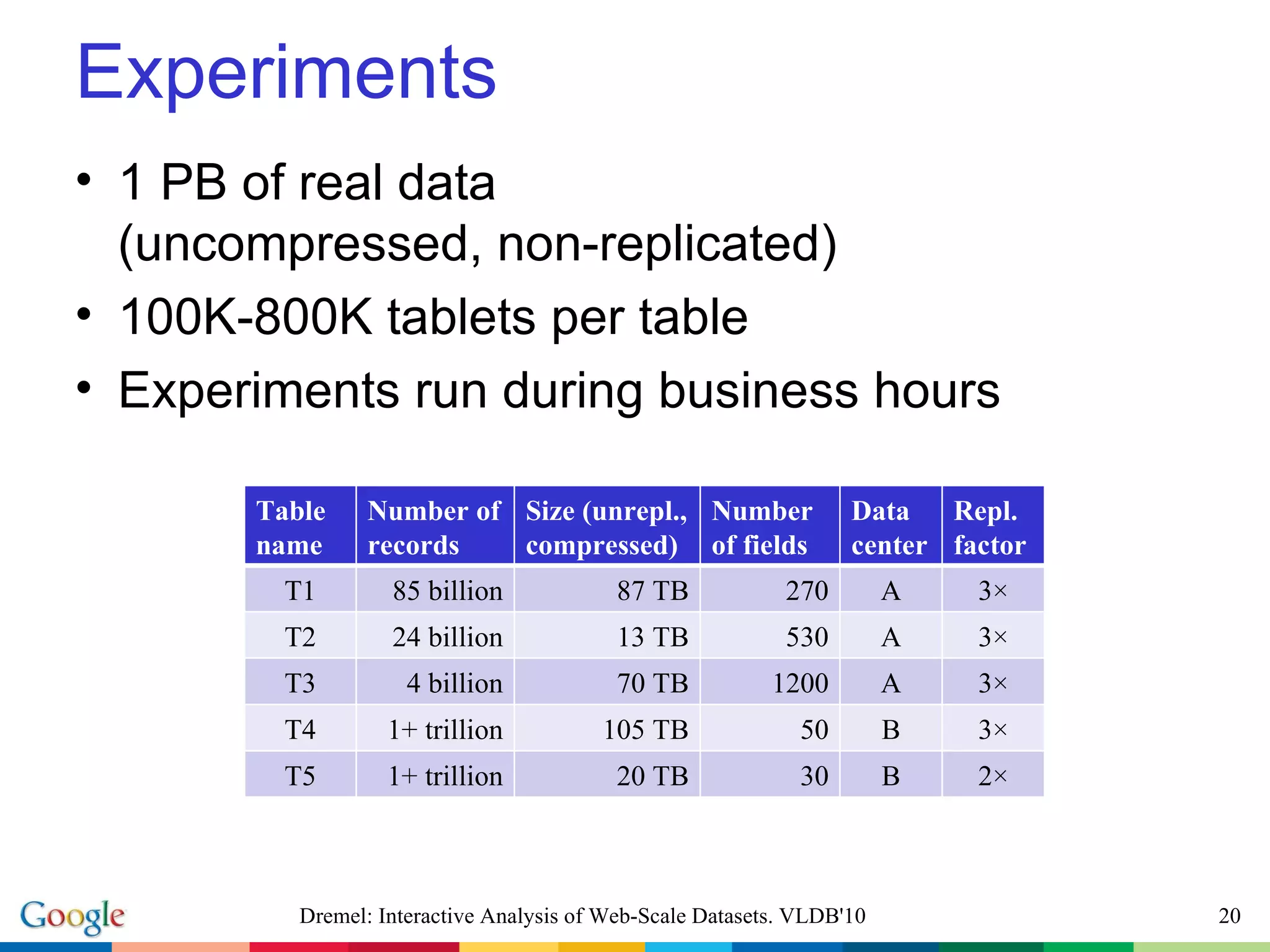
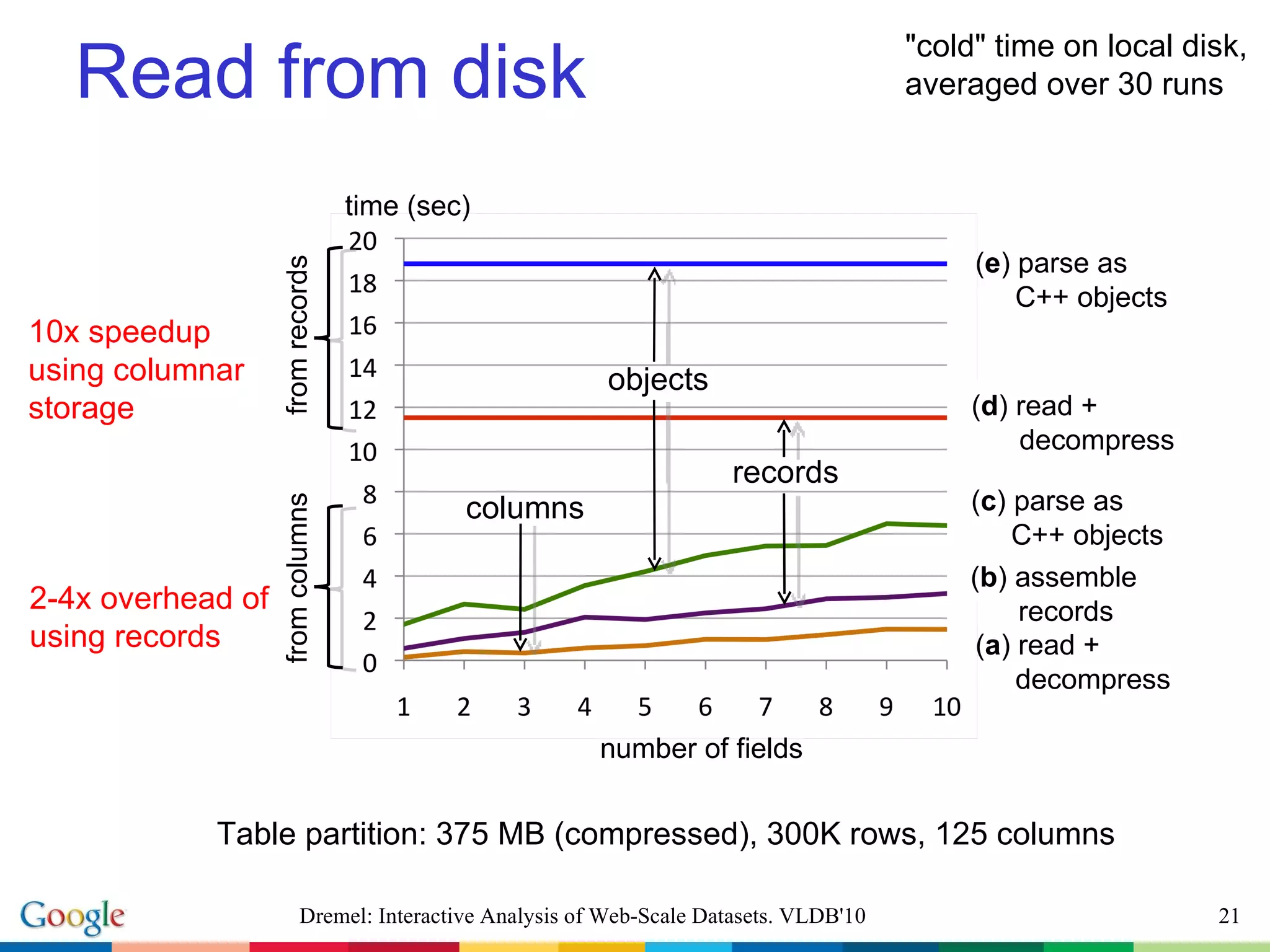
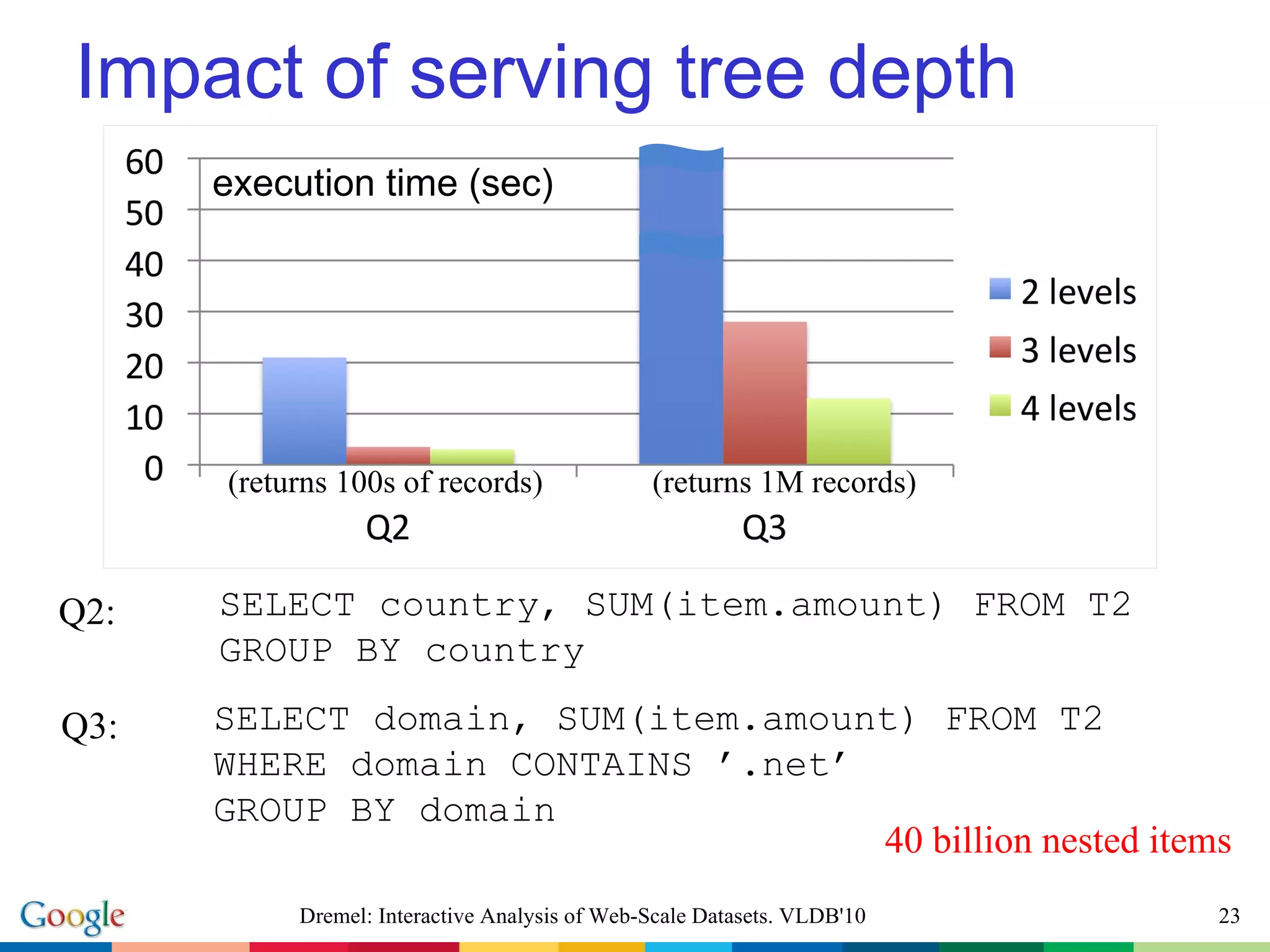
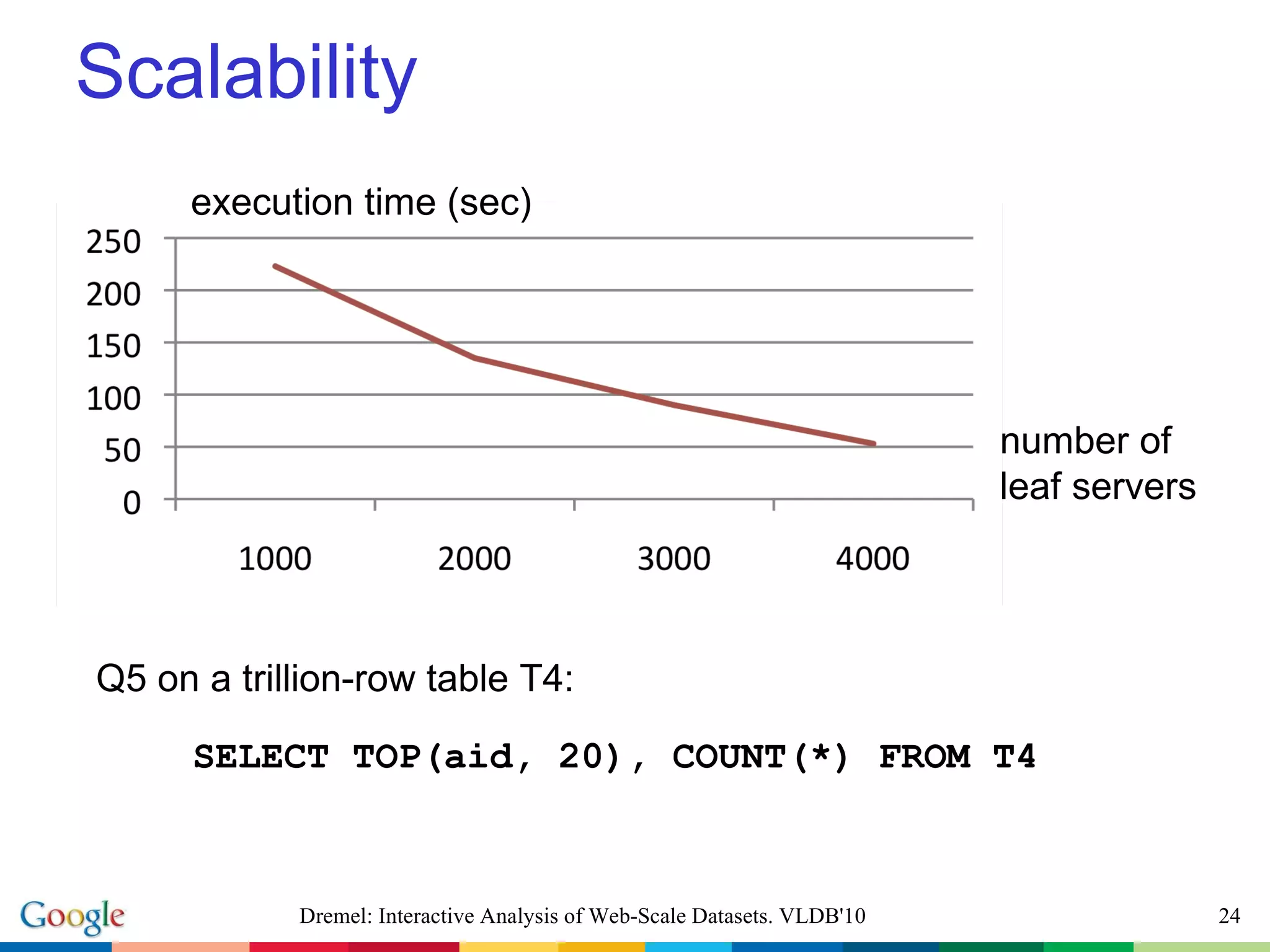
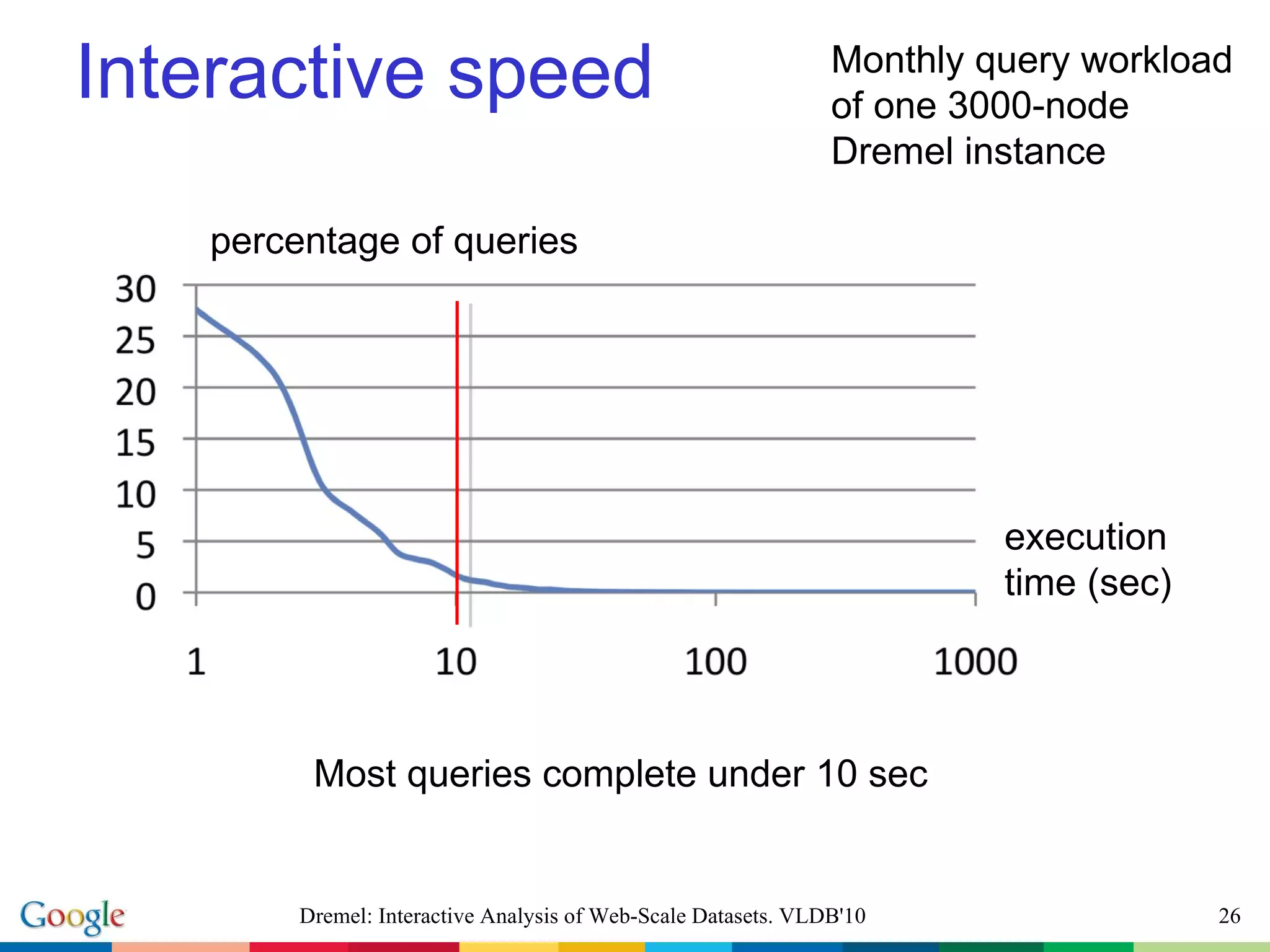
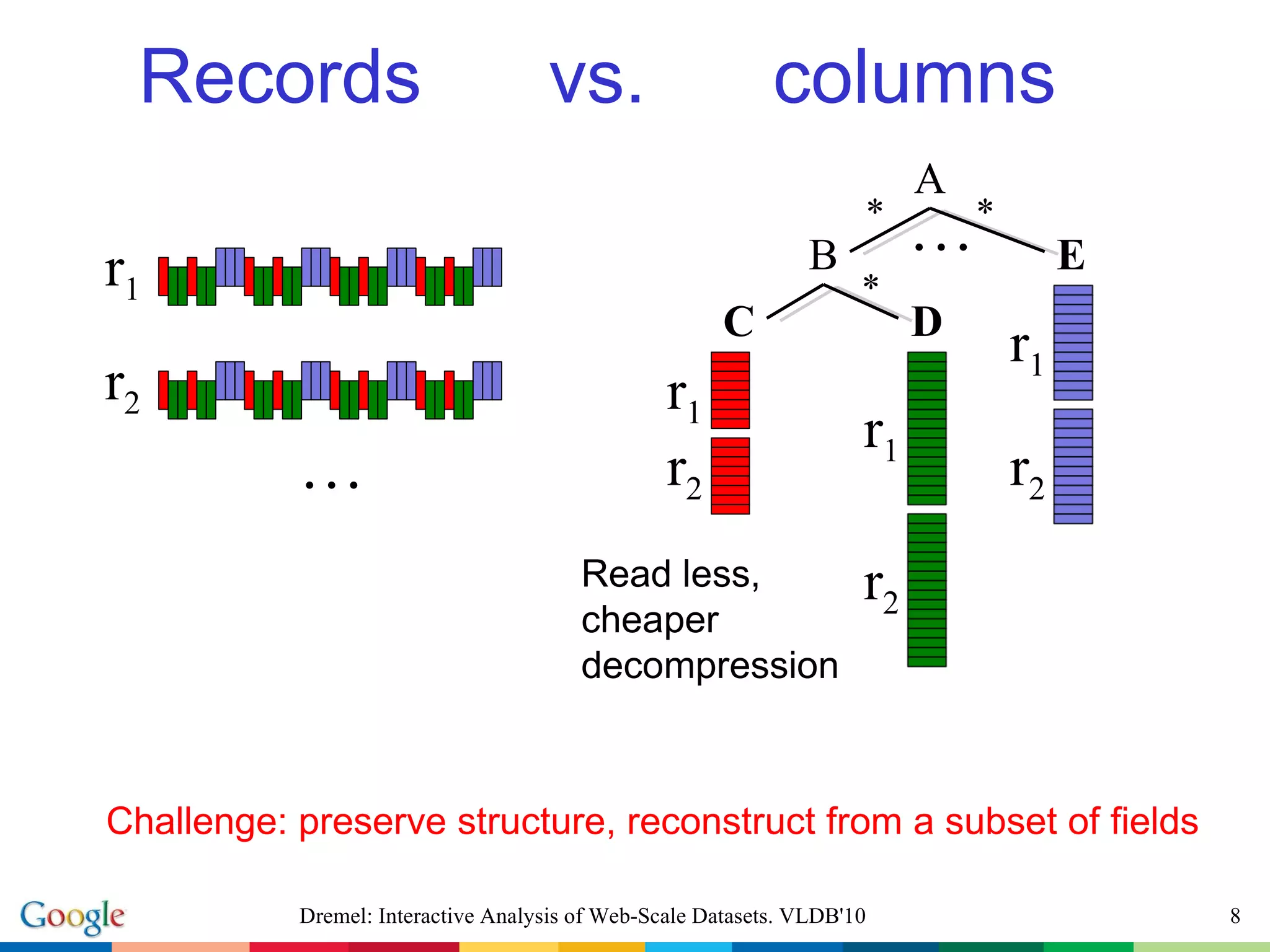
The document describes Dremel, an interactive analysis system for web-scale datasets. Dremel uses a columnar data storage model and tree-based query serving architecture to enable interactive analysis