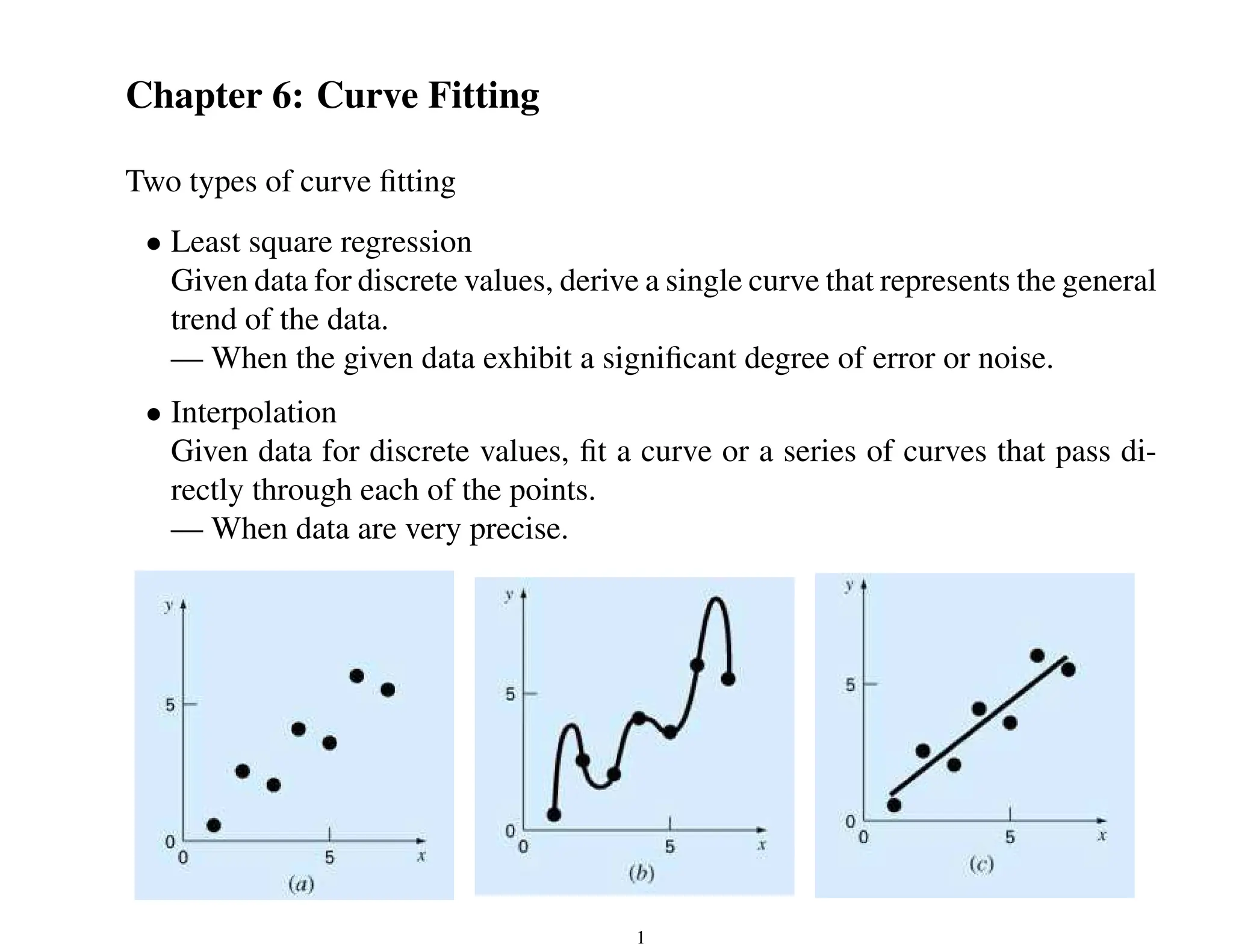
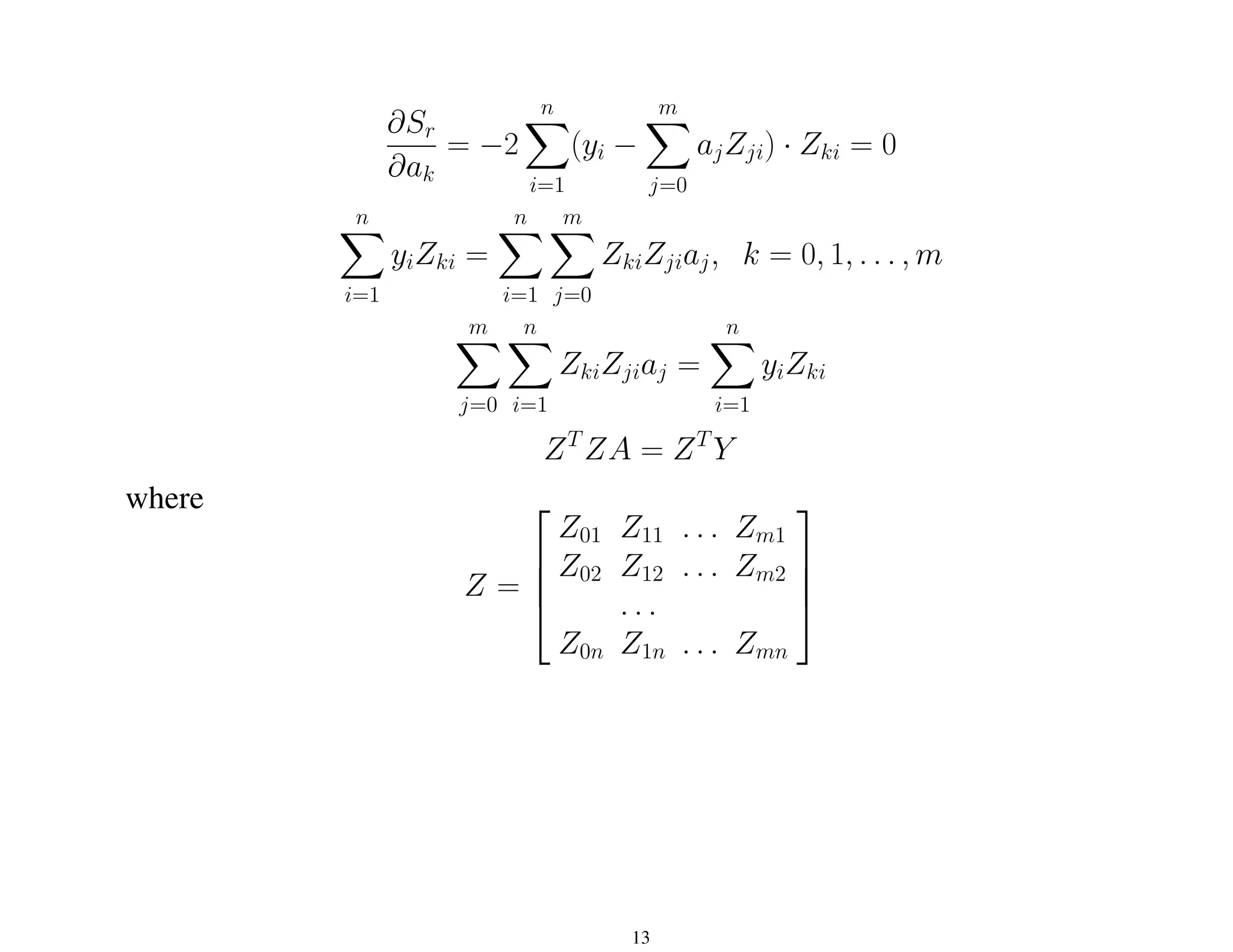
This document discusses techniques for curve fitting data, including least squares regression and interpolation. It covers:
- Two types of curve fitting: least squares regression to derive a trend line for noisy data, and interpolation to fit curves passing through precise data points.
