Download as PDF, PPTX













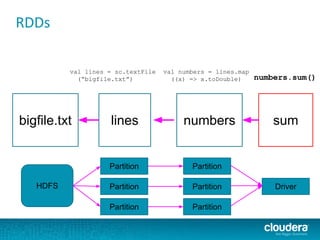

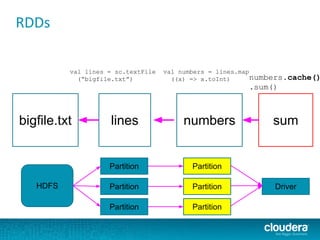
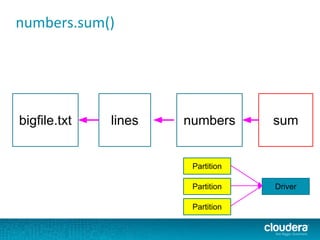










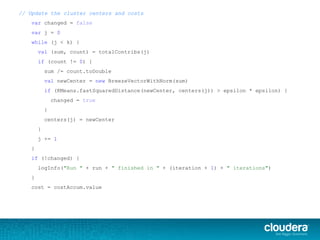
.asInstanceOf[BV[Double]])
val counts = Array.fill(k)(0L)
points.foreach { point =>
val (bestCenter, cost) = KMeans.findClosest(centers, point)
costAccum += cost
sums(bestCenter) += point.vector
counts(bestCenter) += 1
}
val contribs = for (j <- 0 until k) yield {
(j, (sums(j), counts(j)))
}
contribs.iterator
}.reduceByKey(mergeContribs).collectAsMap()](https://image.slidesharecdn.com/unsupervisedlearningwithsparkmllib-140505031133-phpapp01/85/Unsupervised-Learning-with-Apache-Spark-45-320.jpg)










![val data: RDD[Vector] = ...
val mat = new RowMatrix(data)
// compute the top 5 principal components
val principalComponents =
mat.computePrincipalComponents(5)
// project data into subspace
val transformed = data.map(_.toBreeze *
mat.toBreeze)](https://image.slidesharecdn.com/unsupervisedlearningwithsparkmllib-140505031133-phpapp01/85/Unsupervised-Learning-with-Apache-Spark-68-320.jpg)


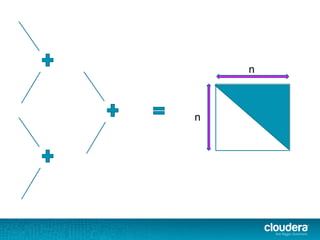
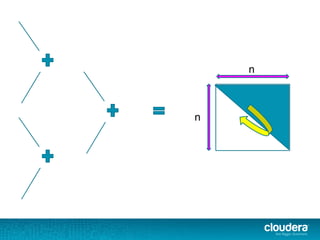
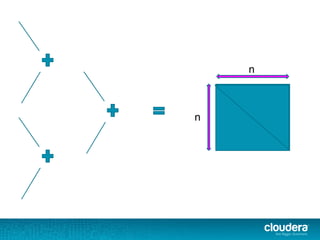
))(
seqOp = (U, v) => {
RowMatrix.dspr( 1.0, v, U.data)
U
},
combOp = (U1, U2) => U1 += U2
)
RowMatrix.triuToFull(n, GU.data)
}](https://image.slidesharecdn.com/unsupervisedlearningwithsparkmllib-140505031133-phpapp01/85/Unsupervised-Learning-with-Apache-Spark-77-320.jpg)