of trillion record datasets distributed across thousands of nodes. It provides an SQL-like interface and can process queries orders of magnitude faster than traditional MapReduce systems by avoiding record assembly costs. Experiments show Dremel can analyze tens to hundreds of billions of records interactively on commodity hardware.


![Example: data exploration Dremel: Interactive Analysis of Web-Scale Datasets. VLDB'10 Runs a MapReduce to extract billions of signals from web pages Googler Alice DEFINE TABLE t AS /path/to/data/* SELECT TOP(signal, 100), COUNT(*) FROM t . . . More MR-based processing on her data (FlumeJava [PLDI'10] , Sawzall [Sci.Pr.'05] ) 1 2 3 Ad hoc SQL against Dremel](https://image.slidesharecdn.com/melnikvldb10-101207064120-phpapp01/75/Dremel-Interactive-Analysis-of-Web-Scale-Datasets-3-2048.jpg)




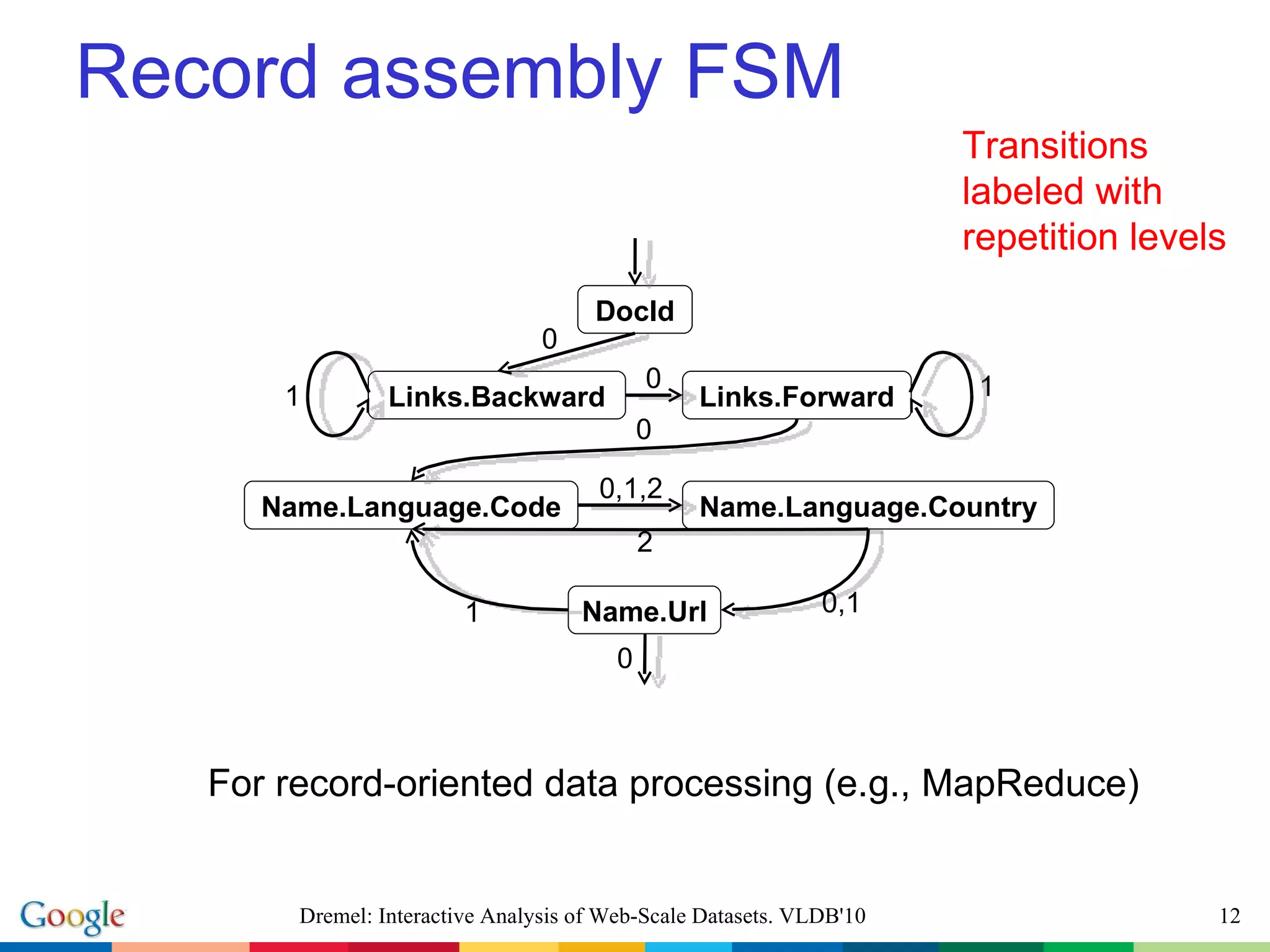