- Linear regression to fit a straight line model and determine coefficients by minimizing the residual sum of squares.
- Polynomial regression to fit higher order polynomial models.
- Multiple linear regression to fit models with multiple independent variables.
- General linear least squares framework and normal equations to determine coefficients for any linear model.
- Polynomial interpolation to exactly fit curves through data points using divided differences.

![∂Sr
∂a0
= −2
n
X
i=1
(yi − a0 − a1xi) = 0 (1)
∂Sr
∂a1
= −2
n
X
i=1
[(yi − a0 − a1xi)xi] = 0 (2)
From (1),
Pn
i=1 yi −
Pn
i=1 a0 −
Pn
i=1 a1xi = 0, or
na0 +
n
X
i=1
xia1 =
n
X
i=1
yi (3)
From (2),
Pn
i=1 xiyi −
Pn
i=1 a0xi −
Pn
i=1 a1x2
i = 0, or
n
X
i=1
xia0 +
n
X
i=1
x2
i a1 =
n
X
i=1
xiyi (4)
(3) and (4) are called normal equations.
From (3),
a0 =
1
n
n
X
i=1
yi −
1
n
n
X
i=1
xia1 = ȳ − x̄a1
where x̄ = 1
n
Pn
i=1 xi, ȳ = 1
n
Pn
i=1 yi.
