Download as PDF, PPTX















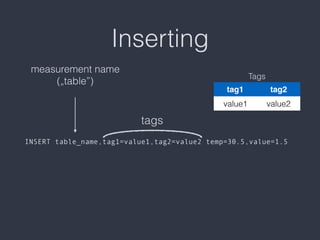






















InfluxDB is an open source time series database designed to handle high write and query speeds for real-time metrics, events, and sensor data. It uses a schemaless data model and stores data as time-stamped points in measurements, which can be queried using a SQL-like language. InfluxDB excels at aggregating and analyzing time series data for use cases like monitoring, analytics, and alerting.













![[4DEV][Łódź] Ivan Vaskevych - InfluxDB and Grafana fighting together with IoT...](https://cdn.slidesharecdn.com/ss_thumbnails/influxdb-171113135140-thumbnail.jpg?width=640&height=640&fit=bounds)















































![Paul Dix [InfluxData] The Journey of InfluxDB | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/2022-11-02influxdays-journeyofinfluxdb-221020214252-ff7c76c5-thumbnail.jpg?width=640&height=640&fit=bounds)
![Anais Dotis-Georgiou & Faith Chikwekwe [InfluxData] | Top 10 Hurdles for Flux...](https://cdn.slidesharecdn.com/ss_thumbnails/anaisdotis-georgioufaithchikwekweinfluxdatatop10hurdlesforfluxbeginnersinfluxdaysvirtualexperiencena-201106155710-thumbnail.jpg?width=640&height=640&fit=bounds)
























