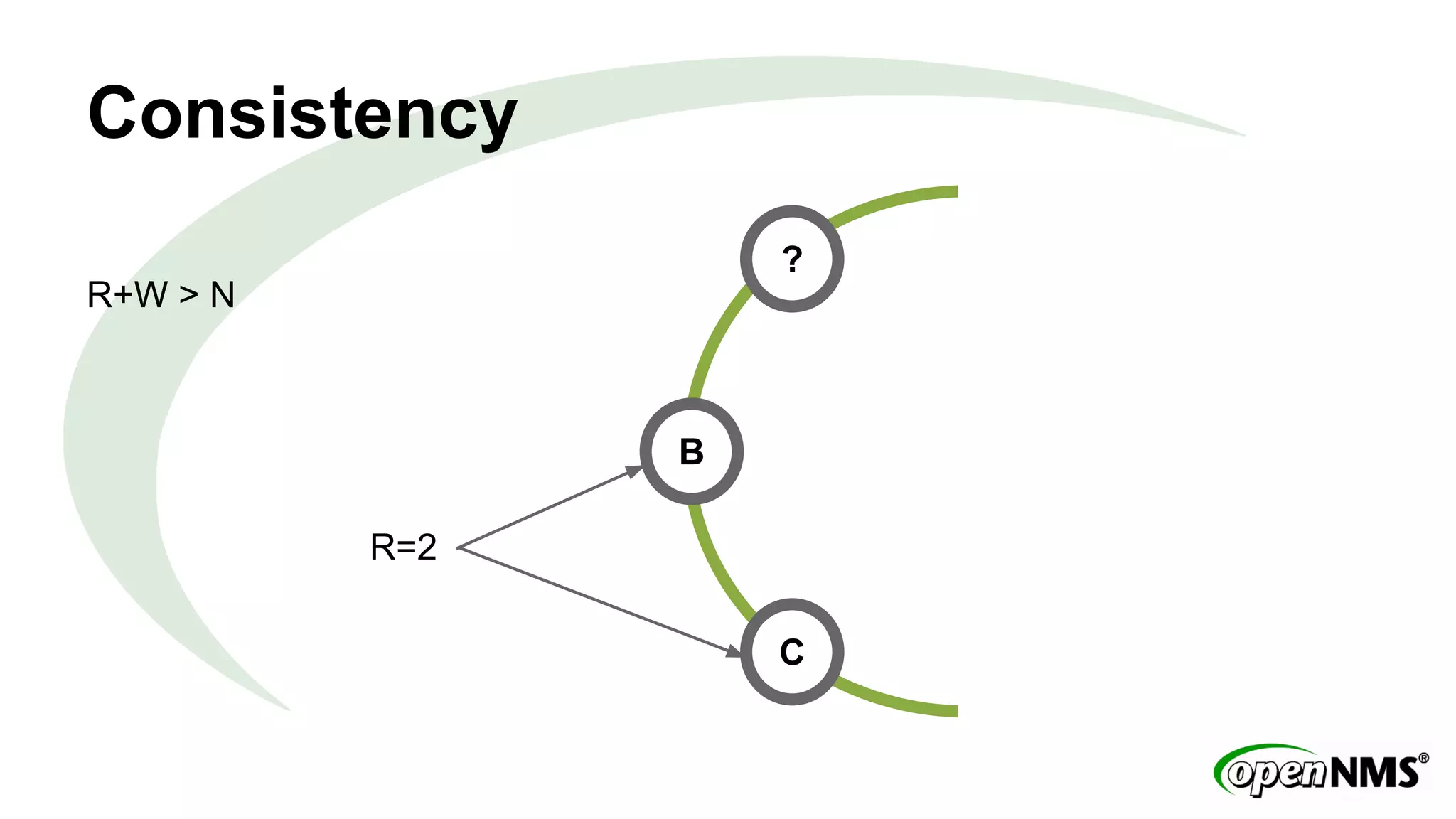


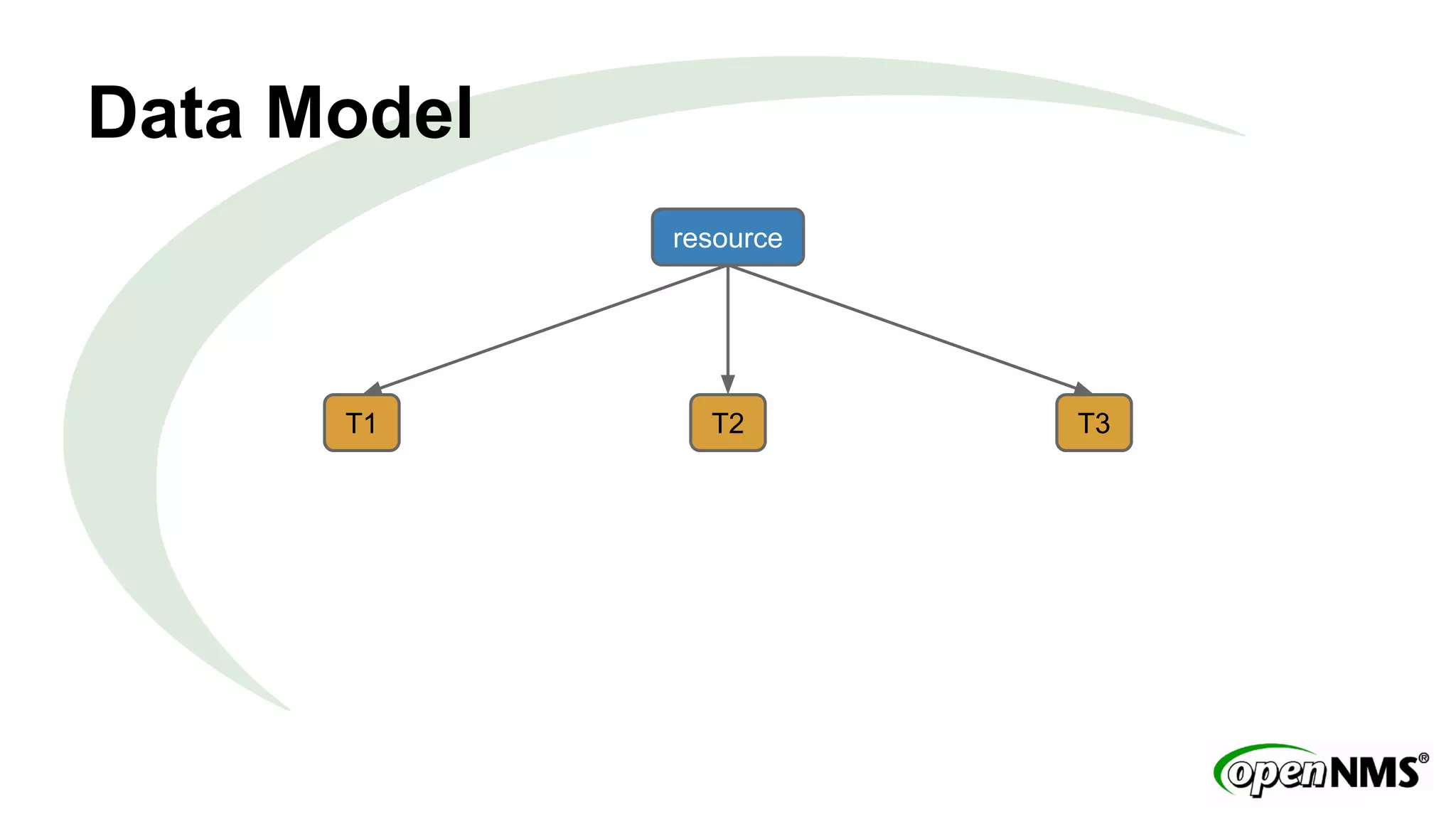
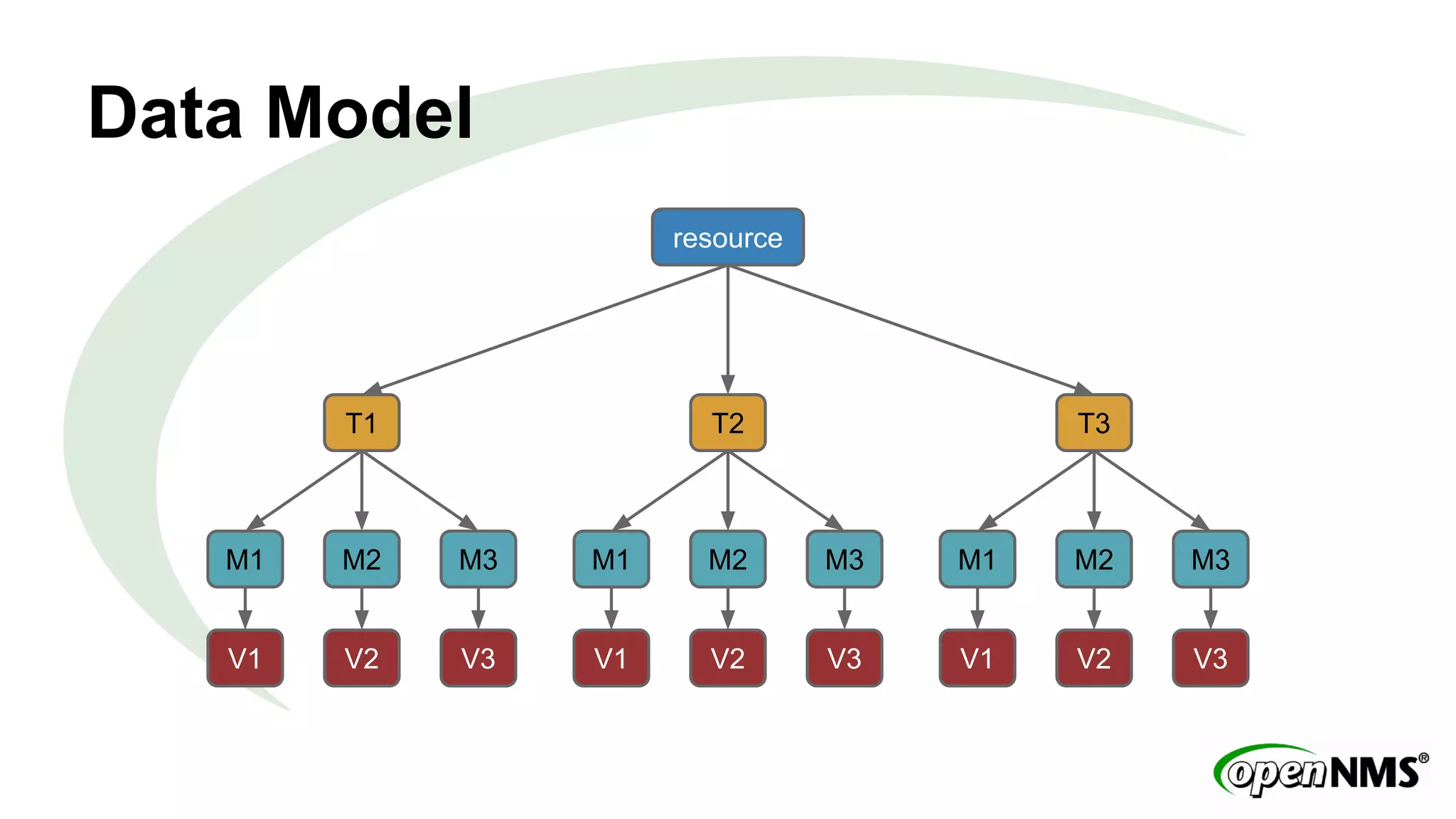

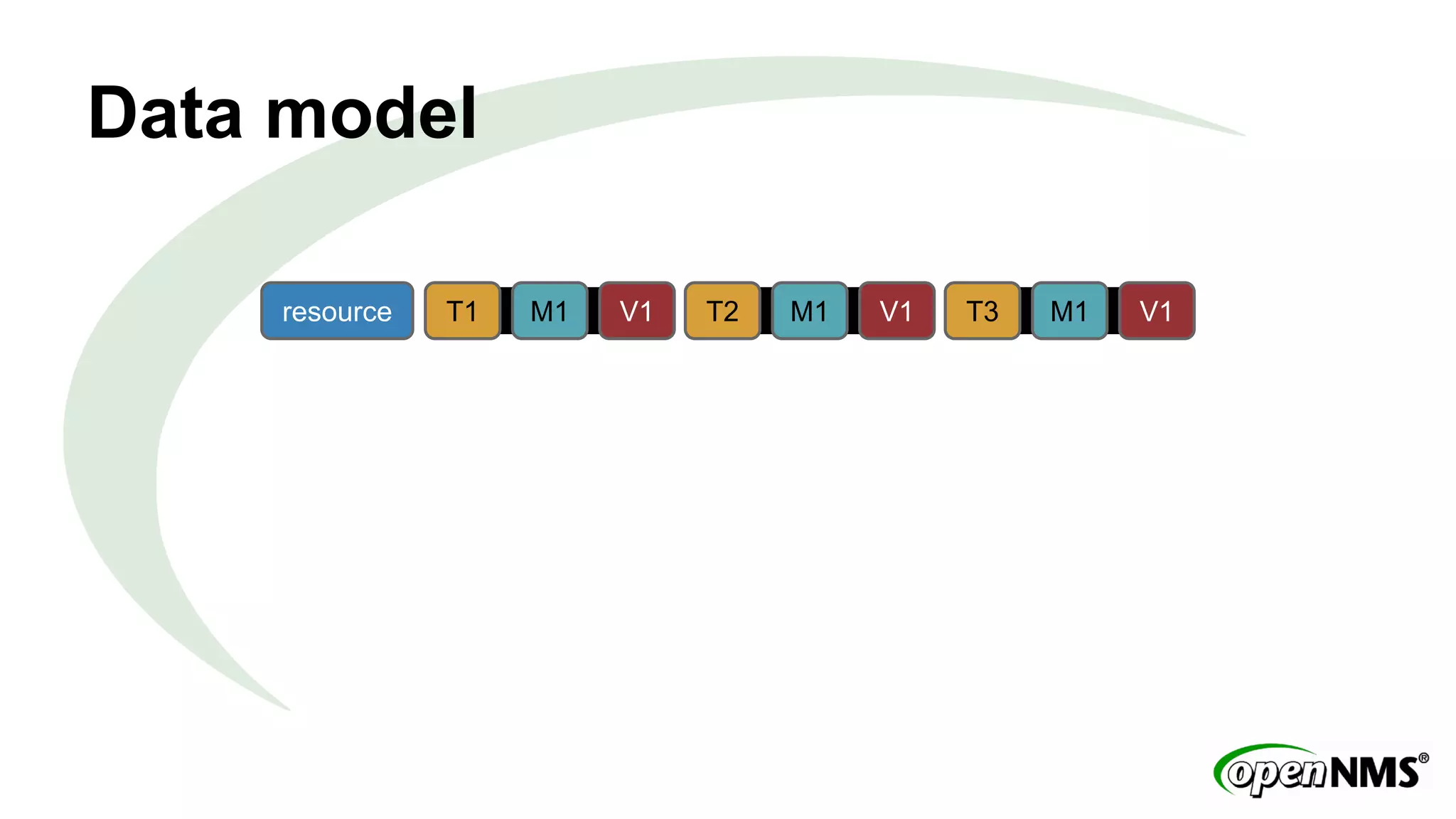
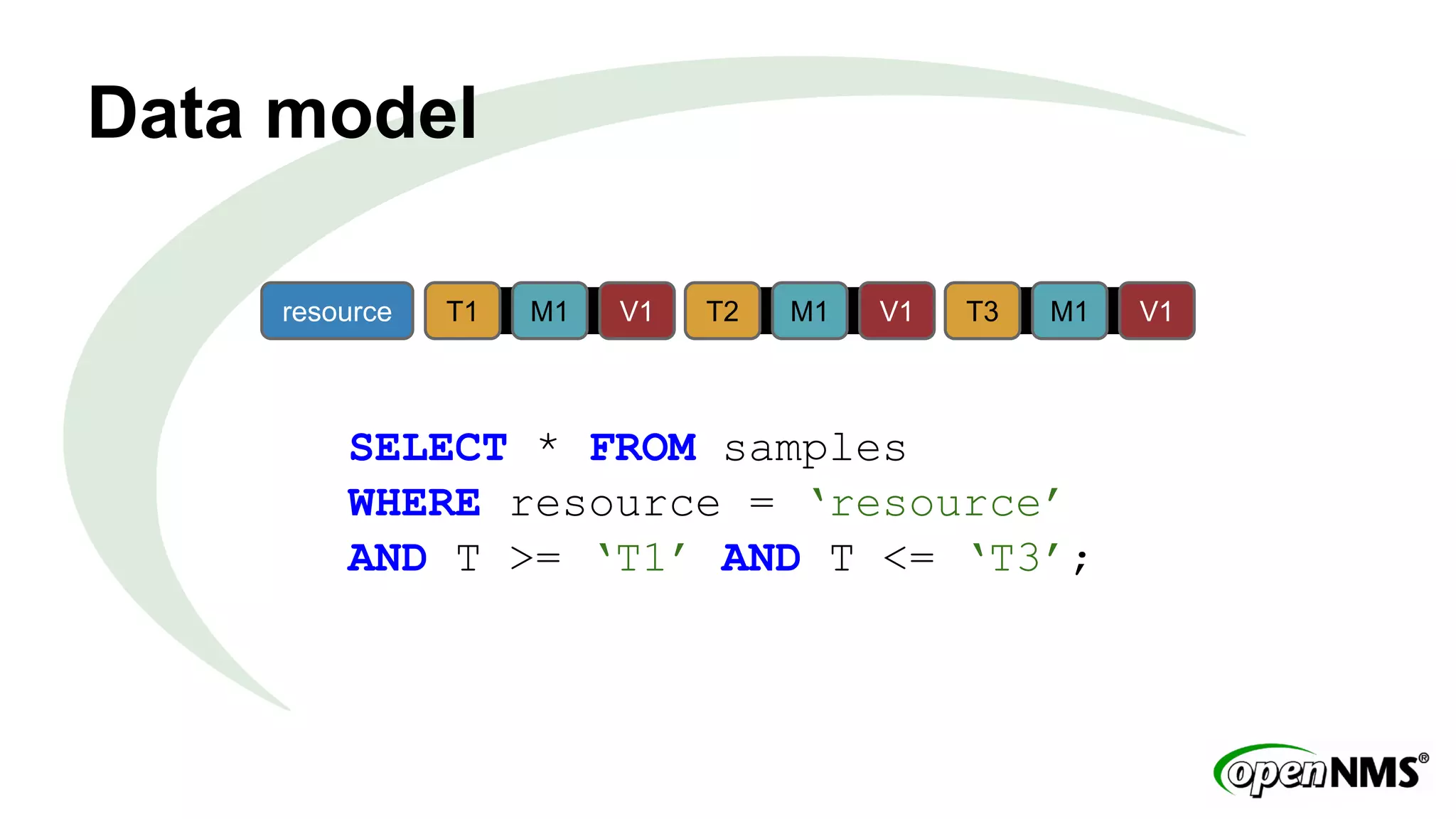