3](https://image.slidesharecdn.com/part5-240215041022-75b7a208/75/curve-fitting-lecture-slides-February-24-3-2048.jpg)



![∂Sr
∂a0
= −2
n
X
i=1
(yi − a0 − a1xi − a2x2
i ) = 0 (1)
∂Sr
∂a1
= −2
n
X
i=1
[(yi − a0 − a1xi − a2x2
i )xi] = 0 (2)
∂Sr
∂a2
= −2
n
X
i=1
[(yi − a0 − a1xi − a2x2
i )x2
i ] = 0 (3)
From (1),
Pn
i=1 yi −
Pn
i=1 a0 −
Pn
i=1 a1xi −
Pn
i=1 a2x2
i = 0, or
na0 +
n
X
i=1
xia1 +
n
X
i=1
x2
i a2 =
n
X
i=1
yi (1
0
)
From (2),
Pn
i=1 xiyi −
Pn
i=1 a0xi −
Pn
i=1 a1x2
i −
Pn
i=1 x3
i a2 = 0, or
n
X
i=1
xia0 +
n
X
i=1
x2
i a1 +
n
X
i=1
x3
i a2 =
n
X
i=1
xiyi (2
0
)
From (3),
Pn
i=1 x2
i yi −
Pn
i=1 a0x2
i −
Pn
i=1 a1x3
i −
Pn
i=1 x4
i a2 = 0, or
n
X
i=1
x2
i a0 +
n
X
i=1
x3
i a1 +
n
X
i=1
x4
i a2 =
n
X
i=1
x2
i yi (3
0
)
9](https://image.slidesharecdn.com/part5-240215041022-75b7a208/75/curve-fitting-lecture-slides-February-24-9-2048.jpg)

![∂Sr
∂a0
= −2
n
X
i=1
(yi − a0 − a1x1i − a2x2i) = 0 (1)
∂Sr
∂a1
