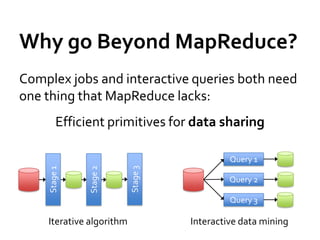
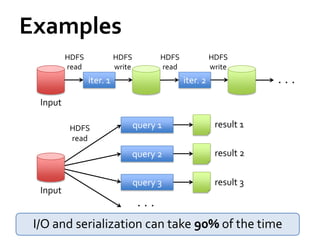
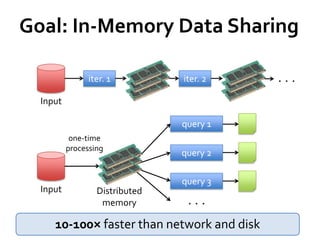
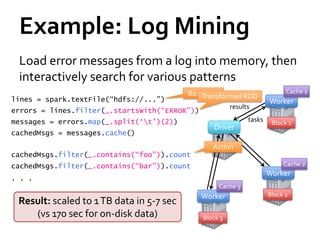
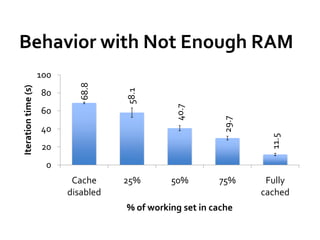
This document summarizes Spark, a fast and general engine for large-scale data processing. Spark addresses limitations of MapReduce by supporting efficient sharing of data across parallel operations in memory. Resilient distributed datasets (RDDs) allow data to persist across jobs for faster iterative algorithms and interactive queries. Spark provides APIs in Scala and Java for programming RDDs and a scheduler to optimize jobs. It integrates with existing Hadoop clusters and scales to petabytes of data.










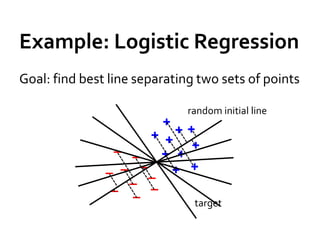

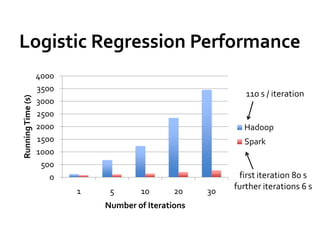

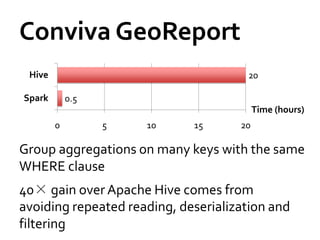
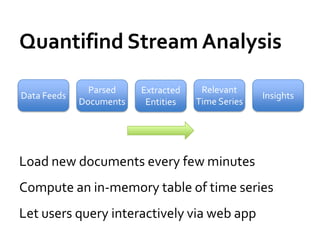

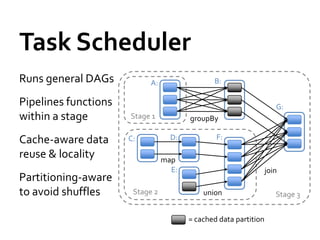



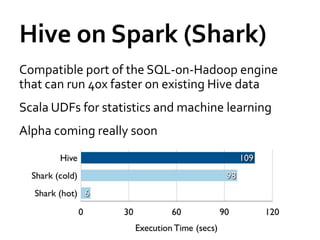
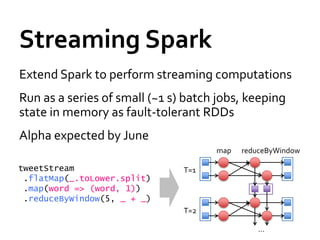






































![Fun[ctional] spark with scala](https://cdn.slidesharecdn.com/ss_thumbnails/functionalsparkwithscala-160614075814-thumbnail.jpg?width=640&height=640&fit=bounds)


































