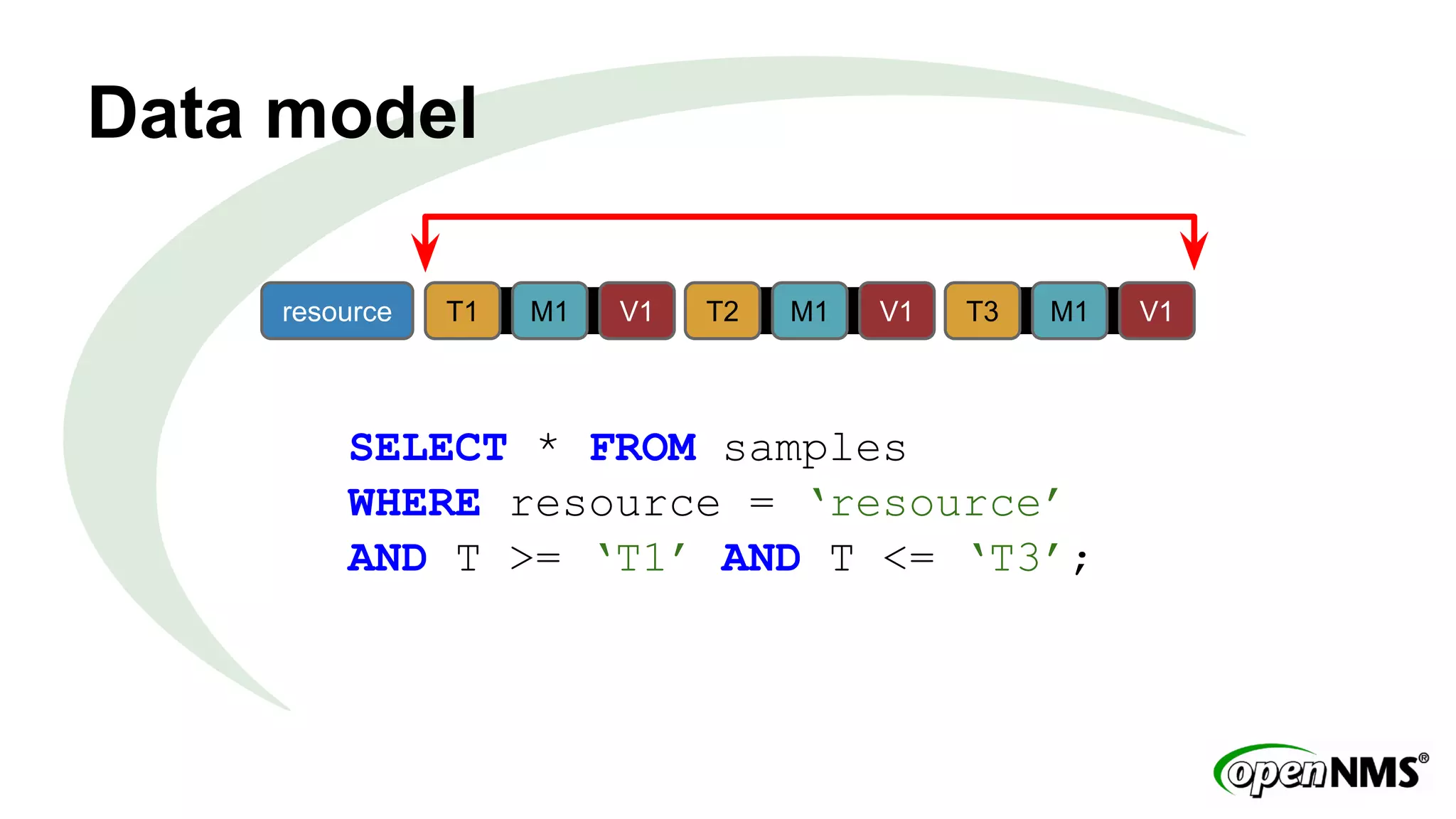
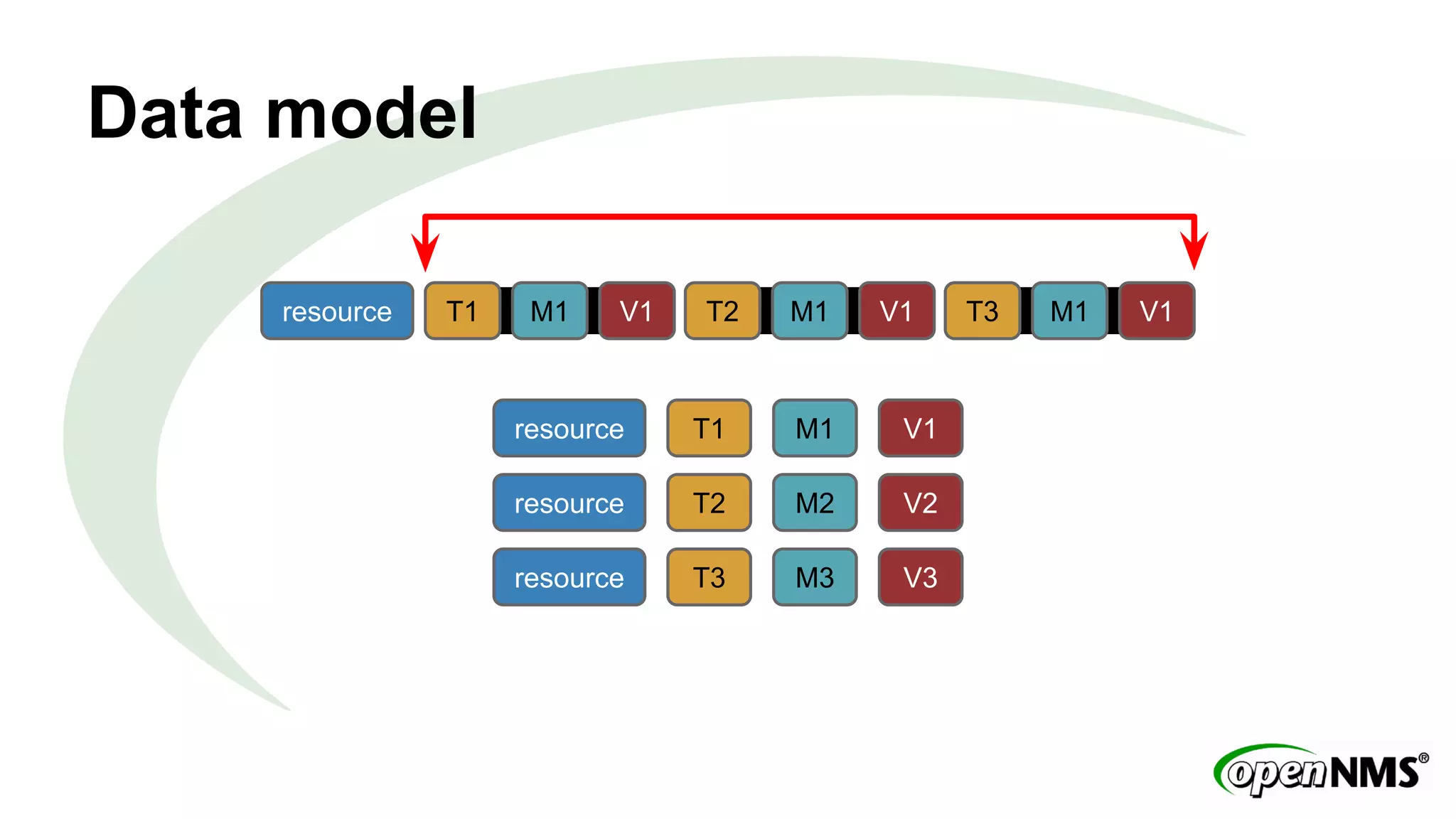




This document discusses using Apache Cassandra to store and manage time series data in OpenNMS. It describes some limitations of the existing RRDTool-based data storage, such as high I/O requirements for updating and aggregating data. Cassandra is presented as an alternative that is optimized for write throughput, flexible data modeling, high availability, and ability to perform aggregations at read time rather than write time. The Newts project is introduced as a standalone time series data store built on Cassandra that aims to provide fast storage and retrieval of raw samples along with flexible aggregation capabilities.





![TypoScript and EEL outside of Neos [InspiringFlow2013]](https://cdn.slidesharecdn.com/ss_thumbnails/typoscriptandeel-130420043915-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)











































































![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)






![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)