= −2
n
X
i=1
[(yi − a0 − a1x1i − a2x2i)x1i] = 0 (2)
∂Sr
∂a2
= −2
n
X
i=1
[(yi − a0 − a1x1i − a2x2i)x2i] = 0 (3)
From (1), na0 +
Pn
i=1 x1ia1 +
Pn
i=1 x2ia2 =
Pn
i=1 yi (1
0
)
From (2),
Pn
i=1 x1ia0 +
Pn
i=1 x2
1ia1 +
Pn
i=1 x1ix2ia2 =
Pn
i=1 x1iyi (2
0
)
From (3),
Pn
i=1 x2ia0 +
Pn
i=1 x1ix2ia1 +
Pn
i=1 x2
2ia2 =
Pn
i=1 x2iyi (3
0
)
n
P
x1i
P
x2i
P
x1i
P
x2
1i
P
x1ix2i
P
x2i
P
x1ix2i
P
x2
2i
a0
a1
a2
=
P
yi
P
x1iyi
P
x2iyi
Standard error: Sy/x =
q
Sr
n−(m+1)
11](https://image.slidesharecdn.com/part5-240215041022-75b7a208/75/curve-fitting-lecture-slides-February-24-11-2048.jpg)



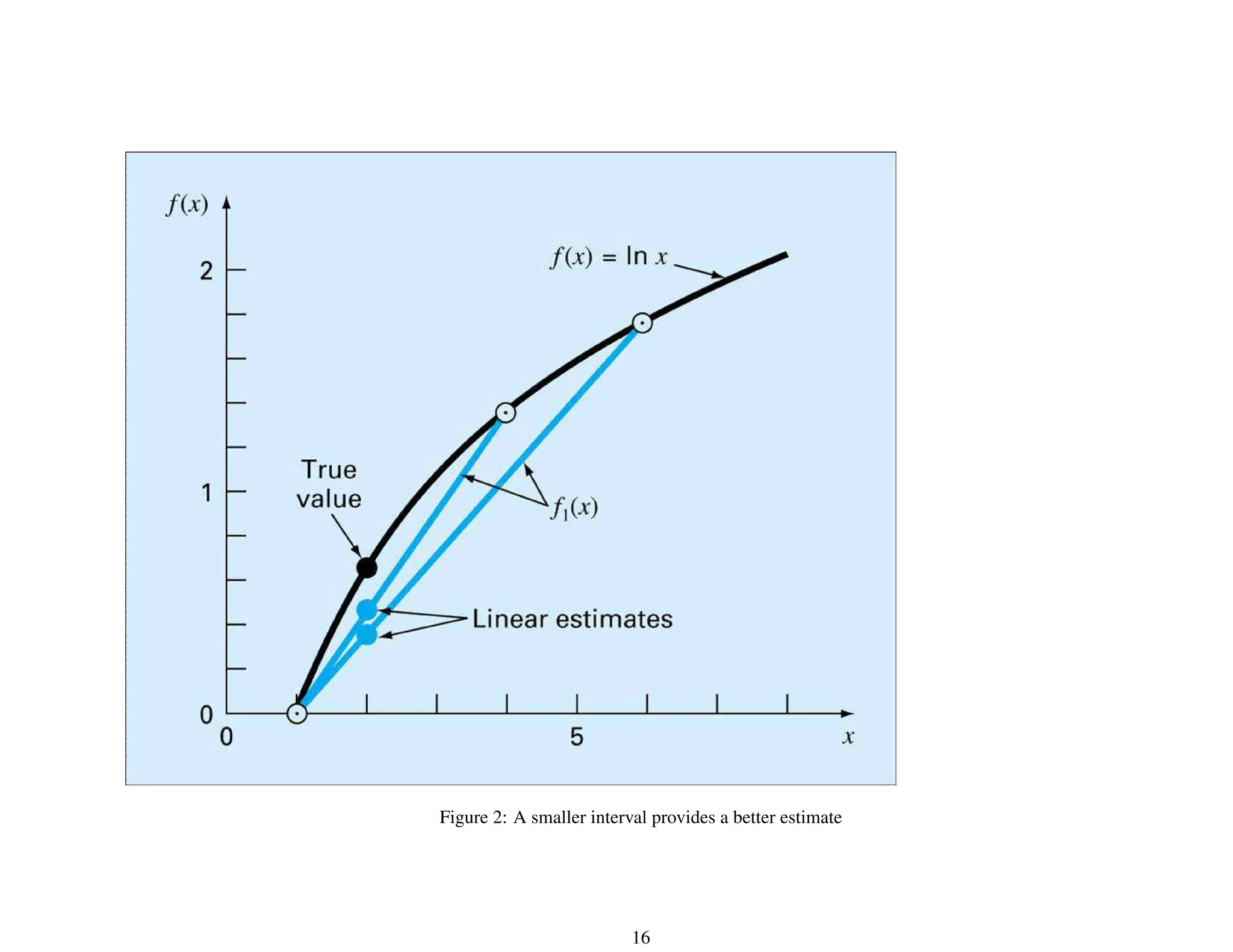


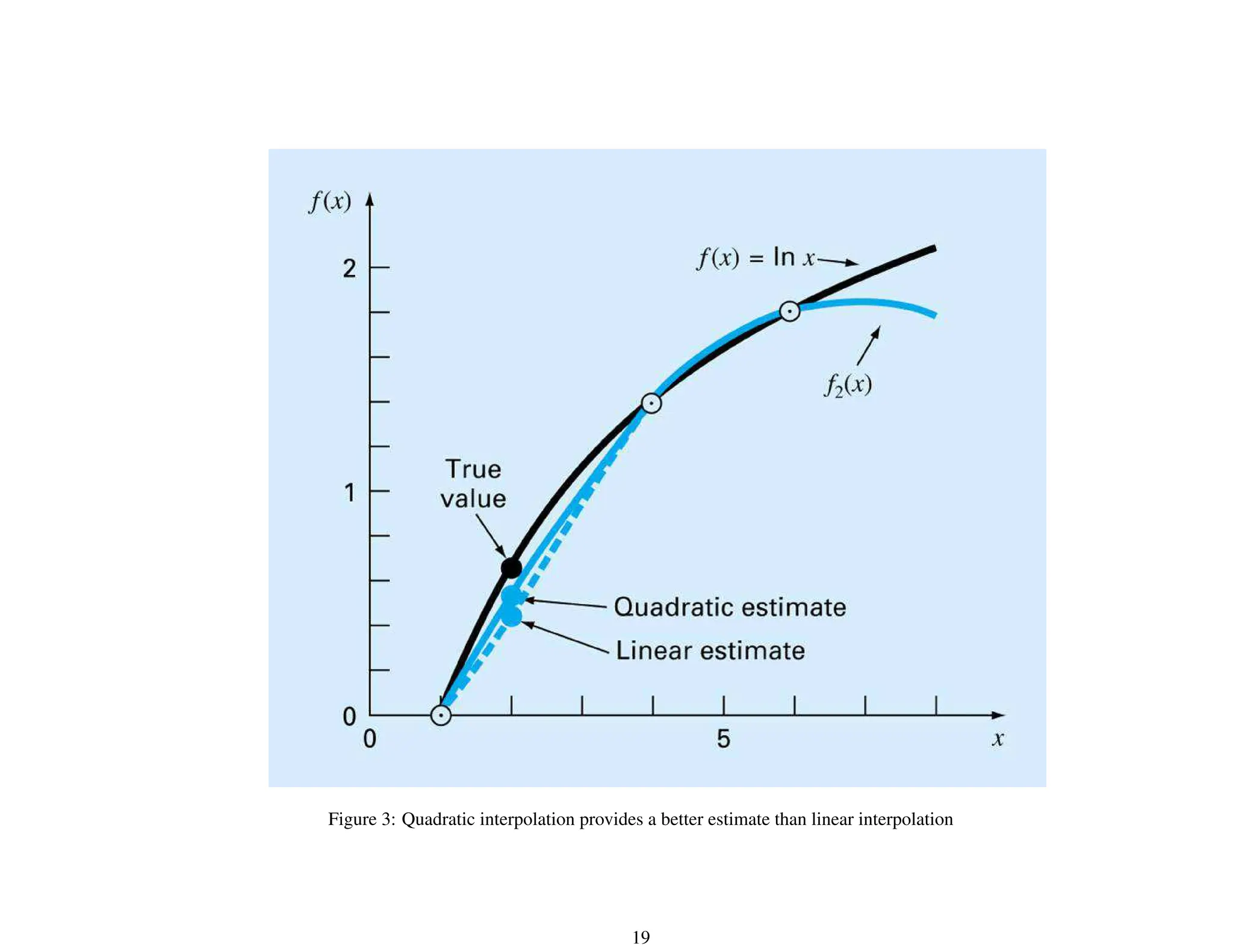

![General Form of Newton’s Interpolating Polynomial
Given (n + 1) data points, (xi, yi), i = 0, 1, . . . , n, fit an n-th order polynomial
fn(x) = b0 +b1(x−x0)+. . .+bn(x−x0)(x−x1) . . . (x−xn) =
n
X
i=0
bi
i−1
Y
j=0
(x−xj)
find b0, b1, . . . , bn.
