Downloaded 75 times




![7
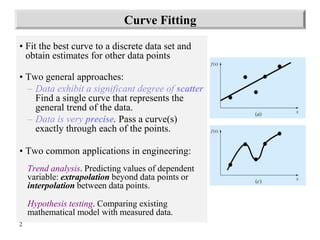
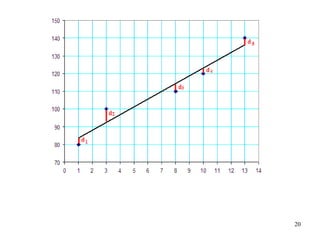
Least-Squares Fit of a Line
0
2 1
0
0
i
i
r
x
a
a
y
a
S
0
]
[
2 1
0
1
i
i
i
r
x
x
a
a
y
a
S
i
i y
a
x
na 1
0
To minimize Sr:
where and
2
2
1
i
i
i
i
i
i
x
x
n
y
x
y
x
n
a
i
i
i
i y
x
a
x
a
x 1
2
0
x
a
y
a 1
0
n
y
y i
n
x
x i
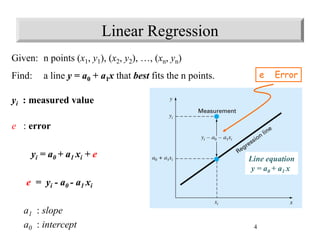
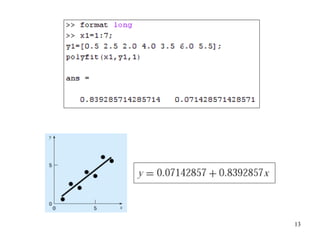
y = a0 + a1x
Mean values](https://image.slidesharecdn.com/appliednumericalmethodslec8-150507042330-lva1-app6891/85/Applied-numerical-methods-lec8-7-320.jpg)