![Nested data model message Document { required int64 DocId; [1,1] optional group Links { repeated int64 Backward; [0,*] repeated int64 Forward; } repeated group Name { repeated group Language { required string Code; optional string Country; [0,1] } optional string Url; } } DocId: 10 Links Forward: 20 Forward: 40 Forward: 60 Name Language Code: 'en-us' Country: 'us' Language Code: 'en' Url: 'http://A' Name Url: 'http://B' Name Language Code: 'en-gb' Country: 'gb' r 1 DocId: 20 Links Backward: 10 Backward: 30 Forward: 80 Name Url: 'http://C' r 2 Dremel: Interactive Analysis of Web-Scale Datasets. VLDB'10 http://code.google.com/apis/protocolbuffers multiplicity:](https://image.slidesharecdn.com/melnikvldb10-101207064120-phpapp01/75/Dremel-Interactive-Analysis-of-Web-Scale-Datasets-9-2048.jpg)


![Reading two fields DocId Name.Language.Country 1,2 0 0 DocId: 10 Name Language Country: 'us' Language Name Name Language Country: 'gb' DocId: 20 Name s 1 s 2 Structure of parent fields is preserved. Useful for queries like /Name[3]/Language[1]/Country Dremel: Interactive Analysis of Web-Scale Datasets. VLDB'10 Both Dremel and MapReduce can read same columnar data](https://image.slidesharecdn.com/melnikvldb10-101207064120-phpapp01/75/Dremel-Interactive-Analysis-of-Web-Scale-Datasets-13-2048.jpg)



![Serving tree storage layer (e.g., GFS) . . . . . . . . . leaf servers (with local storage) intermediate servers root server client Parallelizes scheduling and aggregation Fault tolerance Stragglers Designed for "small" results (<1M records) Dremel: Interactive Analysis of Web-Scale Datasets. VLDB'10 [Dean WSDM'09] histogram of response times](https://image.slidesharecdn.com/melnikvldb10-101207064120-phpapp01/75/Dremel-Interactive-Analysis-of-Web-Scale-Datasets-17-2048.jpg)