Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Data Science Warsaw
642 views
Data Science Warsaw
Data Science Warsaw - wyniki czerwcowej ankiety
Data & Analytics
◦
Related topics:
Data Science Insights
•
Read more
1
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 12
2
/ 12
3
/ 12
4
/ 12
5
/ 12
6
/ 12
7
/ 12
8
/ 12
9
/ 12
10
/ 12
11
/ 12
12
/ 12
More Related Content
PDF
Online content popularity prediction
by
Data Science Warsaw
PDF
Big Data, Wearable, sztuczna inteligencja i ekonomia współpracy
by
Data Science Warsaw
PDF
Małe dane, duży wpływ - Dominik Batorski ICM
by
Data Science Warsaw
PDF
How to build your own google
by
Data Science Warsaw
PDF
Data science warsaw inaugural meetup
by
Data Science Warsaw
PDF
Oracle Big Data Discovery - ludzka twarz Hadoop'a
by
Data Science Warsaw
PDF
Data Exchange - the missing link in the big data value chain
by
Data Science Warsaw
PDF
Ask Data Anything
by
Data Science Warsaw
Online content popularity prediction
by
Data Science Warsaw
Big Data, Wearable, sztuczna inteligencja i ekonomia współpracy
by
Data Science Warsaw
Małe dane, duży wpływ - Dominik Batorski ICM
by
Data Science Warsaw
How to build your own google
by
Data Science Warsaw
Data science warsaw inaugural meetup
by
Data Science Warsaw
Oracle Big Data Discovery - ludzka twarz Hadoop'a
by
Data Science Warsaw
Data Exchange - the missing link in the big data value chain
by
Data Science Warsaw
Ask Data Anything
by
Data Science Warsaw
Viewers also liked
PDF
Geolokalizacja i analizy przestrzenne: trzy wymiary a ile pracy dla analityka!
by
Data Science Warsaw
PDF
Wizualne budowanie aplikacji na Sparku przy pomocy narzędzia Seahorse
by
Data Science Warsaw
DOCX
Exercícios gramaticais
by
Brígida Ferreira
DOCX
Texto funcional o convite
by
Brígida Ferreira
DOCX
Ficha medidas capac
by
Brígida Ferreira
PDF
Biogas_Permeation_EN
by
Pedro Serra
PPTX
презентация2
by
dmitriymmz
DOCX
Exerc frações
by
Brígida Ferreira
PPTX
шаг к успеху
by
dmitriymmz
PPTX
творческая группа
by
dmitriymmz
PPTX
семинар
by
dmitriymmz
PDF
Cyber Security Investigations
by
Steve Collins
DOCX
SOCIEDAD DE LA INFORMACION Y EDUCACION
by
Breidys Barranco
PDF
Analiza języka naturalnego
by
Data Science Warsaw
PDF
Neptune - narzędzie do monitorowania i zarządzania eksperymentami Machine Lea...
by
Data Science Warsaw
PDF
P7 guiafuentelfav
by
Luis Amaya
PDF
चिड़िया और अन्धा सांप (Sparrow and Blind Snake)
by
Ahmed@3604
PDF
Cover Pages Grass
by
Haim R. Branisteanu
DOCX
Casa
by
Brígida Ferreira
Geolokalizacja i analizy przestrzenne: trzy wymiary a ile pracy dla analityka!
by
Data Science Warsaw
Wizualne budowanie aplikacji na Sparku przy pomocy narzędzia Seahorse
by
Data Science Warsaw
Exercícios gramaticais
by
Brígida Ferreira
Texto funcional o convite
by
Brígida Ferreira
Ficha medidas capac
by
Brígida Ferreira
Biogas_Permeation_EN
by
Pedro Serra
презентация2
by
dmitriymmz
Exerc frações
by
Brígida Ferreira
шаг к успеху
by
dmitriymmz
творческая группа
by
dmitriymmz
семинар
by
dmitriymmz
Cyber Security Investigations
by
Steve Collins
SOCIEDAD DE LA INFORMACION Y EDUCACION
by
Breidys Barranco
Analiza języka naturalnego
by
Data Science Warsaw
Neptune - narzędzie do monitorowania i zarządzania eksperymentami Machine Lea...
