Downloaded 285 times



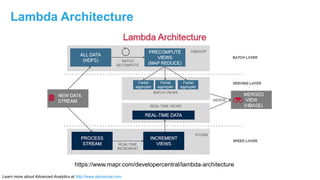

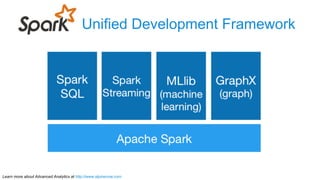
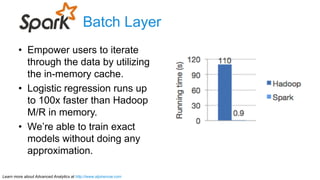
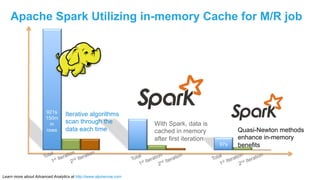
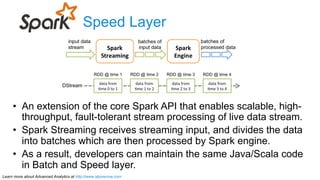




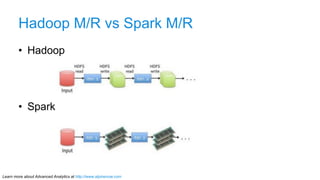







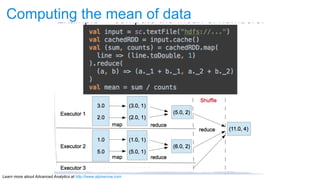





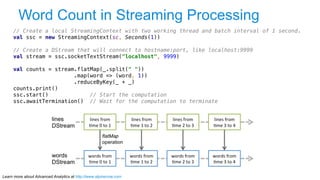


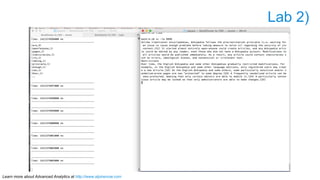




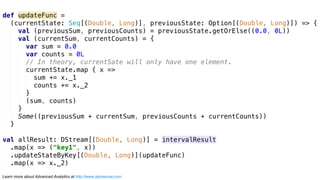

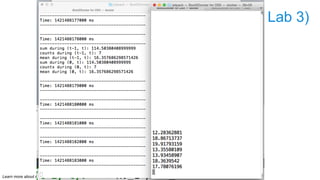
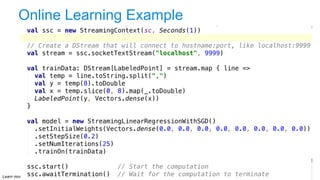


The document discusses advanced analytics, focusing on lambda architecture and the use of Apache Spark for batch and streaming data processing. It highlights the components of the lambda architecture (batch layer, speed layer, and serving layer) and compares traditional MapReduce with Spark's enhanced capabilities. Various machine learning techniques and features of Resilient Distributed Datasets (RDDs) are also covered, emphasizing the benefits of in-memory processing and fault-tolerance.












































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)









![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)






