Downloaded 170 times






























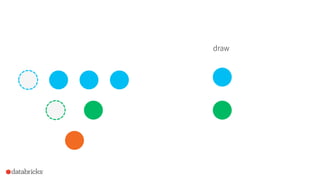

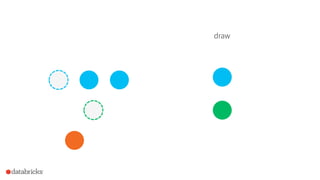
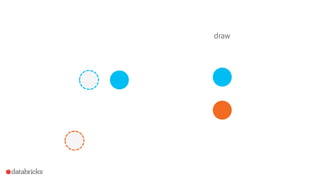

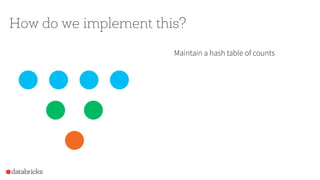


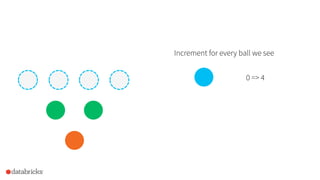
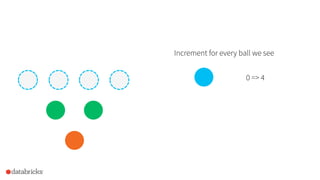
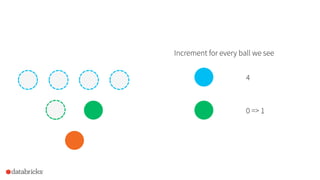
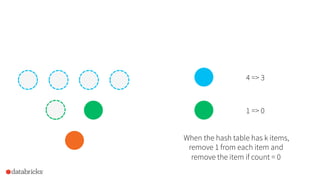
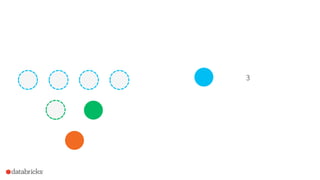
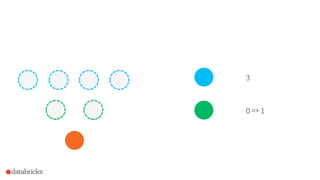
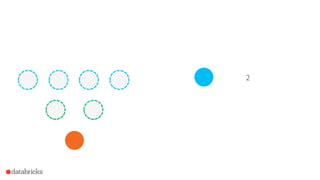
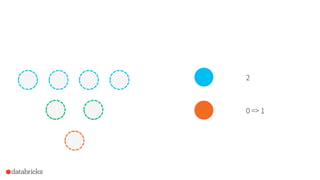




![How to use it in Spark?
Frequent items for multiple columns independently
• df.stat.freqItems([“columnA”,
“columnB”,
…])
Frequent items for composite keys
• df.stat.freqItems(struct(“columnA”,
“columnB”))](https://image.slidesharecdn.com/2015-09-29sketchstrata-151002043830-lva1-app6892/85/Strata-NYC-2015-Sketching-Big-Data-with-Spark-randomized-algorithms-for-large-scale-data-analytics-56-320.jpg)










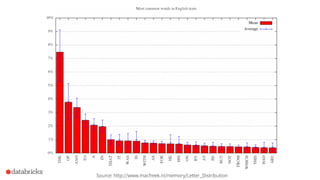
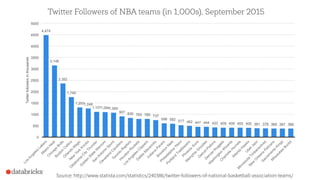
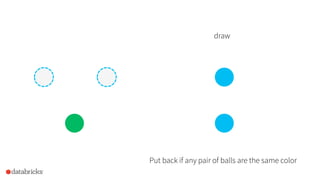
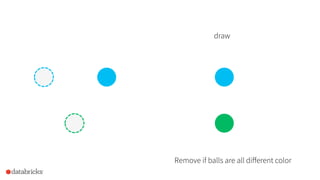
1) Reynold Xin presented on using sketches like Bloom filters, HyperLogLog, count-min sketches, and stratified sampling to summarize and analyze large datasets in Spark. 2) Sketches allow analyzing data in small space and in one pass to identify frequent items, estimate cardinality, and sample data. 3) Spark incorporates sketches to speed up exploration, feature engineering, and building faster exact algorithms for processing large datasets.











































































