by
Data Science Warsaw
P7 guiafuentelfav
by
Luis Amaya
चिड़िया और अन्धा सांप (Sparrow and Blind Snake)
by
Ahmed@3604
Cover Pages Grass
by
Haim R. Branisteanu
Casa
by
Brígida Ferreira
More from Data Science Warsaw
PDF
CRISP-DM Agile Approach to Data Mining Projects
by
Data Science Warsaw
PDF
Rozwiązywanie problemów optymalizacyjnych
by
Data Science Warsaw
PDF
Ile informacji jest w danych?
by
Data Science Warsaw
PDF
Azure - Duże zbiory w chmurze
by
Data Science Warsaw
PDF
To się w ram ie nie zmieści
by
Data Science Warsaw
PDF
As simple as Apache Spark
by
Data Science Warsaw
PDF
Haven 2 0
by
Data Science Warsaw
PDF
Data science w ubezpieczeniach
by
Data Science Warsaw
PDF
Otwarte Miasta
by
Data Science Warsaw
PDF
Metody logiczne w analizie danych
by
Data Science Warsaw
CRISP-DM Agile Approach to Data Mining Projects
by
Data Science Warsaw
Rozwiązywanie problemów optymalizacyjnych
by
Data Science Warsaw
Ile informacji jest w danych?
by
Data Science Warsaw
Azure - Duże zbiory w chmurze
by
Data Science Warsaw
To się w ram ie nie zmieści
by
Data Science Warsaw
As simple as Apache Spark
by
Data Science Warsaw
Haven 2 0
by
Data Science Warsaw
Data science w ubezpieczeniach
by
Data Science Warsaw
Otwarte Miasta
by
Data Science Warsaw
Metody logiczne w analizie danych
by
Data Science Warsaw
Data Science Warsaw
1.
Wyniki czerwcowej ankiety Dominik
Batorski
2.
826 group members +250
od poprzedniego spotkania Ankieta – w czerwcu zapytaliśmy: • Kim jesteśmy • Na czym się znamy • Jakich spotkań chcemy Odpowiedziało dokładnie 100 osób.
3.
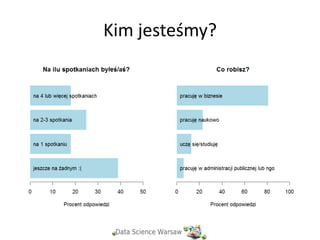
Kim jesteśmy?
4.
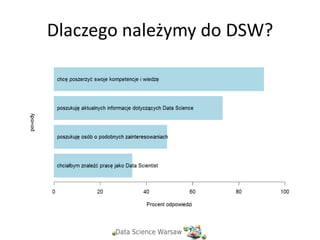
Dlaczego należymy do
DSW?
5.
Na czym się
znamy?
6.
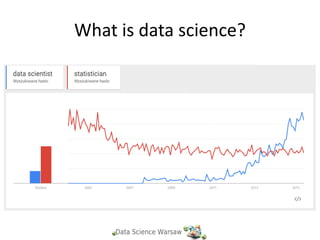
What is data
science?
7.
Data Science –
3 rodzaje kompetencji
8.
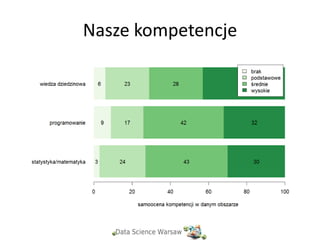
Nasze kompetencje
9.
Warsa Data Scientists średnie
+ wysokie wysokie
10.
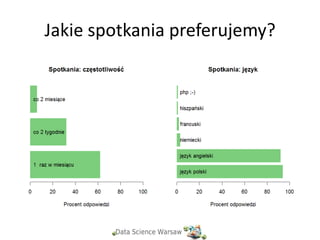
Jakie spotkania preferujemy?
11.
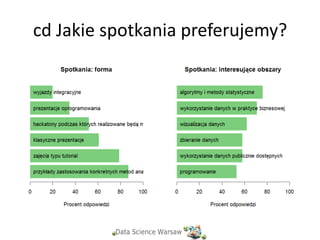
cd Jakie spotkania
preferujemy?
12.
Thank you! @DominikBatorski
Download