x = x0, y0 = b0 or b0 = y0.
x = x1, y1 = b0 + b1(x1 − x0), then b1 = y1−y0
x1−x0
Define b1 = f[x1, x0] = y1−y0
x1−x0
.
x = x2, y2 = b0 + b1(x2 − x0) + b2(x2 − x0)(x2 − x1), then b2 =
y2−y1
x2−x1
−
y1−y0
x1−x0
x2−x0
Define f[x2, x1, x0] = f[x2,x1]−f[x1,x0]
x2−x0
, then b2 = f[x2, x1, x0].
. . .
x = xn, bn = f[xn, xn−1, . . . , x1, x0] = f[xn,xn−1,...,x1]−f[xn−1,...,x1,x0]
xn−x0
21](https://image.slidesharecdn.com/part5-240215041022-75b7a208/75/curve-fitting-lecture-slides-February-24-21-2048.jpg)


![f2(2.6) = −0.12 × 2.7183 + 0.64 × 7.3891 + 0.48 × 20.08853 = 14.0439
(2) use Newton’s interpolation
f2(x) = b0 + b1(x − x1) + b2(x − x1)(x − x2)
b0 = y1 = 2.7183
b1 = y2−y1
x2−x1
= 7.3891−2.7183
2−1 = 4.6708
b2 =
y2−y1
x2−x1
−
y1−y0
x1−x0
x2−x0
=
20.0855−7.3891
3−2 −4.6708
3−1 = 4.0128
f2(2.6) = 2.7183 + 4.6708 × (2.6 − 1) + 4.0128 × (2.6 − 1)(2.6 − 2) = 14.0439
(3) Use the straightforward method
f2(x) = a0 + a1x + a2x2
a0 + a1 + a2 × 12
= 2.7183
a0 + a1 + a2 × 22
= 7.3891
a0 + a1 + a2 × 32
= 20.0855
or
1 1 1
1 2 4
1 3 9
a0
a1
a2
=
2.7183
7.3891
20.0855
[a0 a1 a2]
0
= [6.0732; −7.3678 4.0129]
0
24](https://image.slidesharecdn.com/part5-240215041022-75b7a208/75/curve-fitting-lecture-slides-February-24-24-2048.jpg)

![
4 3.1781 10
3.1781 3.6092 10.2273
10 10.2273 30
a0
a1
a2
=
7.0213
6.2636
19.0280
[a0 a1 a2]
0
= [7.0213 6.2636 19.0280]
0
a = ea0 = 1.2332, b = a1 = −1.4259, c = a2 = 1.0505, and
y = axb
ecx
= 1.2332 · x−1.4259
· e1.0505x
.
26](https://image.slidesharecdn.com/part5-240215041022-75b7a208/75/curve-fitting-lecture-slides-February-24-26-2048.jpg)