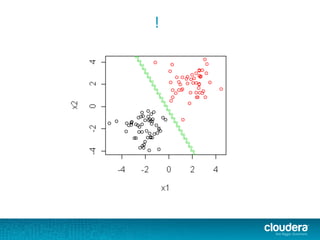
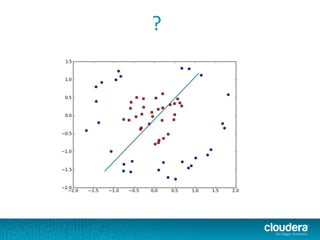
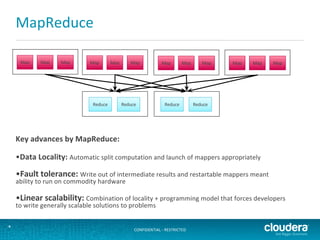
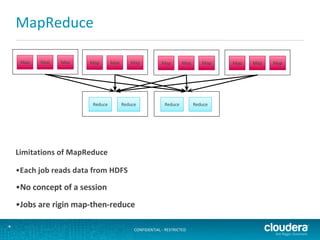
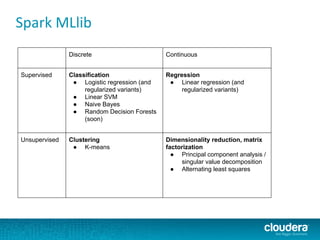
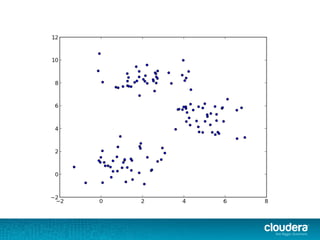
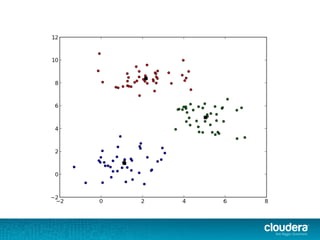
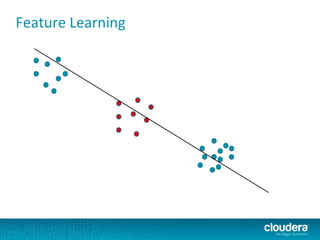
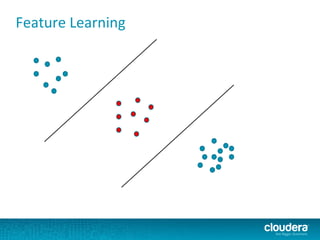
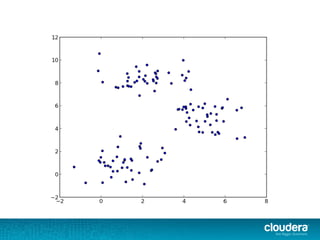
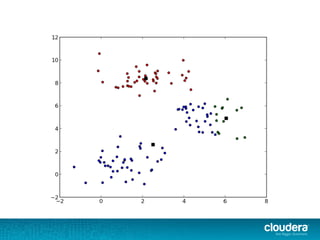
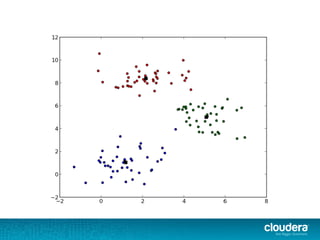
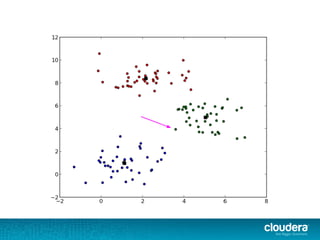
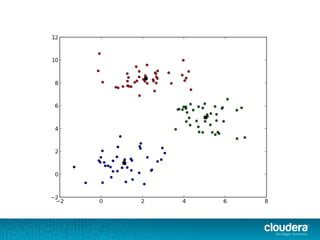
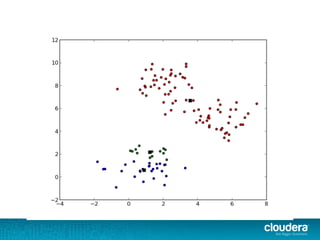
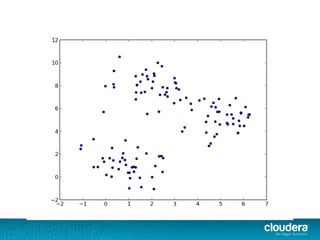
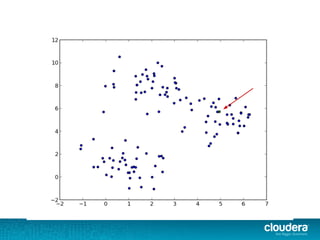
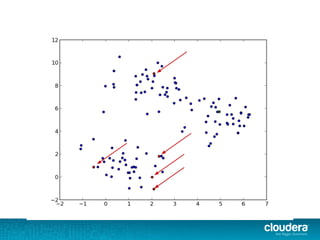
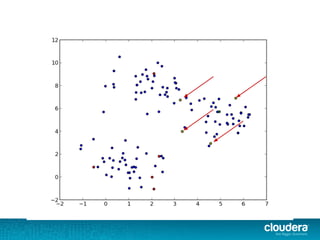
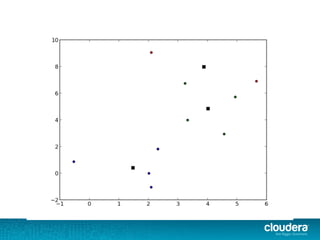
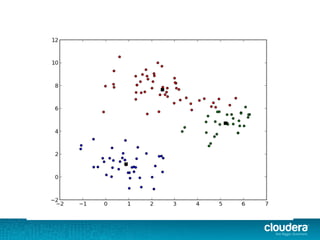
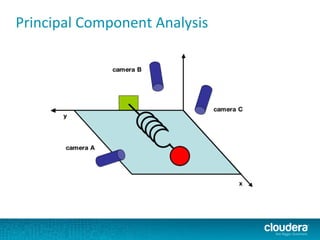
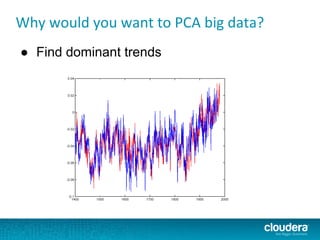
The document outlines the author's experience as a data scientist at Cloudera, focusing on developments in Apache Spark and Hadoop, as well as their academic background in combinatorial optimization and distributed systems. It discusses various data processing techniques, including clustering, dimensionality reduction, and algorithms for both supervised and unsupervised learning, notably k-means and principal component analysis. Additionally, it touches on challenges in choosing initial center points for k-means and introduces methods for feature learning and representation in high-dimensional data.






















































![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt2931-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt3441-thumbnail.jpg?width=640&height=640&fit=bounds)




















