













![24
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Welcome to
____ __
/ __/__ ___ _____/ /__
_ / _ / _ `/ __/ '_/
/___/ .__/_,_/_/ /_/_ version 1.1.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_45)
Type in expressions to have them evaluated.
Type :help for more information.
2014-09-07 22:31:21.064 java[1871:15527] Unable to load realm info from SCDynamicStore
14/09/07 22:31:21 WARN NativeCodeLoader: Unable to load native-hadoop library for your
platform... using builtin-java classes where applicable
Spark context available as sc.
scala> val receipt = sc.textFile("/usr/local/Cellar/workspace/data/receipt/receipt.txt")
receipt: org.apache.spark.rdd.RDD[String] =
/usr/local/Cellar/workspace/data/receipt/receipt.txt MappedRDD[1] at textFile at
<console>:12
scala> receipt.count
res0: Long = 30](https://image.slidesharecdn.com/sparkwebinar9-140925125814-phpapp01/75/The-Future-of-Hadoop-A-deeper-look-at-Apache-Spark-24-2048.jpg)
![25
scala> val words = receipt.flatMap(_.split(" "))
words: org.apache.spark.rdd.RDD[String] = FlatMappedRDD[2] at flatMap at <console>:14
scala> words.count
res1: Long = 161
scala> words.distinct.count
res2: Long = 72
scala> val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _).map{case(x,y) =>
(y,x)}.sortByKey(false).map{case(i,j) => (j, i)}
wordCounts: org.apache.spark.rdd.RDD[(String, Int)] = MappedRDD[12] at map at <console>:16
scala> wordCounts.take(12)
res5: Array[(String, Int)] = Array(("",82), (with,2), (Card,2), (new,2), (----------------
---------------,2), (Frappuccino(R),2), (roast,2), (1,2), (and,2), (New,1), (Topped,1),