![23
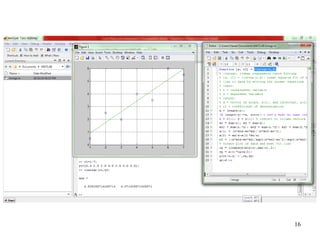
Polynomial Regression
)
1
(
m
n
S
s r
x
y /
2
1
2
2
1
0
n
i
m
i
m
i
i
i
r x
a
x
a
x
a
a
y
S ...
2
1
2
2
1
0
n
i
i
i
i
r x
a
x
a
a
y
S
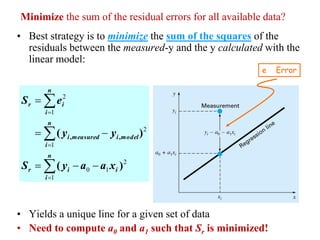
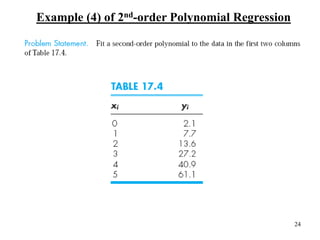
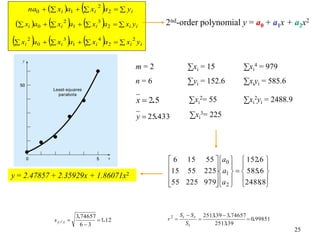
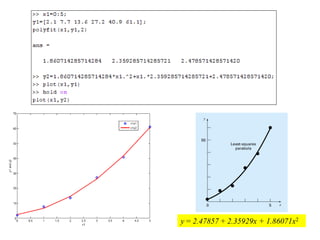
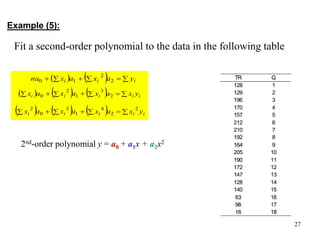
Given: n points (x1, y1), (x2, y2), …, (xn, yn)
Find: a polynomial y = a0 + a1x + a2x2 + … amxm that minimizes
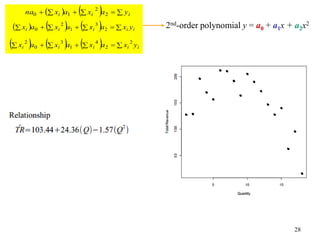
Example: 2nd-order polynomial y = a0 + a1x + a2x2
0
2 2
2
1
0
0
i
i
i
r
x
a
x
a
a
y
a
S
0
]
[
2 2
2
1
0
1
i
i
i
i
r
x
x
a
x
a
a
y
a
S
0
]
[
2
2
2
2
1
0
2
i
i
i
i
r
x
x
a
x
a
a
y
a
S
i
i
i y
a
x
a
x
na 2
2
1
0
i
i
i
i
i y
x
a
x
a
x
a
x 2
3
1
2
0
i
i
i
i
i y
x
a
x
a
x
a
x
2
2
4
1
3
0
2
Standard error:](https://image.slidesharecdn.com/appliednumericalmethodslec8-150507042330-lva1-app6891/85/Applied-numerical-methods-lec8-23-320.jpg)
![29
Multiple Linear Regression
0
]
[
2 2
2
2
1
1
0
2
i
i
i
i
r
x
x
a
x
a
a
y
a
S
2
1
2
2
1
1
0
n
i
i
i
i
r x
a
x
a
a
y
S
Given: n points 3D (y1, x11, x12) (y2, x12, x22), …, (yn, x1n, x2n)
Find: a plane y = a0 + a1x1 + a2x2 that minimizes
0
2 2
2
1
1
0
0
i
i
i
r
x
a
x
a
a
y
a
S
0
]
[
2 1
2
2
1
1
0
1
i
i
i
i
r
x
x
a
x
a
a
y
a
S
i
i
i y
a
x
a
x
na 2
2
1
1
0
i
i
i
i
i
i y
x
a
x
x
a
x
a
x 1
2
2
1
1
2
1
0
1
i
i
i
i
i
i y
x
a
x
a
x
x
a
x 2
2
2
2
1
2
1
0
2
Generation to m dimensions:
hyper plane y = a0 + a1x1 + a2x2 + … + amxm](https://image.slidesharecdn.com/appliednumericalmethodslec8-150507042330-lva1-app6891/85/Applied-numerical-methods-lec8-29-320.jpg)
![30
General Linear Least Squares
n
m
mn
n
n
m
m
n e
e
e
a
a
a
z
z
z
z
z
z
z
z
z
y
y
y
2
1
1
0
1
0
2
12
02
1
11
01
2
1
Linear least squares: y = a0 + a1x1
Multi-linear least squares: y = a0 + a1x1 + a2x2 + … + amxm
Polynomial least squares: y = a0 + a1x + a2x2 + … amxm
2
1 0
1
2
n
i
m
j
ji
j
i
n
i
i
r z
a
y
e
S
Y
Z
A
Z
Z
T
T
y = a0z0 + a1z1 + a2z2 + … + amzm
{Y} = [Z] {A} + {E}
[C] {A} = {D}
([C] is symmetric, e.g. linear and polynomial)](https://image.slidesharecdn.com/appliednumericalmethodslec8-150507042330-lva1-app6891/85/Applied-numerical-methods-lec8-30-320.jpg)

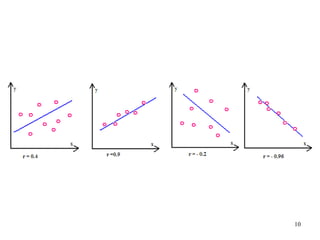
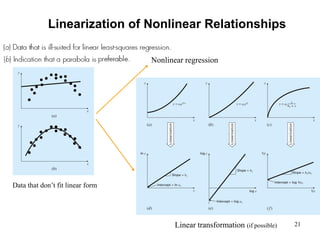
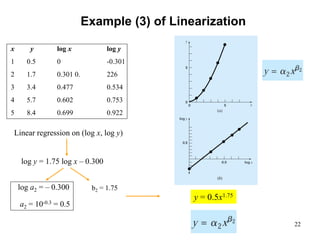
The document discusses various techniques for fitting curves to data including linear regression, polynomial regression, and linearization of nonlinear relationships. Linear regression finds the line that best fits a set of data points by minimizing the sum of the squared residuals. The normal equations are derived and solved to determine the slope and intercept. Polynomial regression extends this to find the best-fit polynomial curve through the data. An example shows fitting a second-order polynomial. Nonlinear relationships can sometimes be linearized by a transformation of variables to apply linear regression. Examples demonstrate applying these techniques.



































































































