Download as PDF, PPTX











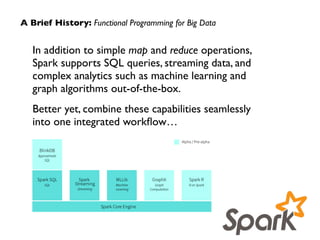






![Unifying the Pieces: GraphX
// http://spark.apache.org/docs/latest/graphx-programming-guide.html!
!
import org.apache.spark.graphx._!
import org.apache.spark.rdd.RDD!
!
case class Peep(name: String, age: Int)!
!
val vertexArray = Array(!
(1L, Peep("Kim", 23)), (2L, Peep("Pat", 31)),!
(3L, Peep("Chris", 52)), (4L, Peep("Kelly", 39)),!
(5L, Peep("Leslie", 45))!
)!
val edgeArray = Array(!
Edge(2L, 1L, 7), Edge(2L, 4L, 2),!
Edge(3L, 2L, 4), Edge(3L, 5L, 3),!
Edge(4L, 1L, 1), Edge(5L, 3L, 9)!
)!
!
val vertexRDD: RDD[(Long, Peep)] = sc.parallelize(vertexArray)!
val edgeRDD: RDD[Edge[Int]] = sc.parallelize(edgeArray)!
val g: Graph[Peep, Int] = Graph(vertexRDD, edgeRDD)!
!
val results = g.triplets.filter(t => t.attr > 7)!
!
for (triplet <- results.collect) {!
println(s"${triplet.srcAttr.name} loves ${triplet.dstAttr.name}")!
}](https://image.slidesharecdn.com/keynote-paco-databrix-141110005808-conversion-gate01/85/Big-Data-Everywhere-Chicago-Apache-Spark-Plus-Many-Other-Frameworks-How-Spark-Fits-Into-the-Big-Data-Landscape-Databricks-25-320.jpg)



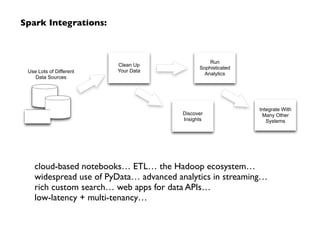



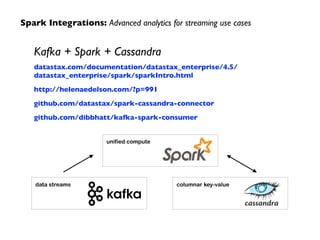










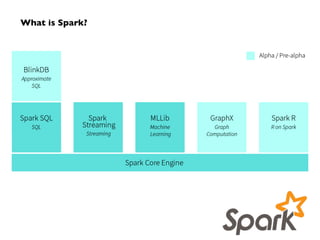
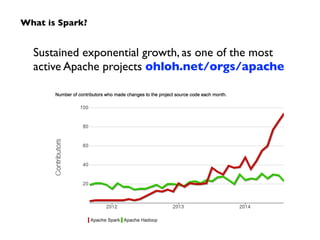
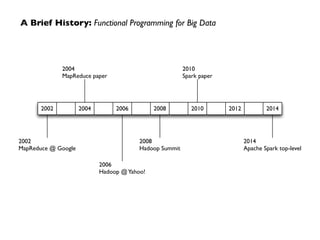
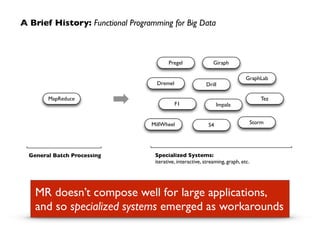
Apache Spark, developed at UC Berkeley in 2009 and open-sourced in 2010, has emerged as a leading open-source community for big data, providing in-memory computing and supporting a wide range of analytics tasks on Hadoop clusters. It integrates seamlessly with various frameworks to enable advanced analytics, machine learning, and real-time streaming, while helping organizations manage their big data workflows effectively. The document discusses Spark's architecture, features, integrations, and its role in the evolving big data landscape.










































![Fun[ctional] spark with scala](https://cdn.slidesharecdn.com/ss_thumbnails/functionalsparkwithscala-160614075814-thumbnail.jpg?width=640&height=640&fit=bounds)


































![[DSC Europe 25] Marcos Heidemann - Beyond the Hype: Making AI Coding Assistan...](https://cdn.slidesharecdn.com/ss_thumbnails/eexkhvldrjsopspdjbur-marcos-heidemann-beyond-the-hype-getting-real-value-out-of-ai-assisted-coding-260121115910-7e9d41ec-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Tali Fulman - Guild Meetings, Then What? Building Data Commun...](https://cdn.slidesharecdn.com/ss_thumbnails/fgohhi33rwmhqdowdj5k-tali-fulman-guild-meetings-then-what-building-data-communities-that-actually-ch-260120105855-528492c3-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jovan Sumarac - Real-World Applications of Computer Vision in...](https://cdn.slidesharecdn.com/ss_thumbnails/fiksms22smcpopvvld03-jovan-sumarac-real-life-applications-of-computer-vision-in-automotive-systems-260120105855-de622abb-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Laila Kakar - Leveraging AI for Strategic Excellence: Enhanci...](https://cdn.slidesharecdn.com/ss_thumbnails/eykmhrtsqmaaftwkexh7-dsc-lailakakar-1-260119101520-5f3b5616-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milovan Jovicic - Beyond AI's Reach: The Enduring Value of Ev...](https://cdn.slidesharecdn.com/ss_thumbnails/pyeij0hurgwq5jugmtnv-2-milovan-jovicic-beyond-ais-reach-the-enduring-value-of-evergreen-design-v2-260120105856-d6ee57e5-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Bojan Djuricic - Predictive Design Process.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/5awdrbedqdek3gqu2ezy-4-the-predictive-design-bojan-djuricic-260120105856-6c399e9b-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Bojan Banjac - AI is always right when it comes to the matter...](https://cdn.slidesharecdn.com/ss_thumbnails/syoxtqierpydwxm5srcb-4-bojan-banjac-ai-is-always-right-when-it-comes-to-the-matters-of-taste-260119101519-694ee7d7-thumbnail.jpg?width=640&height=640&fit=bounds)


