Downloaded 11 times


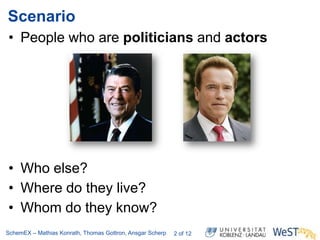
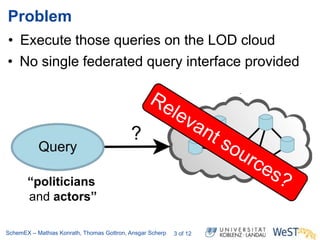
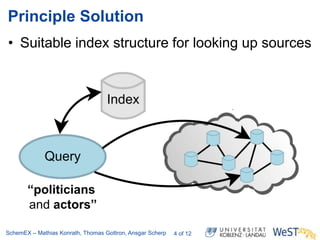


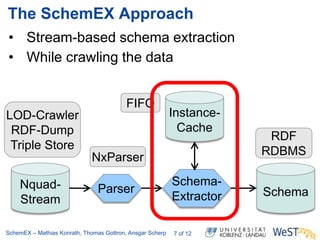
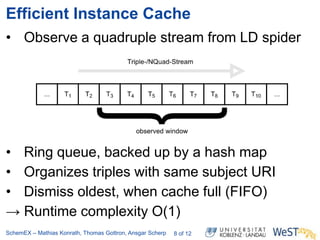
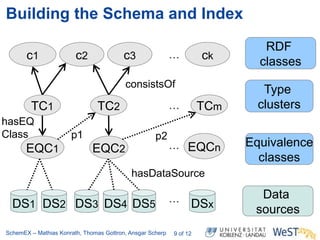





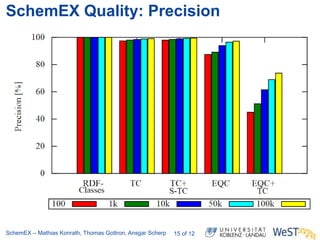
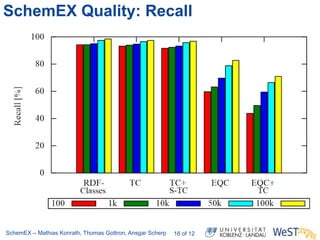
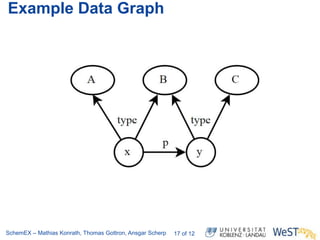
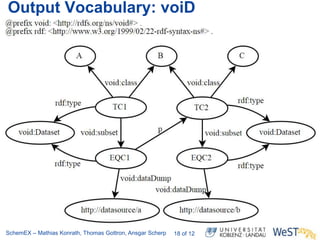
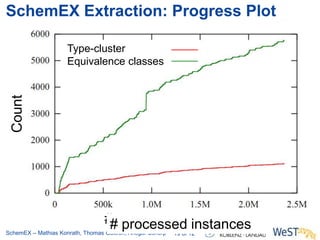

The document discusses the ScheMex project, which aims to create a structured index for querying the Linked Open Data (LOD) cloud, particularly focusing on politicians and actors. It proposes a stream-based schema extraction approach, enabling efficient lookup and federated queries while managing memory use through a FIFO caching system. The results indicate that this method is scalable, effective with large datasets, and operates well on standard hardware.



























































