(Starbucks,1))](https://image.slidesharecdn.com/sparkwebinar9-140925125814-phpapp01/75/The-Future-of-Hadoop-A-deeper-look-at-Apache-Spark-25-2048.jpg)








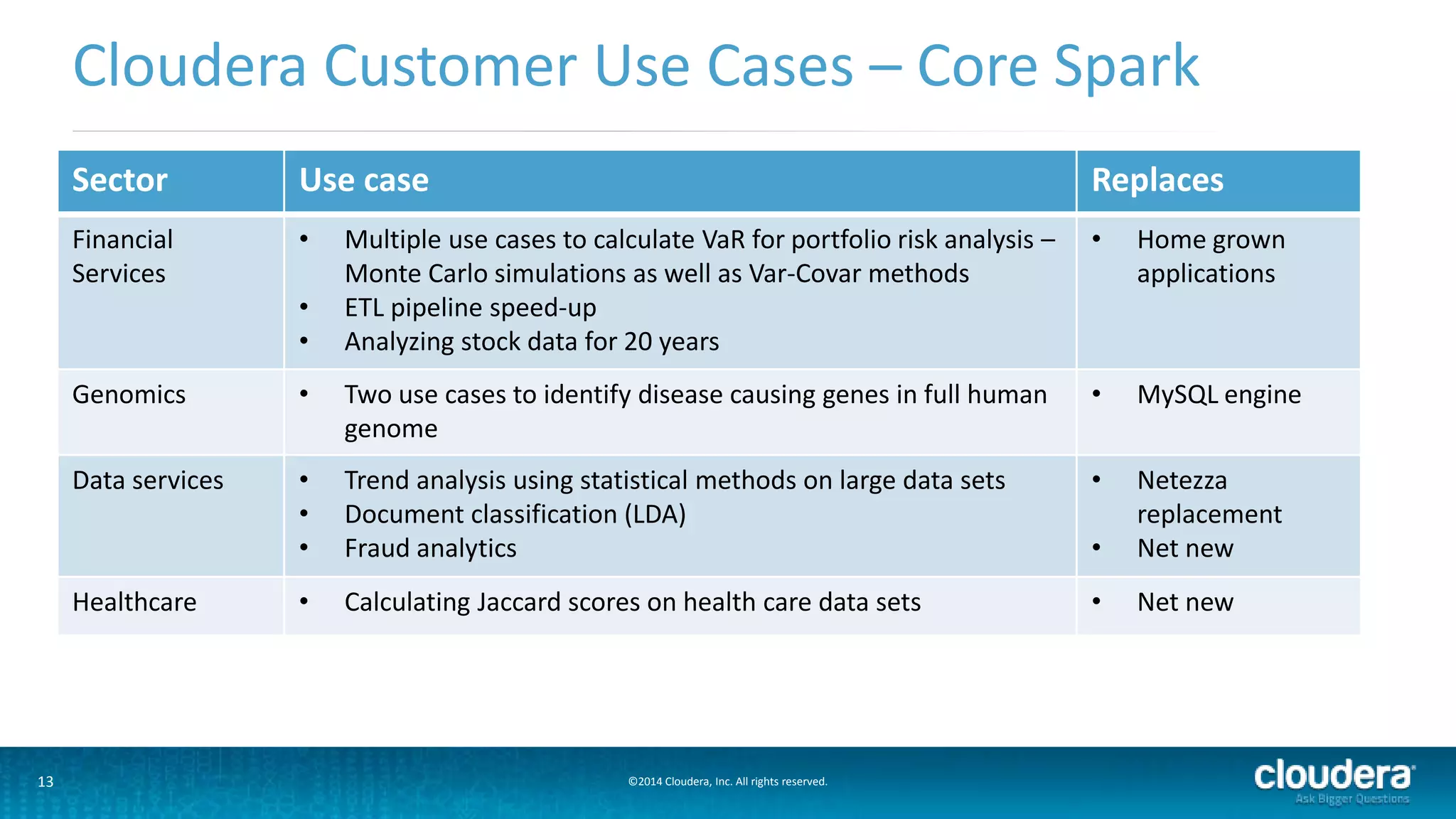
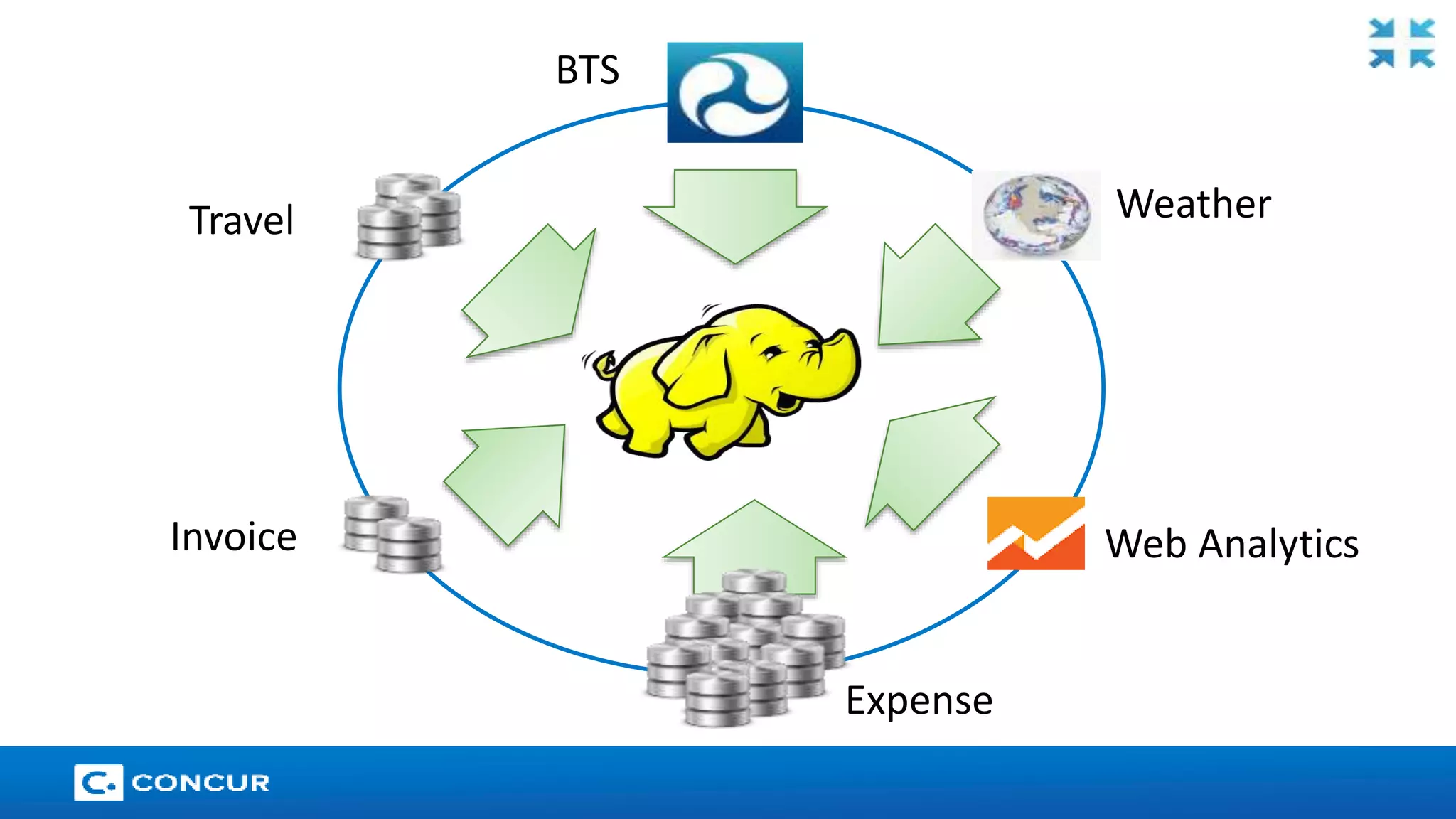
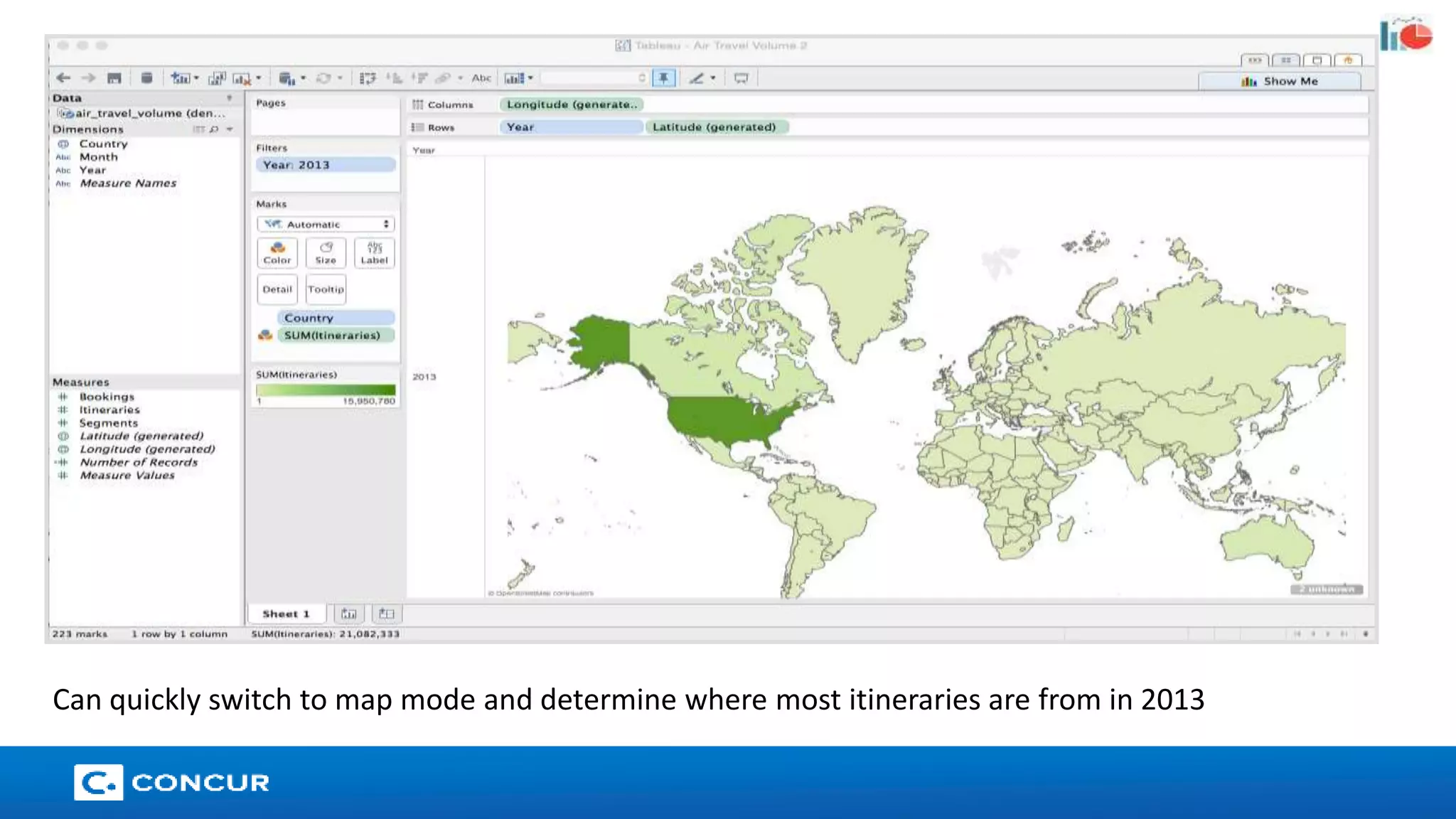
The document provides an overview of Cloudera's enterprise data hub and the advantages of using Apache Spark for big data processing, highlighting its speed, ease of development, and rich APIs. Key use cases include streaming analytics, machine learning, and applications within various industries such as finance and healthcare. The presentation also features a case study on how Concur leverages Spark for data management to enhance its spend management solutions.











































































































