Equip yourself with the knowledge, strategies, and practical skills needed to confidently pass the UiPath Agentic Automation Associate (UiAAA) certification exam. This session focuses on high-impact topics, hands-on demos, and proven exam tips to maximize success before the voucher deadline.
👨💻 Who should attend:
UiPath Community members preparing for the UiAAA exam—especially those seeking practical guidance, last-minute tips, and answers to common questions.
📕 Agenda:
Get exam-ready with this practical, exam-focused UiPath Agentic Automation Associate (UiAAA) community prep session. Designed for anyone aiming to complete their UiAAA certification before the voucher deadline, this session will cover high-yield topics, practical demos, and proven strategies to boost your confidence and help you pass the exam.
1. Welcome & Session Overview
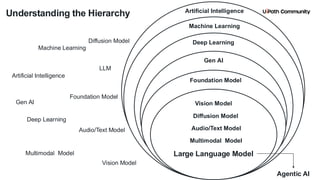
2. Core Concepts
3. LLM Fundamentals
4. Agentic Prompt Engineering
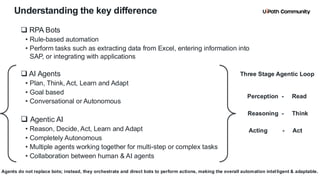
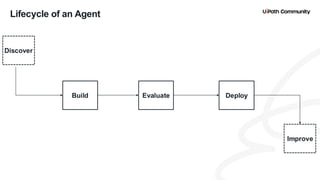
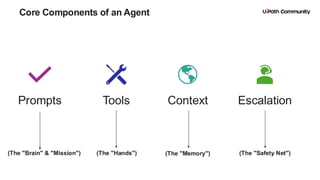
5. Agent Architecture & Core Components
6. Context Grounding & Indexes (RAG)
7. Evaluations & Agent Health
8. UiPath Maestro & BPMN Essentials
9. Training Modules & Practical Exam Prep Tips
10. Resources & Next Steps
•Cheat sheets, quick reference docs, and study plan
•Where to find session recording, notes, and community support
11. Q&A
👨💻 Speakers:
Imran Loon, AI Solution Architect @Tech Mahindra
Amit Kumar, RPA Solution Architect @Tech Mahindra
Goulsalya S., RPA Developer @Tech Machindra
This session streamed live on Jan 21, 2026, 11:30 GMT.
👉 Join our London UiPath Community Chapter: https://community.uipath.com/london/
👉 Follow all our upcoming sessions at: https://community.uipath.com/events/













![17
Zero-shot (no examples provided to the model)
System message:
You are a precise enterprise email triage assistant.
Return only a single label from: ["Billing", "Technical",
"Sales"].
If uncertain, return "Technical".
User message (dynamic from email body):
Email:
{{email_body}}
Task: Classify the email into one label from the list
above.
Output JSON: {"label":"<one_of_the_labels>"}
Scenario: Route incoming emails to the right queue (Billing, Technical Support, Sales) without examples.
Activity: Create Text with Azure OpenAI](https://image.slidesharecdn.com/londonmeetup-260122091047-8c17355b/85/Skills-to-Pass-the-UiPath-Agentic-Automation-Associate-UiAAA-Certification-17-320.jpg)

![19
“Chain-of-Thought” (safe style)
System message:
You diagnose RPA job failures.
Provide:
1) a short, numbered summary of key factors (max 4 bullets),
2) a final root-cause hypothesis (1–2 lines),
3) 2–3 actionable next steps.
Avoid exposing internal deliberations; keep outputs concise
and user-ready.
User message:
User message:
Logs:
{{log_excerpt}}
Context:
Process = Order Creation; ERP = SAP ECC; Bot runs on Win
2019
Deliverable format:
- Key factors: [1..4 bullets]
- Root-cause hypothesis: <1–2 lines>
- Next steps: [2..3 bullets]"
}
Scenario: Extract structured fields from short vendor emails
Activity: Extract Information with Azure OpenAI (or Create Text with a clear schema)](https://image.slidesharecdn.com/londonmeetup-260122091047-8c17355b/85/Skills-to-Pass-the-UiPath-Agentic-Automation-Associate-UiAAA-Certification-19-320.jpg)
![20
Zero-shot CoT (without revealing internals)
System message:
You prioritize support tickets.
Return a priority and 2 brief justifications (one line each).
Do not include hidden reasoning traces.
User message:
Ticket:
{{ticket_text}}
Output JSON schema:
{"priority":"High|Medium|Low","justifications":["...","..."]}
Scenario: Prioritize tickets by urgency.](https://image.slidesharecdn.com/londonmeetup-260122091047-8c17355b/85/Skills-to-Pass-the-UiPath-Agentic-Automation-Associate-UiAAA-Certification-20-320.jpg)
![21
Prompt Chaining (multi-step orchestration)
[Input Email]
|
v
[Prompt 1: Classify Email]
|
v
(Switch by Label)
|
Billing Path -------------------------
|
v
[Prompt 2: Extract Invoice Data]
|
v
[Prompt 3: Draft Reply]
|
v
[Prompt 4: Verify / Score Reply]
|
v
[Prompt 5: Correct Reply (if needed)]
|
v
[Send Email]](https://image.slidesharecdn.com/londonmeetup-260122091047-8c17355b/85/Skills-to-Pass-the-UiPath-Agentic-Automation-Associate-UiAAA-Certification-21-320.jpg)

















![Architecting Intelligence — Building the Right Team for Agentic Automation [4/6]](https://cdn.slidesharecdn.com/ss_thumbnails/session-4teamfinalupdated11-250912081700-845d7353-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Mahmoud Fahmy - Transforming Enterprise AI with Scalable LLM ...](https://cdn.slidesharecdn.com/ss_thumbnails/rxsvz5tfstg5fquy016q-3-251218084257-1d2ce5f6-thumbnail.jpg?width=640&height=640&fit=bounds)

















![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)






![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)

























